From Feature Importance to Natural Language Explanations Using LLMs with RAG
作者: Sule Tekkesinoglu, Lars Kunze
分类: cs.AI, cs.CL, cs.CV, cs.HC, cs.LG
发布日期: 2024-07-30
💡 一句话要点
提出基于RAG的LLM解释框架,用于提升场景理解任务中模型决策的可解释性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可解释性AI 大型语言模型 检索增强生成 特征重要性 反事实推理
📋 核心要点
- 现有机器学习模型在自主决策中应用广泛,但缺乏有效的人机交互解释机制,难以理解模型决策过程。
- 论文提出利用外部知识库增强LLM的解释能力,通过可追溯的问答方式,提供更具上下文关联的模型决策解释。
- 实验结果表明,LLM生成的解释包含了社会性、因果性、选择性和对比性等要素,提升了解释的质量。
📝 摘要(中文)
随着机器学习在涉及人机交互的自主决策过程中变得越来越重要,通过对话方式理解模型输出的需求日益增长。目前,基础模型正被探索作为后验解释器,为阐明预测模型的决策机制提供途径。本文提出了一种可追溯的问答方法,利用外部知识库来告知大型语言模型(LLM)对场景理解任务中用户查询的响应。该知识库包含关于模型输出的上下文细节,包括高级特征、特征重要性和替代概率。我们采用减法反事实推理来计算特征重要性,这是一种分析分解语义特征导致输出变化的方法。此外,为了保持流畅的对话,我们将从社会科学关于人类解释的研究中提取的四个关键特征——社会性、因果性、选择性和对比性——整合到单样本提示中,指导响应生成过程。我们的评估表明,LLM生成的解释包含了这些要素,表明其有潜力弥合复杂模型输出和自然语言表达之间的差距。
🔬 方法详解
问题定义:现有机器学习模型,尤其是在场景理解任务中,其决策过程往往难以理解,缺乏透明度。这阻碍了人机交互,并降低了用户对模型的信任。现有的解释方法可能不够自然,难以通过对话的方式进行交互和理解。
核心思路:论文的核心思路是利用大型语言模型(LLM)作为后验解释器,并结合检索增强生成(RAG)技术,构建一个可追溯的问答系统。通过外部知识库提供关于模型输出的上下文信息,使LLM能够生成更具信息量和可信度的解释。
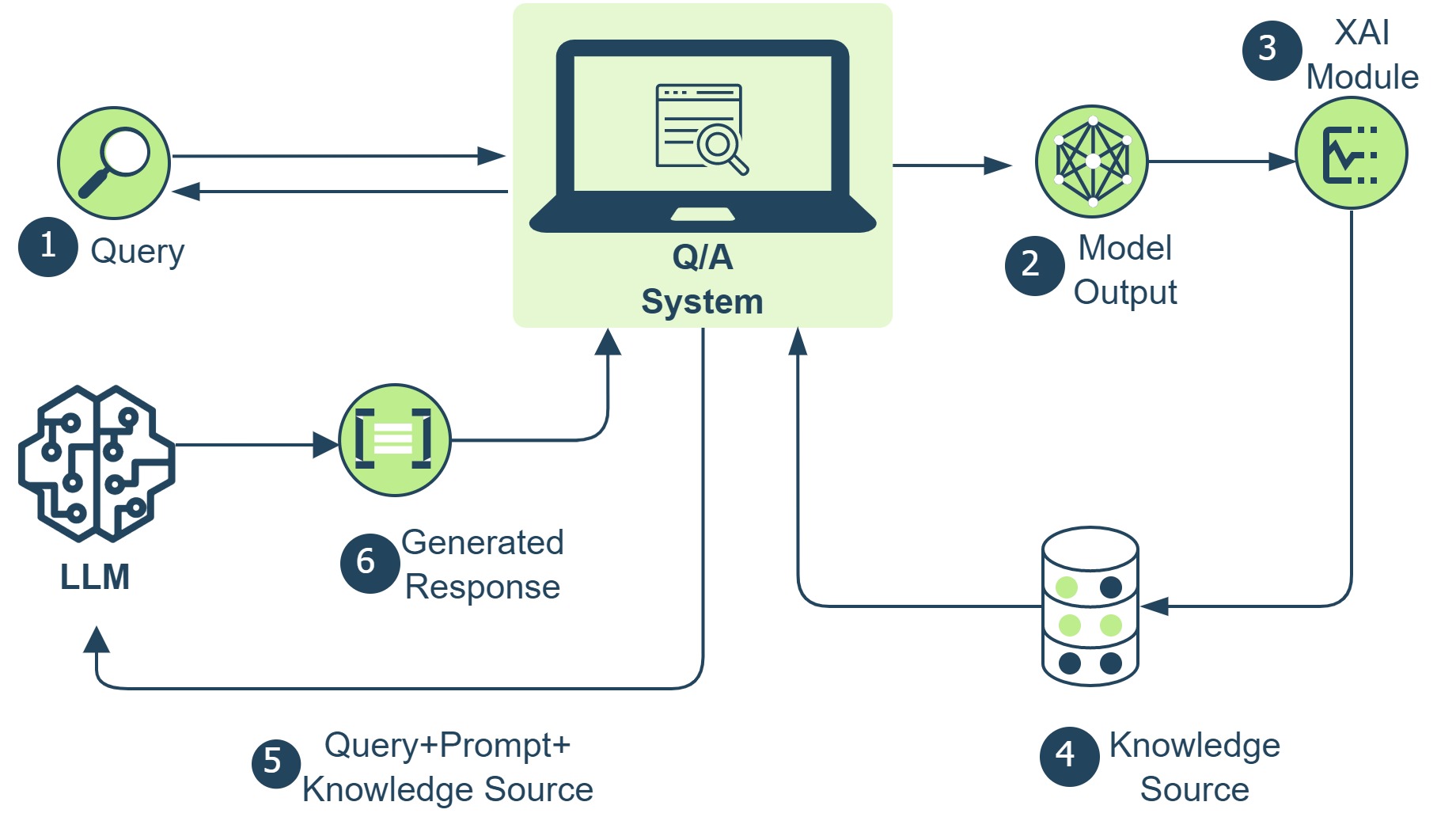
技术框架:该框架主要包含以下几个模块:1) 特征重要性计算模块:使用减法反事实推理方法,分析分解语义特征对模型输出的影响,从而计算特征重要性。2) 知识库构建模块:构建包含高级特征、特征重要性和替代概率等信息的知识库。3) LLM问答模块:利用RAG技术,根据用户查询从知识库中检索相关信息,并将其作为上下文输入LLM,生成自然语言解释。4) 提示工程模块:设计包含社会性、因果性、选择性和对比性等要素的单样本提示,引导LLM生成高质量的解释。
关键创新:该论文的关键创新在于将RAG技术与LLM相结合,用于生成可追溯的模型解释。通过外部知识库提供上下文信息,使LLM能够生成更具信息量和可信度的解释。此外,论文还提出了将社会科学中关于人类解释的要素融入提示工程中,从而提升了解释的质量。
关键设计:论文采用减法反事实推理计算特征重要性,具体方法未知。知识库的构建方式和存储格式未知。提示工程方面,论文设计了包含社会性、因果性、选择性和对比性等要素的单样本提示,但具体提示内容未知。LLM的选择和参数设置未知。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了LLM生成的解释包含了社会性、因果性、选择性和对比性等要素,表明该方法能够有效提升模型解释的质量。具体的性能数据、对比基线和提升幅度未知,需要进一步查阅论文原文。
🎯 应用场景
该研究成果可应用于各种需要模型可解释性的场景,例如自动驾驶、医疗诊断、金融风控等。通过提供自然语言解释,可以帮助用户理解模型的决策过程,提高模型的透明度和可信度,从而促进人机协作和决策。
📄 摘要(原文)
As machine learning becomes increasingly integral to autonomous decision-making processes involving human interaction, the necessity of comprehending the model's outputs through conversational means increases. Most recently, foundation models are being explored for their potential as post hoc explainers, providing a pathway to elucidate the decision-making mechanisms of predictive models. In this work, we introduce traceable question-answering, leveraging an external knowledge repository to inform the responses of Large Language Models (LLMs) to user queries within a scene understanding task. This knowledge repository comprises contextual details regarding the model's output, containing high-level features, feature importance, and alternative probabilities. We employ subtractive counterfactual reasoning to compute feature importance, a method that entails analysing output variations resulting from decomposing semantic features. Furthermore, to maintain a seamless conversational flow, we integrate four key characteristics - social, causal, selective, and contrastive - drawn from social science research on human explanations into a single-shot prompt, guiding the response generation process. Our evaluation demonstrates that explanations generated by the LLMs encompassed these elements, indicating its potential to bridge the gap between complex model outputs and natural language expressions.