Collaborative Evolving Strategy for Automatic Data-Centric Development
作者: Xu Yang, Haotian Chen, Wenjun Feng, Haoxue Wang, Zeqi Ye, Xinjie Shen, Xiao Yang, Shizhao Sun, Weiqing Liu, Jiang Bian
分类: cs.AI
发布日期: 2024-07-26
备注: 23 pages, 7 figures
💡 一句话要点
提出Co-STEER,首个解决自动数据中心开发(AD^2)任务的LLM智能体。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动数据中心开发 大型语言模型 自主智能体 协作进化 数据增强 任务调度 知识学习
📋 核心要点
- 现有方法缺乏领域专家级的任务调度和实现能力,难以应对自动数据中心开发(AD^2)任务的核心挑战。
- Co-STEER智能体通过协作知识学习增强检索进化策略,利用LLM的复杂问题解决能力,实现调度和实现能力的协同进化。
- 实验结果表明,Co-STEER智能体在AD^2研究中取得了突破,展示了强大的可进化调度和实现能力,验证了其组件的有效性。
📝 摘要(中文)
人工智能(AI)在很大程度上得益于机器学习模型所需的大量高质量数据,从而对许多领域产生了重大影响。目前,重点已转向以数据为中心的AI策略,优先考虑数据开发而非模型设计进展。自动化这一过程至关重要。本文首次提出了自动数据中心开发(AD^2)任务,并概述了其核心挑战,这需要领域专家级的任务调度和实现能力,而先前的工作在很大程度上未曾探索。通过利用大型语言模型(LLM)强大的复杂问题解决能力,我们提出了一个基于LLM的自主智能体,配备了一种名为协作知识学习增强检索进化(Co-STEER)的策略,以同时应对所有挑战。具体来说,我们提出的Co-STEER智能体通过我们提出的进化策略来丰富其领域知识,并通过积累和检索特定领域的实践经验来发展其调度和实现技能。随着调度能力的提高,实现能力也会加速。同时,随着实现反馈变得更加彻底,调度准确性也会提高。这两种能力通过实践反馈共同发展,从而实现协作进化过程。大量的实验结果表明,我们的Co-STEER智能体在AD^2研究中取得了新的突破,具有强大的可进化调度和实现能力,并证明了其组件的显著有效性。我们的Co-STEER为AD^2的进步铺平了道路。
🔬 方法详解
问题定义:论文旨在解决自动数据中心开发(AD^2)任务,即如何自动地进行数据处理、清洗、增强等操作,以提升机器学习模型的性能。现有方法主要依赖人工或者简单的脚本,缺乏领域专家级的任务调度和实现能力,难以应对复杂的数据处理需求。现有方法难以自动化数据处理流程,效率低下,且难以保证数据质量。
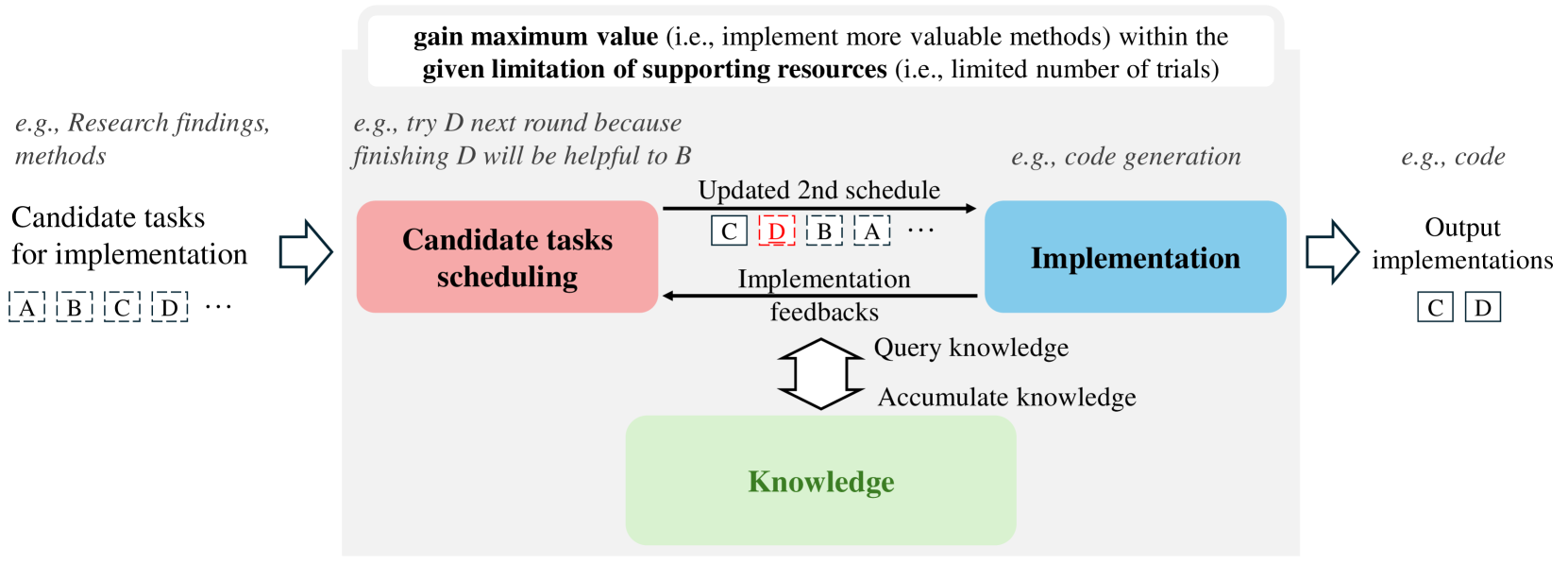
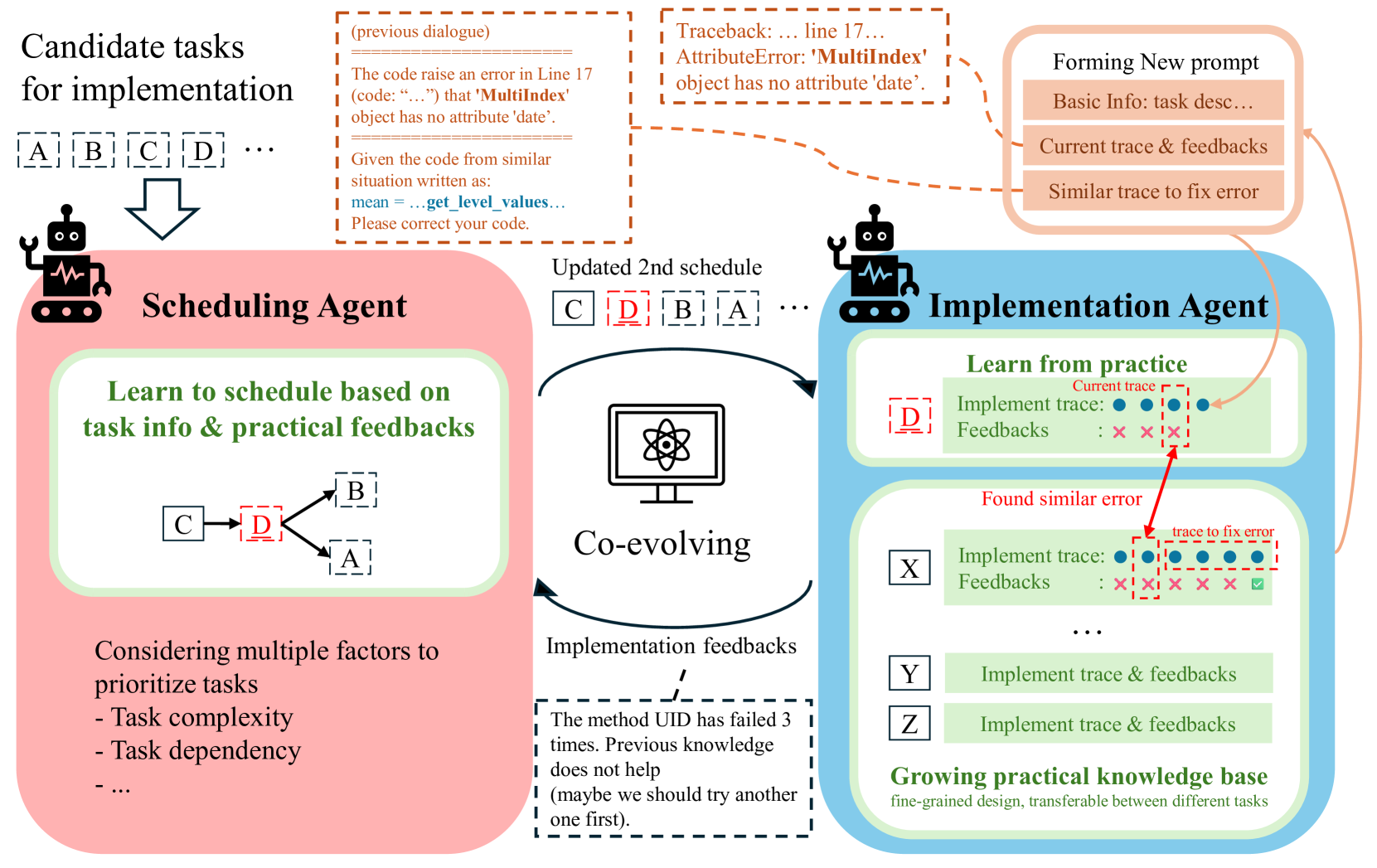
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大能力,构建一个自主智能体,使其能够像领域专家一样进行任务调度和实现。通过不断学习和积累经验,智能体可以逐步提升其数据处理能力,实现自动化的数据中心开发。Co-STEER策略旨在通过协作的方式,使智能体的调度和实现能力相互促进,共同进化。
技术框架:Co-STEER智能体的整体架构包含以下几个主要模块:1) 知识库:存储领域知识和实践经验;2) 调度器:负责任务的分解和调度;3) 实现器:负责执行具体的任务;4) 进化模块:负责根据反馈信息更新知识库和策略。智能体通过不断地与环境交互,获取反馈信息,并利用这些信息来改进自身的调度和实现能力。整个流程是一个迭代的过程,智能体在不断地实践中学习和进化。
关键创新:论文最重要的技术创新点在于提出了Co-STEER策略,该策略能够使智能体的调度和实现能力协同进化。与现有方法相比,Co-STEER策略能够更好地利用LLM的潜力,实现更高效、更智能的数据中心开发。Co-STEER策略通过知识学习和经验检索,不断提升智能体的领域知识和实践能力,使其能够更好地应对复杂的数据处理任务。
关键设计:Co-STEER策略的关键设计包括:1) 知识库的构建和维护:知识库需要包含丰富的领域知识和实践经验,并且需要定期更新;2) 调度器的设计:调度器需要能够根据任务的特点,合理地分解和调度任务;3) 实现器的设计:实现器需要能够高效地执行各种数据处理操作;4) 进化模块的设计:进化模块需要能够根据反馈信息,有效地更新知识库和策略。具体的参数设置、损失函数、网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
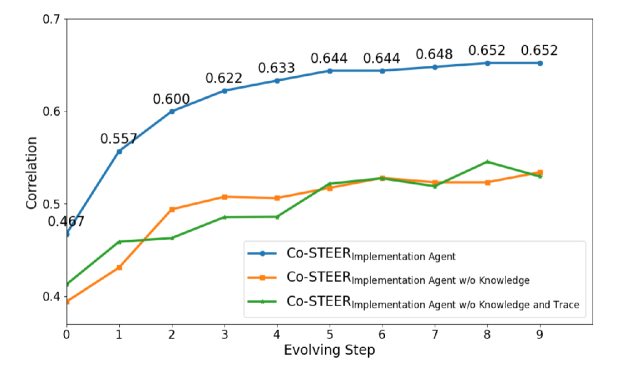
实验结果表明,Co-STEER智能体在AD^2任务上取得了显著的性能提升,超越了现有的基线方法。具体的性能数据和提升幅度在论文中进行了详细的展示。实验还验证了Co-STEER策略的有效性,证明了其能够使智能体的调度和实现能力协同进化。
🎯 应用场景
该研究成果可应用于各种需要大量数据处理的领域,例如计算机视觉、自然语言处理、推荐系统等。通过自动化数据中心开发,可以显著降低数据处理的成本,提高数据质量,从而提升机器学习模型的性能。未来,该技术有望推动人工智能在更多领域的应用。
📄 摘要(原文)
Artificial Intelligence (AI) significantly influences many fields, largely thanks to the vast amounts of high-quality data for machine learning models. The emphasis is now on a data-centric AI strategy, prioritizing data development over model design progress. Automating this process is crucial. In this paper, we serve as the first work to introduce the automatic data-centric development (AD^2) task and outline its core challenges, which require domain-experts-like task scheduling and implementation capability, largely unexplored by previous work. By leveraging the strong complex problem-solving capabilities of large language models (LLMs), we propose an LLM-based autonomous agent, equipped with a strategy named Collaborative Knowledge-STudying-Enhanced Evolution by Retrieval (Co-STEER), to simultaneously address all the challenges. Specifically, our proposed Co-STEER agent enriches its domain knowledge through our proposed evolving strategy and develops both its scheduling and implementation skills by accumulating and retrieving domain-specific practical experience. With an improved schedule, the capability for implementation accelerates. Simultaneously, as implementation feedback becomes more thorough, the scheduling accuracy increases. These two capabilities evolve together through practical feedback, enabling a collaborative evolution process. Extensive experimental results demonstrate that our Co-STEER agent breaks new ground in AD^2 research, possesses strong evolvable schedule and implementation ability, and demonstrates the significant effectiveness of its components. Our Co-STEER paves the way for AD^2 advancements.