ArchCode: Incorporating Software Requirements in Code Generation with Large Language Models
作者: Hojae Han, Jaejin Kim, Jaeseok Yoo, Youngwon Lee, Seung-won Hwang
分类: cs.SE, cs.AI, cs.CL
发布日期: 2024-08-02
备注: Accepted by ACL 2024 main conference
💡 一句话要点
ArchCode:利用大语言模型将软件需求融入代码生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大语言模型 软件需求 上下文学习 非功能性需求 自动化测试 HumanEval-NFR
📋 核心要点
- 现有代码生成方法难以从文本描述中提取和管理全面的软件需求,包括功能性和非功能性需求。
- ARCHCODE利用上下文学习组织文本描述中的需求,并推断未明确表达的需求,从而生成更全面的需求集。
- 实验结果表明,ARCHCODE在满足功能性需求方面显著提升了Pass@k分数,并在HumanEval-NFR基准测试中优于其他方法。
📝 摘要(中文)
本文旨在扩展大语言模型(LLM)的代码生成能力,使其能够自动管理给定文本描述中的全面软件需求。这些需求包括功能性需求(即,针对输入的预期行为)和非功能性需求(例如,时间/空间性能、鲁棒性、可维护性)。然而,文本描述可能冗长地表达需求,甚至省略某些需求。我们提出了ARCHCODE,一种新颖的框架,它利用上下文学习来组织描述中观察到的需求,并从中推断出未表达的需求。ARCHCODE从给定的描述中生成需求,并以此为条件来生成代码片段和测试用例。每个测试用例都针对一个需求量身定制,从而可以根据代码片段的执行结果与需求的符合程度对其进行排序。公共基准测试表明,ARCHCODE增强了满足功能性需求的能力,显著提高了Pass@k分数。此外,我们引入了HumanEval-NFR,这是首次评估LLM在代码生成中非功能性需求的基准,证明了ARCHCODE优于基线方法。ARCHCODE的实现和HumanEval-NFR基准都是公开可用的。
🔬 方法详解
问题定义:现有的大语言模型在代码生成时,难以充分理解和满足软件需求文档中隐含的或未明确表达的功能性和非功能性需求。现有的方法通常依赖于直接将需求文档输入模型,但忽略了需求之间的关联以及潜在的缺失需求,导致生成的代码质量不高,难以满足实际应用的需求。
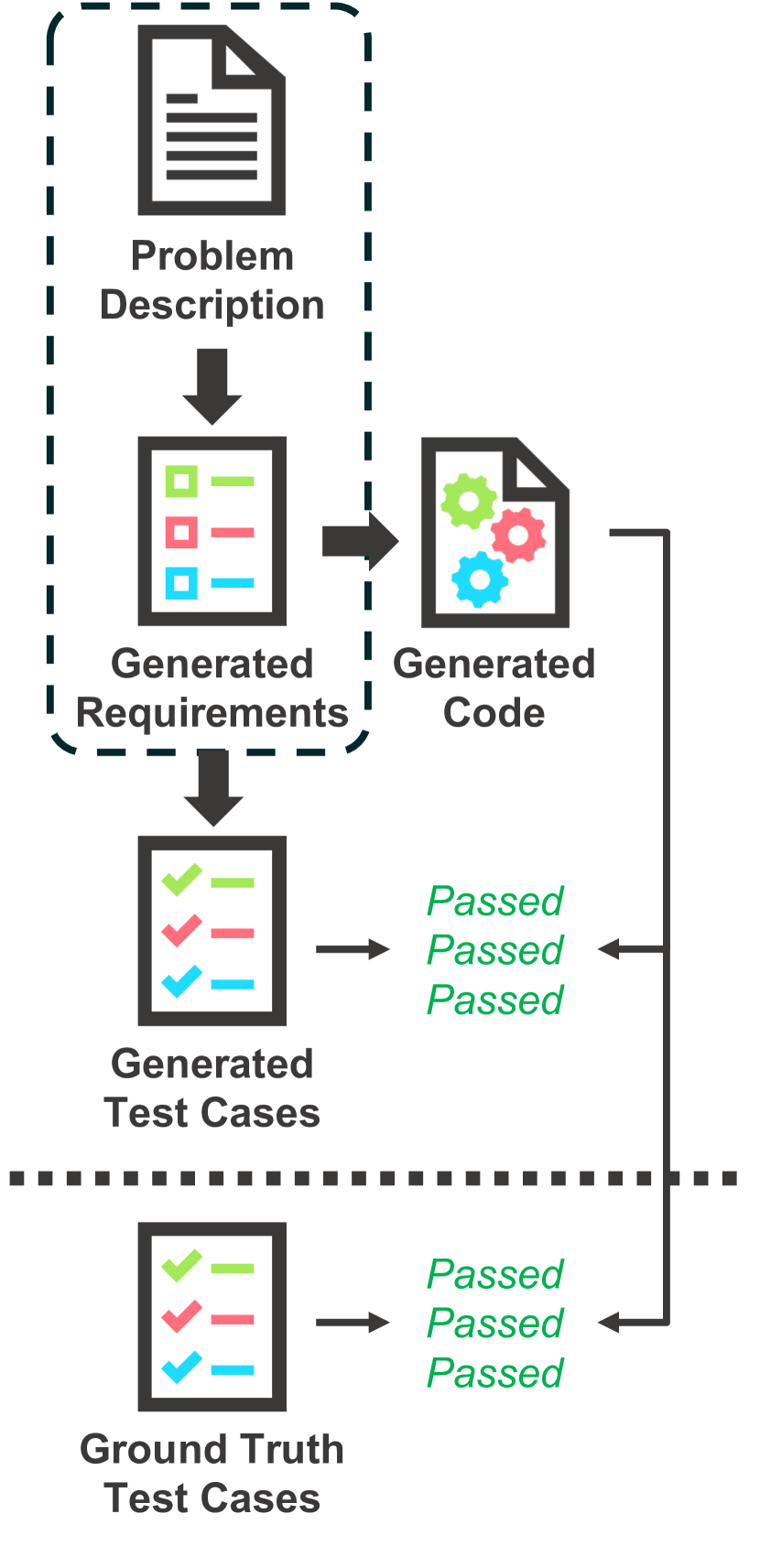
核心思路:ARCHCODE的核心思路是利用上下文学习的能力,让大语言模型能够从给定的需求描述中学习并推断出完整的需求集合。通过组织已知的需求,并根据这些需求之间的关系推断出未明确表达的需求,从而更全面地理解软件的需求。然后,基于这些完整的需求生成代码片段和测试用例。
技术框架:ARCHCODE框架主要包含以下几个阶段:1) 需求提取和推断:利用上下文学习,从文本描述中提取已知的需求,并推断出未明确表达的需求。2) 代码片段生成:基于完整的需求集合,生成相应的代码片段。3) 测试用例生成:针对每个需求,生成相应的测试用例,用于验证代码片段是否满足该需求。4) 代码片段排序:根据代码片段的执行结果与测试用例的符合程度,对代码片段进行排序,选择最符合需求的片段。
关键创新:ARCHCODE的关键创新在于其利用上下文学习来增强大语言模型对软件需求的理解能力。通过组织已知的需求并推断未表达的需求,ARCHCODE能够生成更全面的需求集合,从而指导代码生成过程,提高代码质量。此外,引入了HumanEval-NFR基准,用于评估LLM在代码生成中对非功能性需求的满足程度。
关键设计:ARCHCODE的关键设计包括:1) 上下文学习策略,用于从文本描述中提取和推断需求。具体的prompt设计未知。2) 测试用例生成策略,针对每个需求生成相应的测试用例。具体生成方法未知。3) 代码片段排序算法,根据代码片段的执行结果与测试用例的符合程度,对代码片段进行排序。具体排序算法未知。
🖼️ 关键图片


📊 实验亮点
ARCHCODE在公共基准测试中显著提高了Pass@k分数,表明其在满足功能性需求方面具有显著优势。此外,ARCHCODE在HumanEval-NFR基准测试中优于基线方法,证明了其在满足非功能性需求方面的能力。具体提升幅度未知,需要查阅论文原文。
🎯 应用场景
ARCHCODE具有广泛的应用前景,可以应用于自动化软件开发、代码生成、测试用例生成等领域。它可以帮助开发人员更高效地生成高质量的代码,并减少软件开发过程中的错误。此外,ARCHCODE还可以用于教育领域,帮助学生更好地理解软件需求和代码生成过程,提高编程能力。未来,ARCHCODE可以进一步扩展到支持更复杂的软件需求和编程语言,并与其他软件开发工具集成,构建更完善的自动化软件开发平台。
📄 摘要(原文)
This paper aims to extend the code generation capability of large language models (LLMs) to automatically manage comprehensive software requirements from given textual descriptions. Such requirements include both functional (i.e. achieving expected behavior for inputs) and non-functional (e.g., time/space performance, robustness, maintainability) requirements. However, textual descriptions can either express requirements verbosely or may even omit some of them. We introduce ARCHCODE, a novel framework that leverages in-context learning to organize requirements observed in descriptions and to extrapolate unexpressed requirements from them. ARCHCODE generates requirements from given descriptions, conditioning them to produce code snippets and test cases. Each test case is tailored to one of the requirements, allowing for the ranking of code snippets based on the compliance of their execution results with the requirements. Public benchmarks show that ARCHCODE enhances to satisfy functional requirements, significantly improving Pass@k scores. Furthermore, we introduce HumanEval-NFR, the first evaluation of LLMs' non-functional requirements in code generation, demonstrating ARCHCODE's superiority over baseline methods. The implementation of ARCHCODE and the HumanEval-NFR benchmark are both publicly accessible.