Low-Latency Privacy-Preserving Deep Learning Design via Secure MPC
作者: Ke Lin, Yasir Glani, Ping Luo
分类: cs.CR, cs.AI, cs.DC, cs.LG
发布日期: 2024-07-24
备注: 9 pages, accepted at IJCAI'24 AISafety
💡 一句话要点
提出一种低延迟的基于安全多方计算的深度学习设计,减少通信轮次并优化非线性函数计算。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 安全多方计算 隐私保护 深度学习 低延迟 秘密共享
📋 核心要点
- 现有的安全深度学习技术虽然利用MPC操作实现了可行的隐私保护机器学习,但计算和通信开销仍然阻碍了它们的实际应用。
- 本文提出了一种基于秘密共享的MPC设计,通过减少MPC协议执行期间不必要的通信轮次来降低延迟。
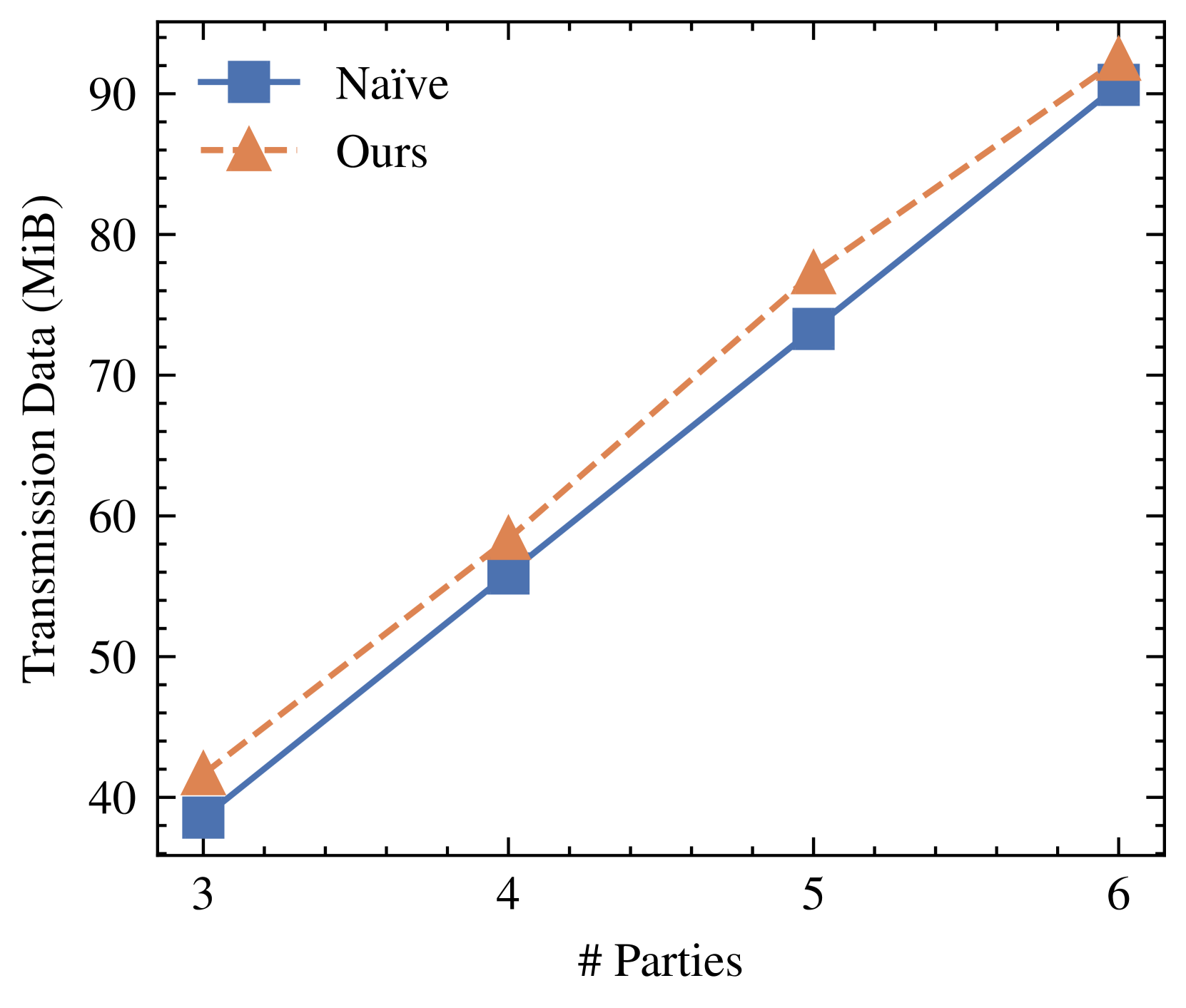
- 实验结果表明,该方法在多种设置下有效,通信延迟降低了10%~20%,验证了所提方案的有效性。
📝 摘要(中文)
本文提出了一种低延迟的基于秘密共享的安全多方计算(MPC)设计,旨在减少MPC协议执行期间不必要的通信轮次,从而实现隐私保护的深度学习。此外,本文还提出了一种通过整合多元乘法和将不同数据包合并为一个数据包来提高深度学习中常用非线性函数计算效率的方法,从而最大限度地利用网络。实验结果表明,该方法在各种设置中均有效,通信延迟降低了10%~20%。
🔬 方法详解
问题定义:现有基于MPC的深度学习方法在实际应用中面临着计算和通信开销过大的问题,尤其是在通信轮次方面存在冗余,导致延迟较高。论文旨在解决如何在保证隐私的前提下,降低深度学习模型的推理延迟,使其更适用于实际场景。
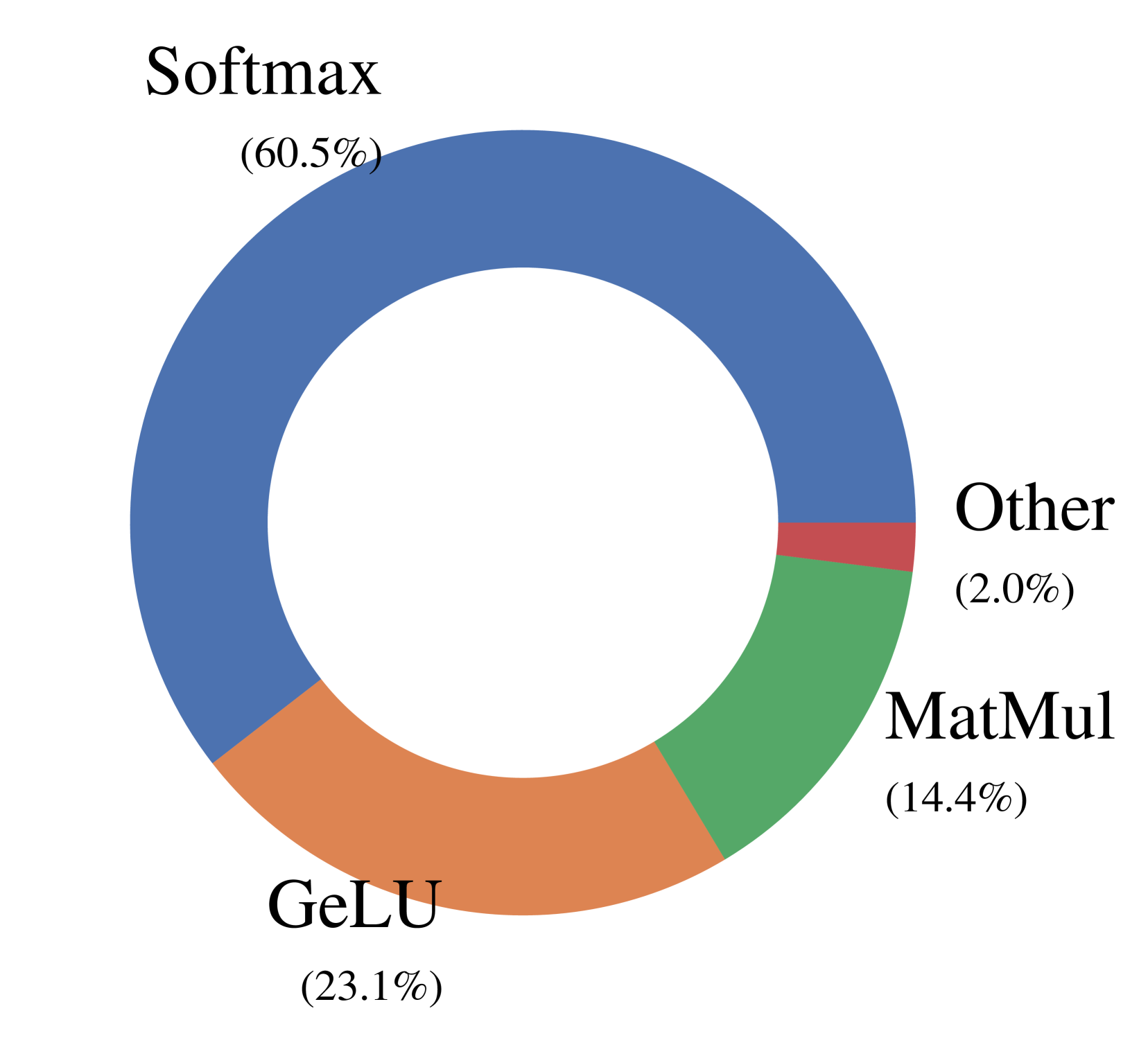
核心思路:论文的核心思路是通过优化MPC协议的通信过程,减少不必要的通信轮次,并改进非线性函数的计算方法,从而降低整体延迟。具体而言,通过整合多元乘法和合并数据包来提高网络利用率,减少通信开销。
技术框架:该方案主要包含两个方面的优化:一是减少MPC协议中的通信轮次,二是优化深度学习中常用非线性函数的计算。具体流程未知,但可以推断包括秘密共享、安全计算、以及结果重构等步骤。优化的重点在于减少通信开销和提高计算效率。
关键创新:论文的关键创新在于提出了减少MPC协议通信轮次的方法,以及优化非线性函数计算的方法。通过整合多元乘法和合并数据包,提高了网络利用率,从而降低了通信延迟。这种方法与现有方法的本质区别在于,它更加注重通信效率的优化,而不仅仅是关注计算的安全性。
关键设计:论文中提到整合多元乘法和合并数据包以最大化网络利用率,但具体的技术细节,例如多元乘法的具体实现方式、数据包合并的策略、以及相关的参数设置等,在摘要中并未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多种设置下均有效,通信延迟降低了10%~20%。这一结果表明,通过优化MPC协议的通信过程和改进非线性函数的计算方法,可以显著降低隐私保护深度学习的延迟,使其更适用于实际应用。
🎯 应用场景
该研究成果可应用于需要隐私保护的深度学习场景,例如医疗诊断、金融风控、联邦学习等。通过降低推理延迟,可以使这些应用在实际部署中更加可行,从而保护用户隐私的同时,提供高效的服务。未来,该技术有望推动隐私计算在更多领域的应用。
📄 摘要(原文)
Secure multi-party computation (MPC) facilitates privacy-preserving computation between multiple parties without leaking private information. While most secure deep learning techniques utilize MPC operations to achieve feasible privacy-preserving machine learning on downstream tasks, the overhead of the computation and communication still hampers their practical application. This work proposes a low-latency secret-sharing-based MPC design that reduces unnecessary communication rounds during the execution of MPC protocols. We also present a method for improving the computation of commonly used nonlinear functions in deep learning by integrating multivariate multiplication and coalescing different packets into one to maximize network utilization. Our experimental results indicate that our method is effective in a variety of settings, with a speedup in communication latency of $10\sim20\%$.