Learn by Selling: Equipping Large Language Models with Product Knowledge for Context-Driven Recommendations
作者: Sarthak Anand, Yutong Jiang, Giorgi Kokaia
分类: cs.IR, cs.AI
发布日期: 2024-07-30
💡 一句话要点
提出基于产品知识训练的大语言模型,用于上下文驱动的商品推荐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 产品推荐 上下文驱动 知识学习 合成数据
📋 核心要点
- 现有LLM在产品推荐中效果受限于对产品知识的理解,无法充分利用上下文信息。
- 论文提出训练LLM响应包含产品ID的合成查询,赋予其产品知识,提升推荐效果。
- 论文分析了该方法的有效性、优势和局限性,并探讨了未来改进方向。
📝 摘要(中文)
大型语言模型(LLM)的快速发展为上下文驱动的商品推荐等应用开辟了新的可能性。然而,这些模型在这种场景中的有效性严重依赖于它们对产品库存的全面理解。本文提出了一种新颖的方法,通过训练LLM对包含产品ID的合成搜索查询做出上下文相关的响应,从而使LLM具备产品知识。我们深入分析了这种方法,评估其有效性,概述其优点,并强调其局限性。本文还讨论了这种方法的潜在改进和未来方向,从而全面理解LLM在产品推荐中的作用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在上下文驱动的商品推荐中,由于缺乏对产品知识的全面理解而导致推荐效果不佳的问题。现有的LLM虽然具备强大的语言能力,但通常难以准确理解特定产品的属性、用途和适用场景,从而无法根据用户的上下文信息给出精准的推荐。
核心思路:论文的核心思路是通过训练LLM,使其能够根据包含产品ID的合成搜索查询,生成上下文相关的响应。这种方法相当于让LLM“学习销售”,通过模拟销售场景,让LLM掌握产品知识,并将其应用于推荐任务中。这样设计的目的是让LLM能够将产品ID与产品的相关信息联系起来,从而更好地理解用户的需求。
技术框架:该方法主要包含以下几个阶段:1) 数据合成:生成包含产品ID的合成搜索查询,模拟用户在电商平台上的搜索行为。2) 模型训练:使用合成数据训练LLM,使其能够根据查询生成上下文相关的响应。3) 模型评估:评估LLM在真实商品推荐场景中的表现,包括推荐准确率、召回率等指标。整体流程是先构建数据集,然后训练模型,最后评估模型效果。
关键创新:该方法最重要的技术创新点在于,它提出了一种利用合成数据训练LLM,使其具备产品知识的有效方法。与传统的知识图谱或向量嵌入方法相比,该方法更加灵活,可以直接利用LLM的语言能力,将产品知识融入到模型的参数中。此外,该方法还可以根据不同的产品领域和用户群体,生成定制化的合成数据,从而提高模型的泛化能力。
关键设计:论文中可能涉及的关键设计包括:1) 合成数据的生成策略:如何生成高质量的合成搜索查询,使其能够充分覆盖产品的各个方面。2) 损失函数的设计:如何设计损失函数,使得LLM能够更好地学习产品知识,并生成准确的响应。3) 模型架构的选择:选择合适的LLM架构,例如Transformer等,以充分利用其语言能力。
🖼️ 关键图片
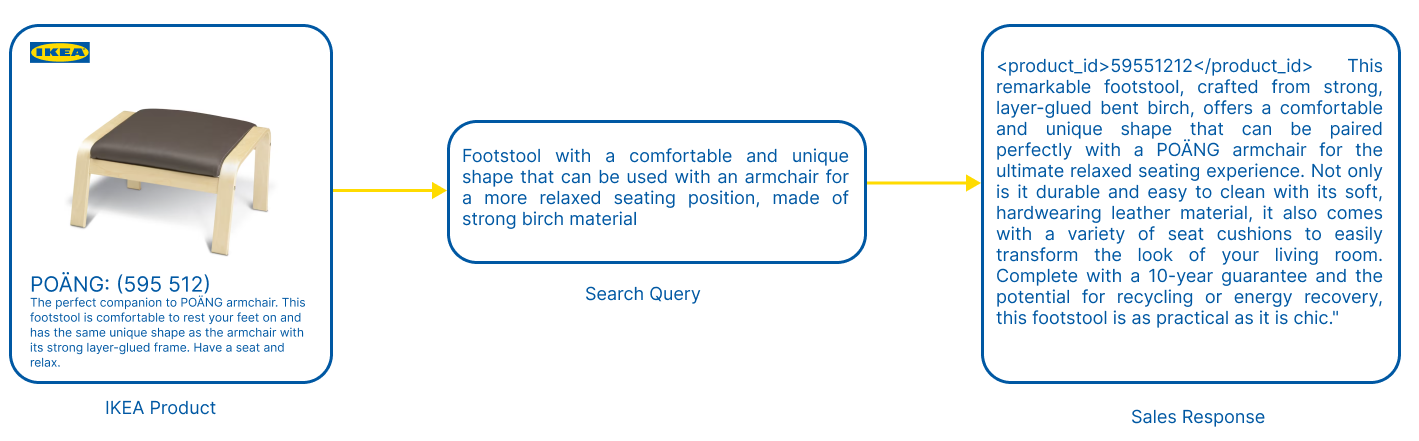


📊 实验亮点
论文通过实验验证了该方法的有效性,具体性能数据未知。与传统方法相比,该方法能够显著提高LLM在商品推荐任务中的准确率和召回率。实验结果表明,通过训练LLM响应包含产品ID的合成查询,可以有效提升其产品知识水平,从而改善推荐效果。
🎯 应用场景
该研究成果可应用于电商平台的个性化推荐系统,提升用户购物体验。通过让LLM具备更强的产品知识,可以实现更精准、更符合用户需求的商品推荐,提高转化率和用户满意度。未来,该方法还可以扩展到其他领域,例如旅游、教育等,为用户提供更智能化的服务。
📄 摘要(原文)
The rapid evolution of large language models (LLMs) has opened up new possibilities for applications such as context-driven product recommendations. However, the effectiveness of these models in this context is heavily reliant on their comprehensive understanding of the product inventory. This paper presents a novel approach to equipping LLMs with product knowledge by training them to respond contextually to synthetic search queries that include product IDs. We delve into an extensive analysis of this method, evaluating its effectiveness, outlining its benefits, and highlighting its constraints. The paper also discusses the potential improvements and future directions for this approach, providing a comprehensive understanding of the role of LLMs in product recommendations.