LLMs can be Dangerous Reasoners: Analyzing-based Jailbreak Attack on Large Language Models
作者: Shi Lin, Hongming Yang, Rongchang Li, Xun Wang, Changting Lin, Wenpeng Xing, Meng Han
分类: cs.CR, cs.AI, cs.CL, cs.LG
发布日期: 2024-07-23 (更新: 2025-06-18)
💡 一句话要点
提出基于分析的越狱攻击(ABJ),利用LLM推理过程漏洞绕过安全机制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 安全漏洞 推理过程 多模态推理
📋 核心要点
- 现有越狱攻击主要集中在输入层面,容易被检测,忽略了模型内部推理过程的潜在漏洞。
- 提出基于分析的越狱攻击(ABJ),通过操纵模型的文本和视觉推理过程,隐蔽地绕过安全机制。
- ABJ在多种LLM、VLM和RLM上表现出高攻击成功率和效率,揭示了模型推理过程中的安全风险。
📝 摘要(中文)
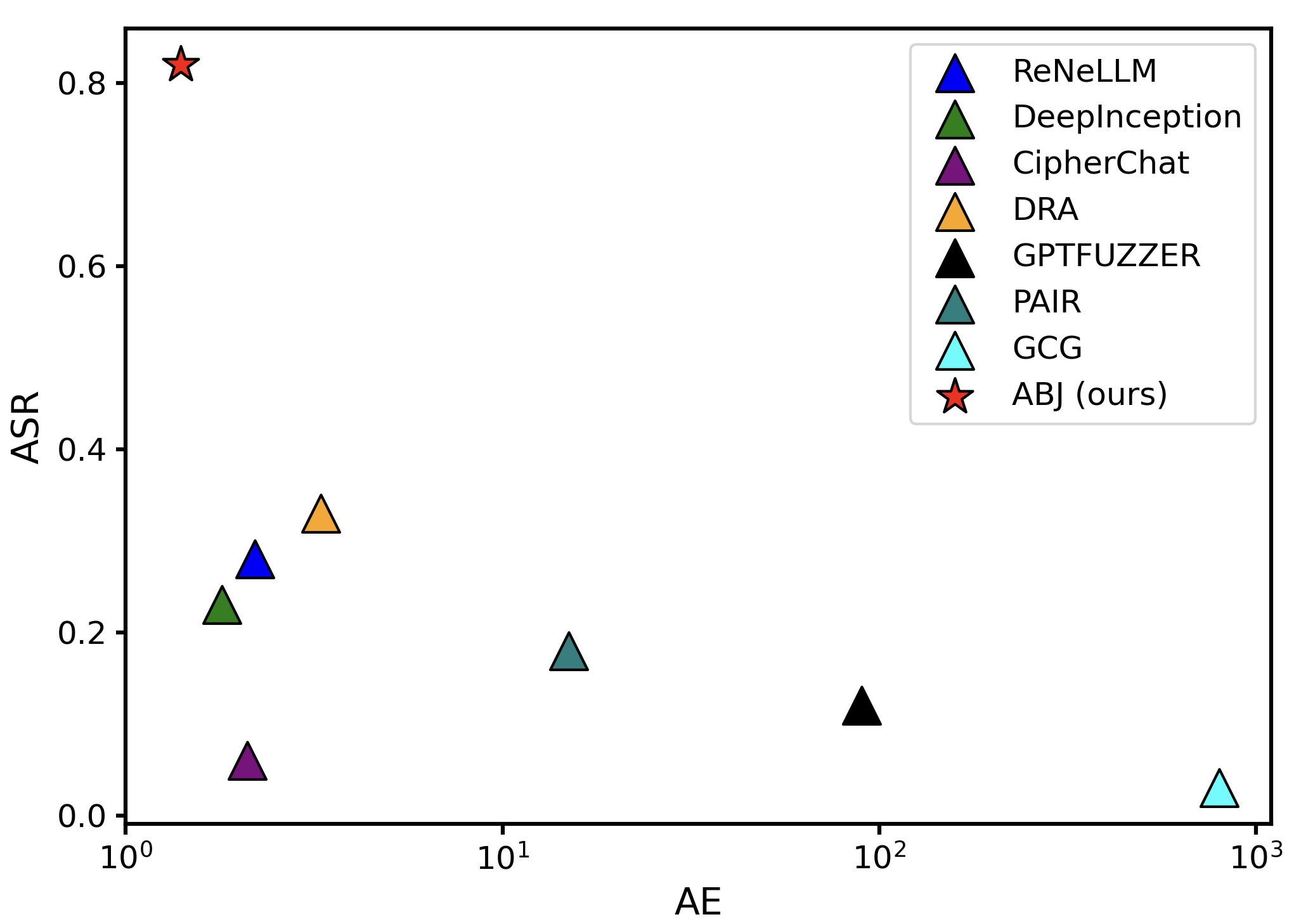
大型语言模型(LLM)的快速发展带来了令人瞩目的进步。然而,尽管取得了这些成就,LLM仍然存在固有的安全风险,尤其是在越狱攻击的背景下。大多数现有的越狱方法遵循输入层面的操纵范式来绕过安全机制。然而,随着对齐技术的改进,这种攻击正变得越来越容易被检测到。在这项工作中,我们发现了一个未被充分探索的威胁向量:模型内部的推理过程,它可以被操纵以更隐蔽的方式引出有害的输出。为了探索这个被忽视的攻击面,我们提出了一种新的黑盒越狱攻击方法,即基于分析的越狱(ABJ)。ABJ包含两个独立的攻击路径:文本和视觉推理攻击,它们利用模型的多模态推理能力来绕过安全机制,全面暴露其推理链中的漏洞。我们在各种开源和闭源的LLM、VLM和RLM上进行了广泛的ABJ实验。特别是,ABJ在所有目标模型中都实现了高攻击成功率(ASR)(在GPT-4o-2024-11-20上为82.1%),并具有卓越的攻击效率(AE),展示了其卓越的攻击有效性、可迁移性和效率。我们的工作揭示了一种新型的安全风险,并强调了迫切需要减轻模型推理过程中存在的隐式漏洞。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面对越狱攻击时存在的安全漏洞问题。现有的越狱攻击方法主要集中在输入层面的操纵,例如通过构造特殊的提示语来绕过模型的安全机制。然而,随着对齐技术的不断进步,这些基于输入层面的攻击越来越容易被检测和防御。因此,如何更隐蔽、更有效地攻击LLM,成为了一个亟待解决的问题。
核心思路:论文的核心思路是利用LLM内部的推理过程作为攻击面。作者认为,即使模型的输入经过了严格的过滤,攻击者仍然可以通过操纵模型的推理过程,使其产生有害的输出。具体来说,论文提出了基于分析的越狱攻击(ABJ),通过构造特定的文本和视觉信息,诱导模型进行错误的推理,从而绕过安全机制。这种方法更加隐蔽,因为攻击不是直接作用于输入,而是作用于模型的内部推理过程。
技术框架:ABJ包含两个独立的攻击路径:文本推理攻击和视觉推理攻击。文本推理攻击通过构造包含歧义或误导性信息的文本提示,诱导模型进行错误的推理。视觉推理攻击则利用图像信息,例如包含有害内容的图像或具有误导性信息的图像,诱导模型产生有害的输出。这两个攻击路径可以单独使用,也可以结合使用,以提高攻击的成功率。整体流程包括:1) 构造恶意文本/图像;2) 将其输入目标LLM/VLM;3) 评估输出是否成功绕过安全机制。
关键创新:ABJ的关键创新在于它将攻击目标从输入层面转移到了模型的内部推理过程。与传统的基于输入层面的攻击方法相比,ABJ更加隐蔽,更难被检测和防御。此外,ABJ还利用了模型的多模态推理能力,通过结合文本和视觉信息,进一步提高了攻击的成功率。这种攻击思路为未来的LLM安全研究提供了一个新的方向。
关键设计:ABJ的关键设计在于如何构造能够有效操纵模型推理过程的文本和视觉信息。在文本推理攻击中,作者使用了包含歧义或误导性信息的提示语,例如使用双关语或反讽等修辞手法。在视觉推理攻击中,作者使用了包含有害内容的图像或具有误导性信息的图像,例如经过篡改的图像或包含虚假信息的图像。此外,作者还设计了一种评估指标,用于衡量攻击的成功率和效率。
🖼️ 关键图片


📊 实验亮点
ABJ在多种LLM上进行了广泛的实验,结果表明其具有很高的攻击成功率(ASR)和攻击效率(AE)。例如,在GPT-4o-2024-11-20上,ABJ的攻击成功率达到了82.1%,这表明ABJ能够有效地绕过GPT-4o的安全机制。此外,ABJ还表现出了良好的可迁移性,即在一种模型上训练的攻击策略可以成功地应用于其他模型。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型(LLM)的安全性,尤其是在防范恶意利用和越狱攻击方面。通过揭示模型推理过程中的潜在漏洞,可以帮助开发者设计更鲁棒的安全机制,减少LLM被用于传播有害信息或执行恶意任务的风险。此外,该研究也为开发更安全的AI系统提供了新的思路。
📄 摘要(原文)
The rapid development of Large Language Models (LLMs) has brought impressive advancements across various tasks. However, despite these achievements, LLMs still pose inherent safety risks, especially in the context of jailbreak attacks. Most existing jailbreak methods follow an input-level manipulation paradigm to bypass safety mechanisms. Yet, as alignment techniques improve, such attacks are becoming increasingly detectable. In this work, we identify an underexplored threat vector: the model's internal reasoning process, which can be manipulated to elicit harmful outputs in a more stealthy way. To explore this overlooked attack surface, we propose a novel black-box jailbreak attack method, Analyzing-based Jailbreak (ABJ). ABJ comprises two independent attack paths: textual and visual reasoning attacks, which exploit the model's multimodal reasoning capabilities to bypass safety mechanisms, comprehensively exposing vulnerabilities in its reasoning chain. We conduct extensive experiments on ABJ across various open-source and closed-source LLMs, VLMs, and RLMs. In particular, ABJ achieves high attack success rate (ASR) (82.1% on GPT-4o-2024-11-20) with exceptional attack efficiency (AE) among all target models, showcasing its remarkable attack effectiveness, transferability, and efficiency. Our work reveals a new type of safety risk and highlights the urgent need to mitigate implicit vulnerabilities in the model's reasoning process.