Wonderful Team: Zero-Shot Physical Task Planning with Visual LLMs
作者: Zidan Wang, Rui Shen, Bradly Stadie
分类: cs.AI, cs.RO
发布日期: 2024-07-26 (更新: 2025-02-04)
备注: aka Wonderful Team
💡 一句话要点
Wonderful Team:利用视觉大语言模型实现零样本物理任务规划
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉大语言模型 机器人规划 零样本学习 多智能体系统 物理推理 语义理解 端到端学习
📋 核心要点
- 现有机器人高级规划方法依赖独立的视觉系统,感知、控制和规划之间缺乏紧密集成。
- Wonderful Team利用VLLM进行端到端的规划,直接从视觉输入生成动作序列,实现感知、控制和规划的集成。
- 实验表明,该方法在VimaBench和语义推理任务上显著优于现有方法,成功率平均提升30%-70%。
📝 摘要(中文)
本文介绍了一个名为Wonderful Team的多智能体视觉大语言模型(VLLM)框架,用于在零样本模式下执行高级机器人规划。在此背景下,零样本高级规划意味着对于一个新环境,我们向VLLM提供机器人周围环境的图像和任务描述,VLLM输出机器人完成任务所需的动作序列。与之前用于机器人操作的高级视觉规划方法不同,我们的方法使用VLLM进行整个规划过程,从而在感知、控制和规划之间实现更紧密的集成循环。因此,Wonderful Team在现实世界的语义和物理规划任务上的性能通常超过依赖于独立视觉系统的方法。例如,在VimaBench上,我们看到比NLaP等先前方法平均提高了40%的成功率;在Trajectory Generator论文中的任务上,比Trajectory Generators平均提高了30%,包括绘制和擦拭盘子;在一个新的语义推理任务集上,包括具有隐式语言约束的环境重排,比Trajectory Generators平均提高了70%。我们希望这些结果突显出VLLM在过去一年中的快速改进,并促使社区考虑将VLLM作为未来某些高级机器人规划问题的选择。
🔬 方法详解
问题定义:现有机器人高级规划方法通常依赖于独立的视觉系统进行环境感知,然后将感知结果输入到规划器中。这种分离的架构导致感知、控制和规划之间的信息传递存在瓶颈,难以处理复杂的语义和物理推理任务。此外,现有方法在新环境中的泛化能力有限,需要大量的训练数据才能适应新的任务。
核心思路:Wonderful Team的核心思路是利用视觉大语言模型(VLLM)强大的视觉理解和语言推理能力,直接从视觉输入生成完成任务所需的动作序列。通过将感知、控制和规划集成到一个统一的VLLM框架中,可以实现更高效的信息传递和更强的泛化能力。这种端到端的规划方式避免了对独立视觉系统的依赖,简化了整个系统的设计。
技术框架:Wonderful Team的整体框架包括以下几个主要步骤:1) 输入:向VLLM提供机器人周围环境的图像和任务描述;2) VLLM规划:VLLM根据图像和任务描述,生成完成任务所需的动作序列;3) 动作执行:机器人执行VLLM生成的动作序列;4) 循环反馈:根据执行结果,VLLM可以进行迭代规划,直到任务完成。该框架的关键在于VLLM,它负责从视觉输入到动作序列的映射。
关键创新:Wonderful Team最重要的创新点在于将VLLM应用于端到端的机器人高级规划。与现有方法相比,Wonderful Team不需要独立的视觉系统,而是直接利用VLLM的视觉理解和语言推理能力进行规划。这种集成化的方法简化了系统设计,提高了规划效率和泛化能力。此外,Wonderful Team还探索了多智能体VLLM协作的可能性,进一步提高了规划的鲁棒性和灵活性。
关键设计:Wonderful Team的关键设计包括:1) VLLM的选择:选择具有强大的视觉理解和语言推理能力的VLLM,例如LLaVA、Flamingo等;2) 任务描述的格式:设计清晰简洁的任务描述格式,以便VLLM能够准确理解任务目标;3) 动作序列的表示:设计合适的动作序列表示方法,例如离散动作序列或连续动作参数;4) 迭代规划策略:设计有效的迭代规划策略,以便VLLM能够根据执行结果进行调整和优化。
🖼️ 关键图片
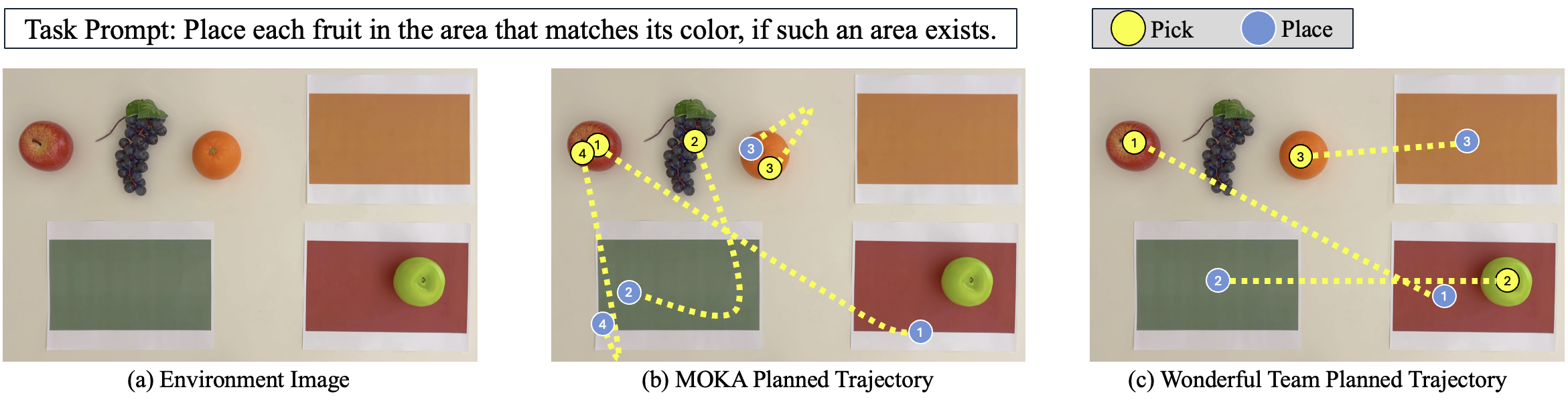


📊 实验亮点
Wonderful Team在多个真实世界的机器人任务上取得了显著的性能提升。在VimaBench上,成功率比NLaP等现有方法平均提高了40%。在Trajectory Generator论文中的任务上,比Trajectory Generators平均提高了30%,包括绘制和擦拭盘子。在一个新的语义推理任务集上,包括具有隐式语言约束的环境重排,比Trajectory Generators平均提高了70%。这些结果表明,Wonderful Team在复杂语义和物理推理任务上具有强大的优势。
🎯 应用场景
Wonderful Team具有广泛的应用前景,例如智能家居、工业自动化、医疗机器人等领域。它可以用于执行各种复杂的任务,例如物体抓取、环境整理、装配等。通过利用VLLM强大的视觉理解和语言推理能力,Wonderful Team可以实现更智能、更灵活的机器人控制,提高生产效率和服务质量。未来,该技术有望应用于更广泛的领域,例如自动驾驶、智能安防等。
📄 摘要(原文)
We introduce Wonderful Team, a multi-agent Vision Large Language Model (VLLM) framework for executing high-level robotic planning in a zero-shot regime. In our context, zero-shot high-level planning means that for a novel environment, we provide a VLLM with an image of the robot's surroundings and a task description, and the VLLM outputs the sequence of actions necessary for the robot to complete the task. Unlike previous methods for high-level visual planning for robotic manipulation, our method uses VLLMs for the entire planning process, enabling a more tightly integrated loop between perception, control, and planning. As a result, Wonderful Team's performance on real-world semantic and physical planning tasks often exceeds methods that rely on separate vision systems. For example, we see an average 40% success rate improvement on VimaBench over prior methods such as NLaP, an average 30% improvement over Trajectory Generators on tasks from the Trajectory Generator paper, including drawing and wiping a plate, and an average 70% improvement over Trajectory Generators on a new set of semantic reasoning tasks including environment rearrangement with implicit linguistic constraints. We hope these results highlight the rapid improvements of VLLMs in the past year, and motivate the community to consider VLLMs as an option for some high-level robotic planning problems in the future.