How to Measure the Intelligence of Large Language Models?
作者: Nils Körber, Silvan Wehrli, Christopher Irrgang
分类: cs.AI, cs.LG
发布日期: 2024-07-30
备注: 3 pages, 1 figure
💡 一句话要点
探讨大语言模型智能评估方法:超越任务指标,兼顾质量与数量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 智能评估 质量评估 数量评估 可信度 事实一致性 幻觉 AI伦理
📋 核心要点
- 现有评估方法侧重于任务特定指标,未能全面反映LLM的智能水平,尤其是在可信度和幻觉问题上。
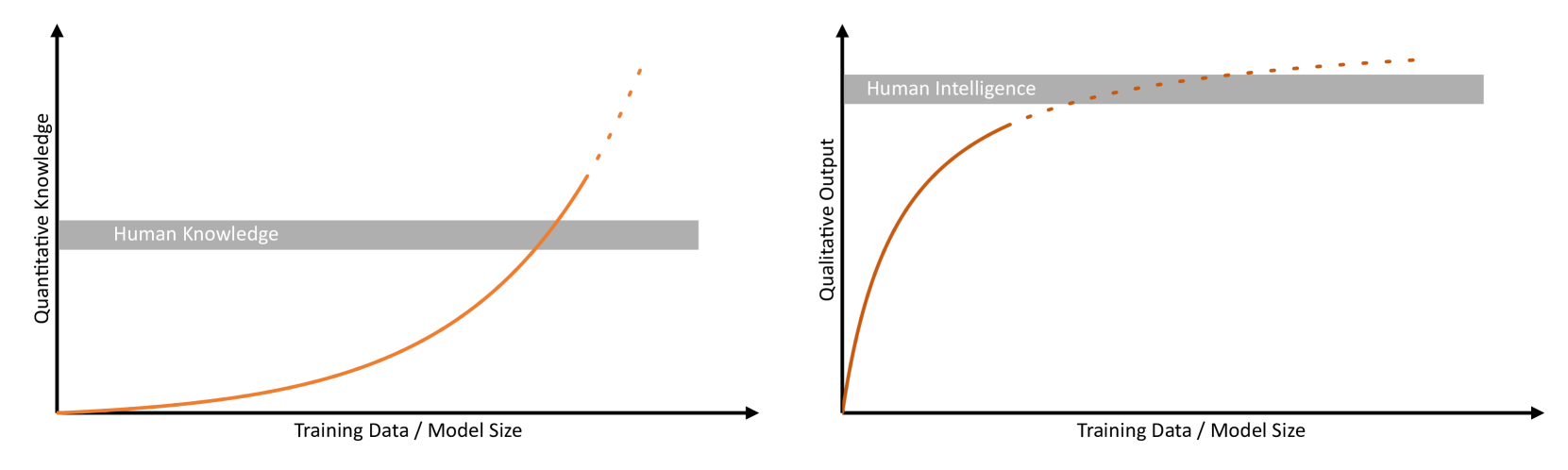
- 论文提出应从质量和数量两个维度分别评估LLM的智能,超越单一的统计指标,更全面地衡量其能力。
- 论文强调了当前LLM在特定任务上的优异表现,同时也指出了其在事实一致性和可信度方面的不足。
📝 摘要(中文)
随着ChatGPT等大型语言模型(LLMs)的发布,关于当前和未来模型的智能、可能性和风险的讨论受到了广泛关注。这场讨论包括关于所谓的“超人”AI(即比人类聪明几个数量级的AI系统)即将崛起的备受争议的场景。毋庸置疑,当前最先进的语言模型已经通过了图灵测试。此外,当前的模型在一些基准测试中优于人类,因此公开可用的LLM已经成为连接日常生活、工业和科学的多功能伙伴。尽管它们具有令人印象深刻的能力,但LLM有时在人类认为微不足道的任务中会完全失败。在其他情况下,LLM的可信度变得更加难以捉摸和评估。以学术界为例,语言模型能够仅用少量输入就撰写出令人信服的关于给定主题的研究文章。然而,由于事实一致性方面的缺乏可信度或AI生成文本中持续存在的幻觉,许多科学期刊对基于AI的内容施加了一系列限制。鉴于这些观察结果,出现了一个问题,即适用于人类智能的相同指标是否也适用于计算方法,并且已经对此进行了广泛的讨论。事实上,指标的选择已经显示出极大地影响了对潜在智能出现的评估。在此,我们认为,LLM的智能不仅应通过特定于任务的统计指标来评估,还应在质量和数量方面分别进行评估。
🔬 方法详解
问题定义:当前评估大语言模型智能的方法主要依赖于特定任务的统计指标,例如准确率、召回率等。这些指标虽然能够反映模型在特定任务上的表现,但无法全面衡量模型的智能水平,尤其是在可信度、事实一致性以及是否存在幻觉等方面。现有方法的痛点在于缺乏对模型质量的有效评估,导致对模型能力的认知存在偏差。
核心思路:论文的核心思路是将大语言模型的智能评估分解为两个维度:质量和数量。数量维度关注模型在特定任务上的表现,例如准确率、效率等,而质量维度则关注模型生成内容的真实性、可信度、逻辑性以及是否存在偏见等。通过同时考虑这两个维度,可以更全面、客观地评估模型的智能水平。
技术框架:论文并未提出一个具体的、可直接实现的技术框架,而更多的是一种评估理念的转变。它强调在评估LLM时,需要综合考虑多种因素,包括任务性能、生成内容的质量、模型的鲁棒性以及对伦理道德的遵守程度。因此,评估框架需要根据具体的应用场景和评估目标进行定制。
关键创新:论文最重要的创新点在于提出了将LLM的智能评估分解为质量和数量两个维度的思想。这种思想打破了以往只关注任务性能的局限,更加注重模型生成内容的质量和可信度。这对于提高LLM的可靠性和安全性具有重要意义。
关键设计:由于论文主要关注评估理念,因此没有涉及具体的参数设置、损失函数或网络结构等技术细节。未来的研究可以基于这一理念,设计更加完善的评估指标和方法,例如,可以引入专家评估、用户反馈等方式来衡量模型生成内容的质量。
🖼️ 关键图片
📊 实验亮点
论文的核心贡献在于提出了评估LLM智能的新视角,即同时关注质量和数量两个维度。虽然没有提供具体的实验数据,但该观点对于改进LLM的评估方法具有重要的指导意义,并能促进对LLM能力更全面和客观的认识。未来的研究可以基于此框架设计更精细的评估指标。
🎯 应用场景
该研究成果可应用于大语言模型的开发、评估和部署等多个环节。例如,在模型开发阶段,可以利用质量和数量两个维度的评估指标来指导模型的训练和优化;在模型部署阶段,可以利用这些指标来监控模型的性能和安全性;在学术研究领域,可以为大语言模型的智能评估提供新的思路和方法。
📄 摘要(原文)
With the release of ChatGPT and other large language models (LLMs) the discussion about the intelligence, possibilities, and risks, of current and future models have seen large attention. This discussion included much debated scenarios about the imminent rise of so-called "super-human" AI, i.e., AI systems that are orders of magnitude smarter than humans. In the spirit of Alan Turing, there is no doubt that current state-of-the-art language models already pass his famous test. Moreover, current models outperform humans in several benchmark tests, so that publicly available LLMs have already become versatile companions that connect everyday life, industry and science. Despite their impressive capabilities, LLMs sometimes fail completely at tasks that are thought to be trivial for humans. In other cases, the trustworthiness of LLMs becomes much more elusive and difficult to evaluate. Taking the example of academia, language models are capable of writing convincing research articles on a given topic with only little input. Yet, the lack of trustworthiness in terms of factual consistency or the existence of persistent hallucinations in AI-generated text bodies has led to a range of restrictions for AI-based content in many scientific journals. In view of these observations, the question arises as to whether the same metrics that apply to human intelligence can also be applied to computational methods and has been discussed extensively. In fact, the choice of metrics has already been shown to dramatically influence assessments on potential intelligence emergence. Here, we argue that the intelligence of LLMs should not only be assessed by task-specific statistical metrics, but separately in terms of qualitative and quantitative measures.