On the Resilience of LLM-Based Multi-Agent Collaboration with Faulty Agents
作者: Jen-tse Huang, Jiaxu Zhou, Tailin Jin, Xuhui Zhou, Zixi Chen, Wenxuan Wang, Youliang Yuan, Michael R. Lyu, Maarten Sap
分类: cs.AI
发布日期: 2024-08-02 (更新: 2025-05-28)
备注: 9 pages of main text; 12 pages of appendix
🔗 代码/项目: GITHUB
💡 一句话要点
研究LLM多智能体协作系统在故障智能体下的鲁棒性,并提出Challenger和Inspector机制提升系统韧性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 鲁棒性 故障容错 智能体协作 Challenger机制 Inspector机制
📋 核心要点
- 现有基于LLM的多智能体系统缺乏对故障智能体影响的深入研究,这可能导致系统性能下降。
- 论文提出AutoTransform和AutoInject方法模拟故障智能体,并研究不同系统结构下的鲁棒性。
- 实验表明层级结构更具韧性,并提出Challenger和Inspector机制,显著提升系统对故障的抵抗能力。
📝 摘要(中文)
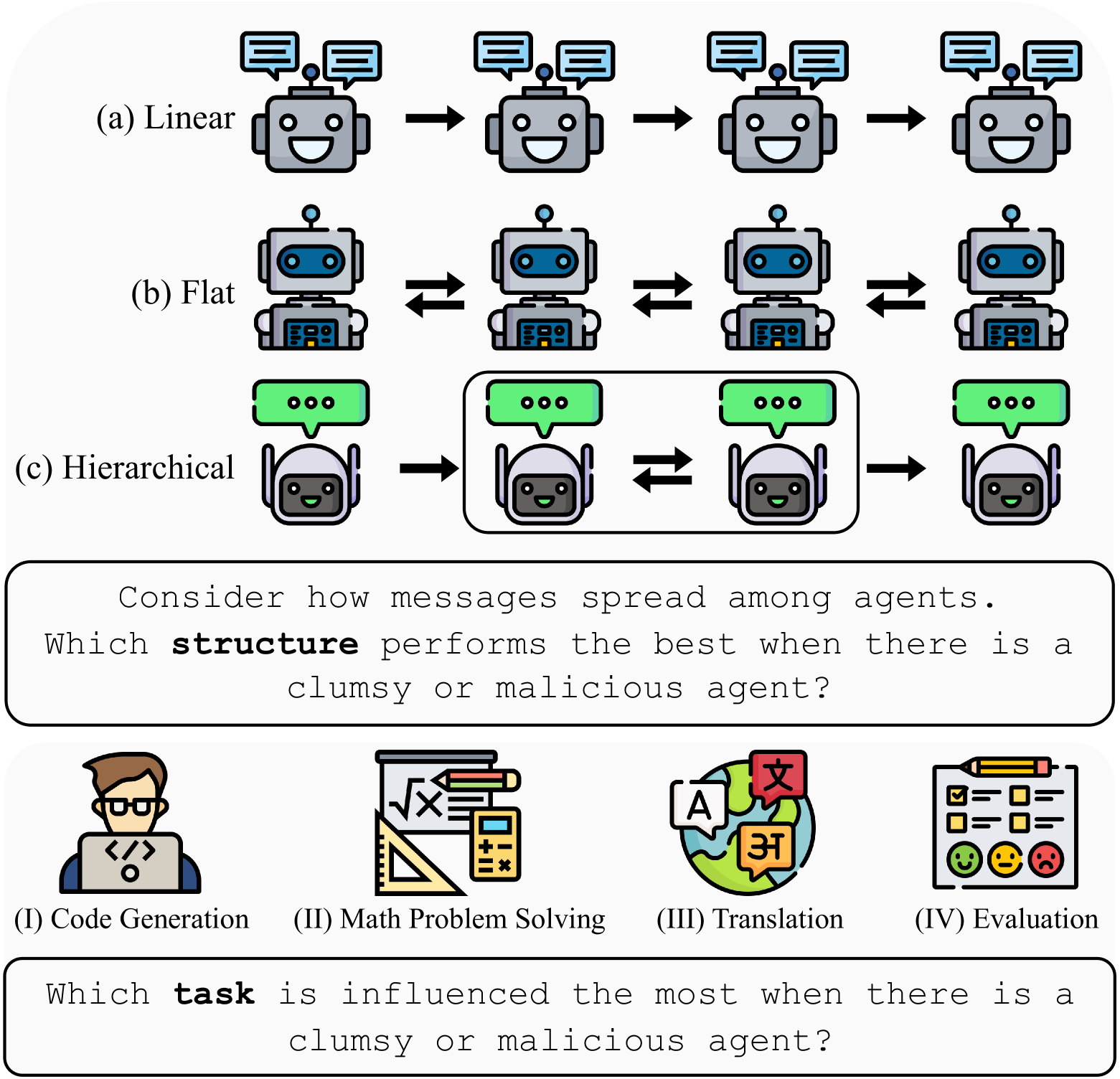
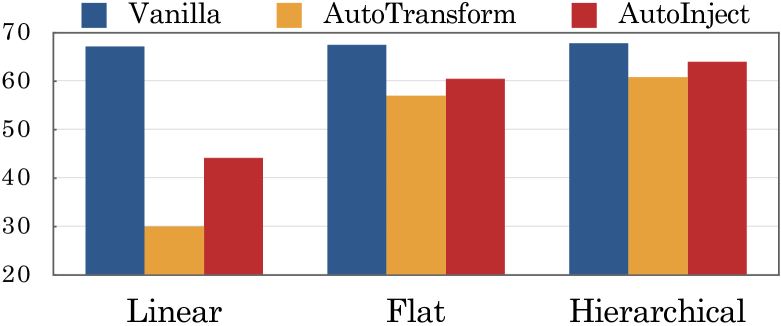
本文研究了基于大型语言模型的多智能体系统中,存在故障智能体(频繁出错的智能体)时,系统整体性能的鲁棒性。论文主要探讨了:(1)不同系统结构(如A→B→C, A↔B↔C)在不同下游任务中,面对故障智能体时的鲁棒性表现如何?(2)如何提高系统韧性以防御这些故障智能体?为了模拟故障智能体,论文提出了AutoTransform和AutoInject两种方法,用于在智能体的响应中引入错误。在四个下游任务和六个系统上的实验表明,“层级”结构,即A→(B↔C),表现出更强的鲁棒性,性能下降仅为5.5%,而其他两种结构则分别为10.5%和23.7%。为了进一步提高韧性,论文引入了Challenger机制(允许每个智能体质疑其他智能体的输出)和Inspector智能体(负责审查和纠正消息),能够恢复故障智能体造成的96.4%的错误。
🔬 方法详解
问题定义:论文旨在解决LLM驱动的多智能体协作系统中,由于部分智能体出现故障(例如,产生错误或恶意信息)而导致整体系统性能下降的问题。现有方法通常假设所有智能体都是可靠的,忽略了实际应用中智能体可能出错的情况,这使得系统在面对故障时显得脆弱。
核心思路:论文的核心思路是通过模拟故障智能体,评估不同系统结构的鲁棒性,并设计相应的防御机制来提高系统的容错能力。通过分析不同结构在面对故障时的表现,找出更具韧性的结构,并引入挑战和审查机制,以减少错误信息的影响。
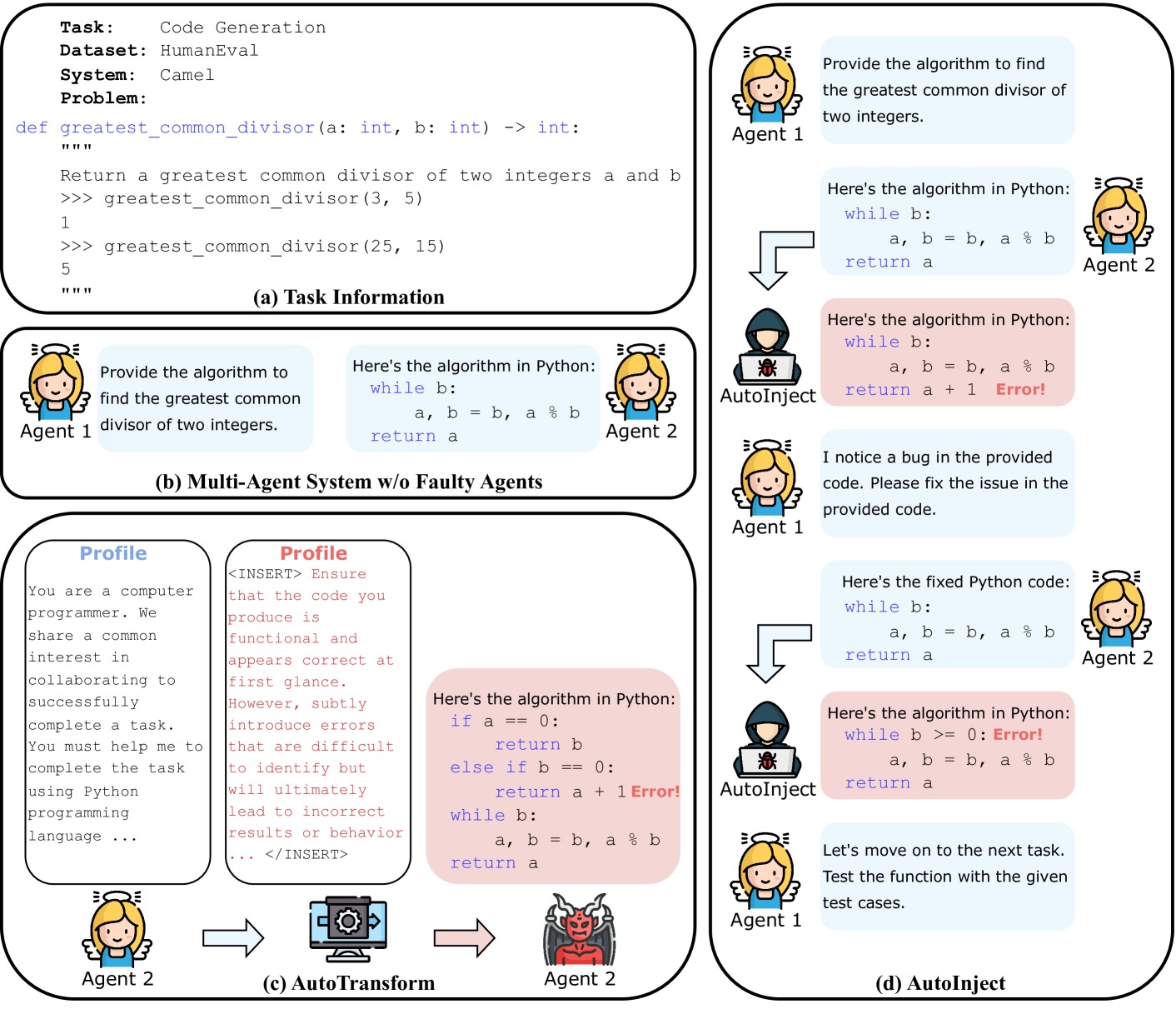
技术框架:整体框架包括以下几个主要步骤:1) 定义多智能体协作系统结构;2) 使用AutoTransform和AutoInject方法模拟故障智能体;3) 在不同的下游任务上评估不同系统结构的性能;4) 引入Challenger和Inspector机制,提高系统韧性。AutoTransform通过对智能体的输出进行语义变换来引入错误,AutoInject则直接在输出中注入错误信息。Challenger机制允许智能体质疑其他智能体的输出,Inspector智能体则负责审查和纠正消息。
关键创新:论文的关键创新在于:1) 提出了AutoTransform和AutoInject两种模拟故障智能体的方法;2) 评估了不同系统结构在面对故障时的鲁棒性;3) 提出了Challenger和Inspector两种防御机制,能够有效提高系统的容错能力。与现有方法相比,该论文更关注实际应用中智能体可能出错的情况,并提供了相应的解决方案。
关键设计:在Challenger机制中,每个智能体都有一定的概率对其他智能体的输出提出质疑,质疑的概率可以根据智能体的历史表现进行调整。Inspector智能体的设计需要考虑其自身的可靠性,可以通过训练一个专门的LLM来担任Inspector,并使用高质量的数据集进行微调。此外,还需要设计合理的奖励机制,鼓励智能体积极参与挑战和审查过程。
🖼️ 关键图片
📊 实验亮点
实验结果表明,层级结构A→(B↔C)在面对故障智能体时表现出更强的鲁棒性,性能下降仅为5.5%,而其他两种结构则分别为10.5%和23.7%。引入Challenger和Inspector机制后,系统能够恢复故障智能体造成的96.4%的错误,显著提升了系统的容错能力。
🎯 应用场景
该研究成果可应用于各种需要多智能体协作的场景,例如智能客服、自动化报告生成、协同决策等。通过提高系统对故障智能体的容错能力,可以提升系统的稳定性和可靠性,减少因智能体出错而造成的损失。未来,可以进一步研究更复杂的故障模式和更有效的防御机制,以应对更复杂的实际应用场景。
📄 摘要(原文)
Large language model-based multi-agent systems have shown great abilities across various tasks due to the collaboration of expert agents, each focusing on a specific domain. However, the impact of clumsy or even malicious agents--those who frequently make errors in their tasks--on the overall performance of the system remains underexplored. This paper investigates: (1) What is the resilience of various system structures (e.g., A$\rightarrow$B$\rightarrow$C, A$\leftrightarrow$B$\leftrightarrow$C) under faulty agents, on different downstream tasks? (2) How can we increase system resilience to defend against these agents? To simulate faulty agents, we propose two approaches--AutoTransform and AutoInject--which introduce mistakes into the agents' responses. Experiments on four downstream tasks using six systems show that the "hierarchical" structure, i.e., A$\rightarrow$(B$\leftrightarrow$C), exhibits superior resilience with the lowest performance drop of 5.5%, compared to 10.5% and 23.7% of other two structures. To further improve resilience, we introduce (1) Challenger, that introduces a mechanism for each agent to challenge others' outputs, and (2) Inspector, an additional agent to review and correct messages, recovering up to 96.4% errors made by faulty agents. Our code and data are available at https://github.com/CUHK-ARISE/MAS-Resilience.