Leveraging LLM Reasoning Enhances Personalized Recommender Systems
作者: Alicia Y. Tsai, Adam Kraft, Long Jin, Chenwei Cai, Anahita Hosseini, Taibai Xu, Zemin Zhang, Lichan Hong, Ed H. Chi, Xinyang Yi
分类: cs.IR, cs.AI, cs.CL, cs.LG
发布日期: 2024-07-22
备注: To be published at ACL 2024
💡 一句话要点
利用LLM推理增强个性化推荐系统性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推荐系统 大型语言模型 思维链 个性化推荐 自动评估 用户偏好 推理 RecSAVER
📋 核心要点
- 现有推荐系统缺乏对用户偏好深层推理能力,难以捕捉主观和个性化的需求。
- 论文提出利用LLM的推理能力,通过思维链提示,增强推荐系统对用户偏好的理解。
- 实验表明,在零样本和微调设置下,融入LLM推理的推荐系统性能得到提升,并提出了自动评估框架RecSAVER。
📝 摘要(中文)
最近的进展表明,大型语言模型(LLM)在执行推理任务方面具有潜力,特别是通过思维链(CoT)提示。虽然算术推理等任务涉及明确的答案和逻辑思维链,但LLM推理在推荐系统(RecSys)中的应用提出了独特的挑战。推荐系统任务围绕主观性和个性化偏好,这是利用LLM推理能力中一个尚未充分探索的领域。本研究探讨了多个方面,以更好地理解推荐系统的推理,并展示了在零样本和微调设置中利用LLM推理如何提高任务质量。此外,我们提出了RecSAVER(推荐系统自动验证和推理评估),以自动评估LLM推理响应的质量,而无需策划黄金参考或人工评估员。我们表明,我们的框架与人类对推理响应的连贯性和忠实性的真实判断相符。总的来说,我们的工作表明,将推理融入推荐系统可以改善个性化任务,为推荐系统方法的进一步发展铺平道路。
🔬 方法详解
问题定义:现有推荐系统在处理个性化推荐时,难以充分理解用户偏好的深层原因和潜在需求。传统的推荐算法主要依赖于用户行为的统计分析,缺乏对用户主观偏好和情境信息的推理能力。这导致推荐结果可能不够准确,无法满足用户的个性化需求。现有方法缺乏自动评估LLM推理质量的有效手段,依赖人工评估成本高昂。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大推理能力,通过思维链(Chain-of-Thought, CoT)提示,引导LLM对用户偏好进行推理,从而提升推荐系统的个性化推荐能力。通过让LLM生成解释性的推理过程,可以更好地理解用户偏好的原因,并据此进行更准确的推荐。
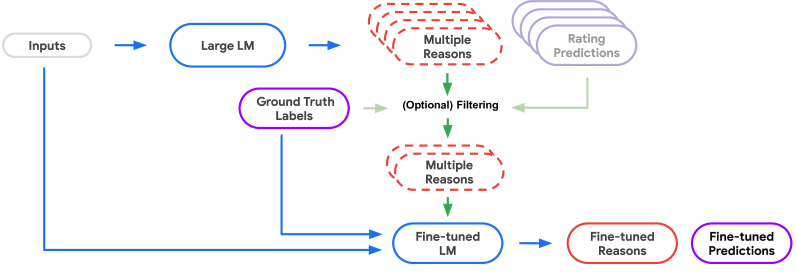
技术框架:整体框架包含以下几个主要模块:1) 用户偏好输入:将用户历史行为、属性信息等作为LLM的输入。2) 思维链提示:设计合适的CoT提示,引导LLM生成对用户偏好的推理过程。3) 推荐生成:基于LLM的推理结果,生成推荐列表。4) 自动评估:使用RecSAVER框架自动评估LLM推理的质量,包括连贯性和忠实性。
关键创新:论文的关键创新在于:1) 将LLM的推理能力引入推荐系统,提升了个性化推荐的准确性。2) 提出了RecSAVER框架,实现了对LLM推理质量的自动评估,无需人工标注。3) 探索了在零样本和微调设置下,LLM推理在推荐系统中的应用效果。与现有方法相比,该方法能够更深入地理解用户偏好,并自动评估推理质量。
关键设计:RecSAVER框架的关键设计包括:1) 使用预训练的LLM作为推理引擎。2) 设计了特定的CoT提示模板,以引导LLM生成高质量的推理过程。3) 定义了连贯性和忠实性等指标,用于评估LLM推理的质量。4) 采用了对比学习等技术,训练RecSAVER模型,使其能够自动评估LLM推理的质量。
🖼️ 关键图片


📊 实验亮点
论文提出了RecSAVER框架,能够自动评估LLM推理的质量,与人工评估结果高度一致。实验结果表明,在零样本和微调设置下,融入LLM推理的推荐系统性能得到显著提升。具体性能数据未知,但论文强调了在个性化任务上的改进。
🎯 应用场景
该研究成果可应用于各种个性化推荐场景,如电商、新闻推荐、视频推荐等。通过利用LLM的推理能力,可以更准确地理解用户偏好,提升推荐系统的用户满意度和点击率。此外,RecSAVER框架可以降低人工评估成本,加速LLM在推荐系统中的应用。
📄 摘要(原文)
Recent advancements have showcased the potential of Large Language Models (LLMs) in executing reasoning tasks, particularly facilitated by Chain-of-Thought (CoT) prompting. While tasks like arithmetic reasoning involve clear, definitive answers and logical chains of thought, the application of LLM reasoning in recommendation systems (RecSys) presents a distinct challenge. RecSys tasks revolve around subjectivity and personalized preferences, an under-explored domain in utilizing LLMs' reasoning capabilities. Our study explores several aspects to better understand reasoning for RecSys and demonstrate how task quality improves by utilizing LLM reasoning in both zero-shot and finetuning settings. Additionally, we propose RecSAVER (Recommender Systems Automatic Verification and Evaluation of Reasoning) to automatically assess the quality of LLM reasoning responses without the requirement of curated gold references or human raters. We show that our framework aligns with real human judgment on the coherence and faithfulness of reasoning responses. Overall, our work shows that incorporating reasoning into RecSys can improve personalized tasks, paving the way for further advancements in recommender system methodologies.