A Survey on Self-play Methods in Reinforcement Learning
作者: Ruize Zhang, Zelai Xu, Chengdong Ma, Chao Yu, Wei-Wei Tu, Wenhao Tang, Shiyu Huang, Deheng Ye, Wenbo Ding, Yaodong Yang, Yu Wang
分类: cs.AI
发布日期: 2024-08-02 (更新: 2025-10-18)
💡 一句话要点
综述性研究:全面解析强化学习中自博弈方法的原理、应用与未来方向
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自博弈 强化学习 多智能体 博弈论 综述 非合作博弈 策略迭代
📋 核心要点
- 多智能体强化学习中自博弈方法应用广泛,但在理论理解和系统性分类上存在不足。
- 本文构建了统一的自博弈框架,对现有算法进行分类,并分析其在不同非合作场景中的作用。
- 该综述总结了自博弈领域面临的挑战,并为未来的研究方向提供了指导。
📝 摘要(中文)
自博弈是一种学习范式,其中智能体通过与自身或其它不断演化的智能体的历史或并发版本进行交互,迭代地改进其策略。自博弈在解决复杂的非合作多智能体任务中表现出了卓越的成功,例如围棋、扑克和视频游戏。尽管它在多智能体强化学习(MARL)中日益突出,但对自博弈的全面和结构化的理解仍然缺乏。本综述通过提供自博弈方法多样化景象的全面路线图来填补这一空白。首先介绍必要的预备知识,包括MARL框架和基本博弈论概念。然后,提供一个统一的框架,并在该框架内对现有的自博弈算法进行分类。此外,本文通过说明自博弈在不同非合作场景中的作用,弥合了算法与其实际应用之间的差距。最后,本综述强调了自博弈中存在的开放性挑战和未来的研究方向。
🔬 方法详解
问题定义:现有的多智能体强化学习(MARL)研究中,自博弈方法虽然取得了显著成果,但在理论层面缺乏统一的框架,导致难以系统性地理解和比较不同的自博弈算法。此外,算法与实际应用场景的联系不够紧密,阻碍了自博弈方法在更广泛领域的应用。
核心思路:本文旨在通过构建一个统一的自博弈框架,对现有算法进行分类,并分析其在不同非合作场景中的作用,从而弥合理论与实践之间的差距。该框架将有助于研究人员更好地理解自博弈的本质,并为未来的算法设计提供指导。
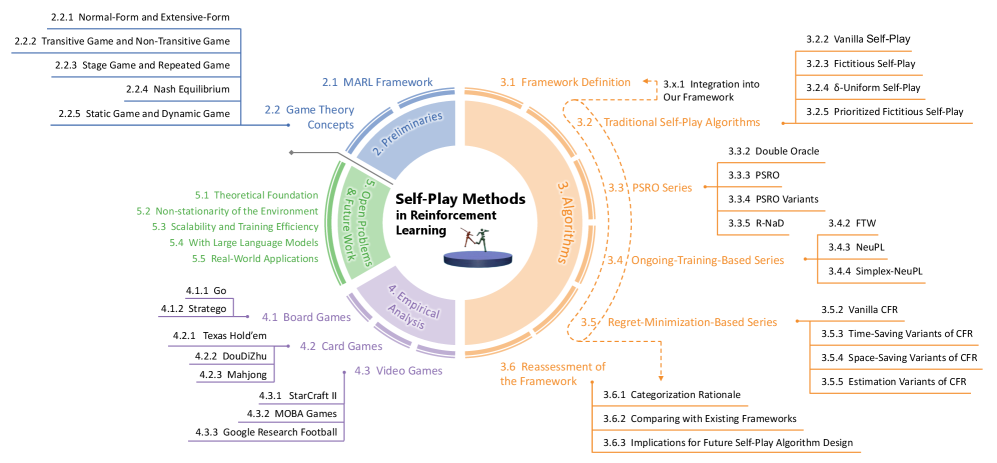
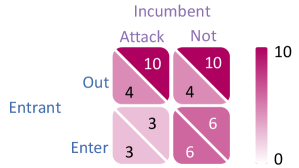
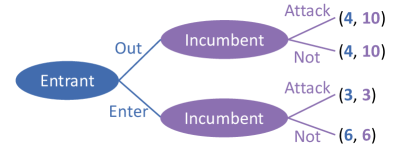
技术框架:该综述首先介绍了多智能体强化学习(MARL)的基本概念和博弈论基础。然后,提出了一个统一的自博弈框架,该框架可能包含以下几个关键模块:智能体策略生成模块、对手策略选择模块、交互环境模拟模块和策略评估与更新模块。基于此框架,对现有的自博弈算法进行分类,并分析其优缺点。
关键创新:本文的关键创新在于提出了一个统一的自博弈框架,该框架能够涵盖现有的各种自博弈算法,并为未来的算法设计提供指导。该框架的提出有助于研究人员更好地理解自博弈的本质,并促进该领域的发展。
关键设计:由于是综述文章,没有具体的参数设置、损失函数或网络结构等技术细节。但是,统一框架的设计是关键,需要考虑如何抽象出不同自博弈算法的共性特征,并将其纳入框架中。此外,对现有算法的分类标准也至关重要,需要选择合适的维度进行划分,例如对手策略的生成方式、策略评估方法等。
🖼️ 关键图片
📊 实验亮点
该综述全面梳理了自博弈方法在强化学习中的应用,构建了统一的框架,并对现有算法进行了分类。虽然没有提供具体的实验数据,但其对现有方法的总结和未来方向的展望,为相关领域的研究人员提供了宝贵的参考。
🎯 应用场景
自博弈方法在游戏AI、机器人控制、自动驾驶、金融交易等领域具有广泛的应用前景。通过与自身或其他智能体进行博弈,智能体可以不断提升自身的能力,从而在复杂环境中取得更好的表现。该研究有助于推动自博弈方法在更多实际场景中的应用。
📄 摘要(原文)
Self-play, a learning paradigm where agents iteratively refine their policies by interacting with historical or concurrent versions of themselves or other evolving agents, has shown remarkable success in solving complex non-cooperative multi-agent tasks. Despite its growing prominence in multi-agent reinforcement learning (MARL), such as Go, poker, and video games, a comprehensive and structured understanding of self-play remains lacking. This survey fills this gap by offering a comprehensive roadmap to the diverse landscape of self-play methods. We begin by introducing the necessary preliminaries, including the MARL framework and basic game theory concepts. Then, it provides a unified framework and classifies existing self-play algorithms within this framework. Moreover, the paper bridges the gap between the algorithms and their practical implications by illustrating the role of self-play in different non-cooperative scenarios. Finally, the survey highlights open challenges and future research directions in self-play.