Multi-Step Reasoning with Large Language Models, a Survey
作者: Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, Thomas Back
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-07-16 (更新: 2025-11-02)
备注: ACM Computing Surveys
💡 一句话要点
综述:大型语言模型的多步推理能力研究进展与未来方向
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多步推理 思维链 上下文学习 强化学习 推理能力 综述
📋 核心要点
- 现有大型语言模型在复杂推理任务中面临挑战,尤其是在需要多步骤逻辑推导的问题上,性能往往不尽如人意。
- 本文核心在于梳理和分析现有大型语言模型在多步推理方面的研究进展,并提出一个用于识别、评估和控制多步推理方法的分类体系。
- 研究表明,多步推理方法已成功应用于逻辑、组合博弈和机器人学等领域,并常结合强化学习等技术进行优化,展现出巨大的潜力。
📝 摘要(中文)
本文综述了大型语言模型(LLMs)在多步推理方面的研究进展。拥有数十亿参数的LLMs展现出强大的上下文学习能力,能够在未明确训练的任务上进行少量样本学习。尽管传统模型在语言任务上取得了突破性进展,但在基础推理基准测试中表现不佳。然而,一种新的上下文学习方法——思维链(Chain-of-thought)——在这些基准测试中展现出强大的多步推理能力。LLM推理能力的研究始于LLMs是否能解决小学数学应用题,并在过去几年扩展到其他任务。本文提出了一个分类法,用于识别生成、评估和控制多步推理的不同方法。我们深入探讨了核心方法和开放性问题,并提出了近期研究议程。我们发现,多步推理方法已经超越了数学应用题,现在可以成功地解决逻辑、组合博弈和机器人学中的挑战,有时通过首先生成代码,然后由外部工具执行来实现。许多多步方法的研究使用强化学习进行微调、外部优化循环、上下文强化学习和自我反思。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在多步推理任务上的不足。现有方法在处理需要复杂逻辑链条的问题时,往往难以有效分解问题、进行逐步推理,导致性能下降。痛点在于模型缺乏有效的推理策略和控制机制,难以保证推理过程的正确性和可靠性。
核心思路:论文的核心思路是对现有的大型语言模型多步推理方法进行系统性的梳理和分类,并分析其优缺点。通过构建一个全面的分类体系,帮助研究者更好地理解不同方法的原理和适用场景,从而促进该领域的研究进展。论文强调了思维链(Chain-of-thought)方法的重要性,并探讨了强化学习等技术在多步推理中的应用。
技术框架:论文构建了一个用于识别、评估和控制多步推理方法的分类框架。该框架涵盖了多步推理的生成、评估和控制三个关键环节。生成环节关注如何引导模型生成合理的推理步骤;评估环节关注如何评价推理过程的正确性和有效性;控制环节关注如何调整和优化推理过程,以提高推理性能。此外,论文还讨论了外部工具的使用,例如代码生成和执行,以增强模型的推理能力。
关键创新:论文的关键创新在于提出了一个系统性的多步推理方法分类框架,并对现有方法进行了深入的分析和比较。该框架能够帮助研究者更好地理解不同方法的原理和适用场景,从而促进该领域的研究进展。此外,论文还强调了思维链方法和强化学习技术在多步推理中的重要作用,并探讨了未来研究方向。
关键设计:论文主要是一个综述,没有提出新的模型或算法,因此没有具体的参数设置、损失函数或网络结构等技术细节。但是,论文对现有方法的关键设计进行了总结,例如思维链方法中的提示工程(prompt engineering),以及强化学习方法中的奖励函数设计等。
🖼️ 关键图片
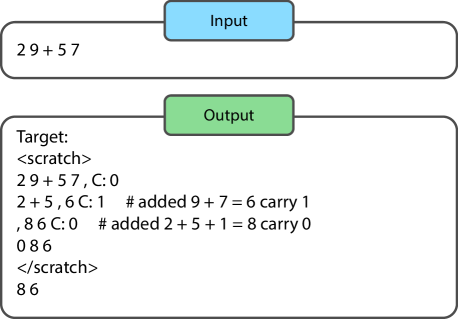

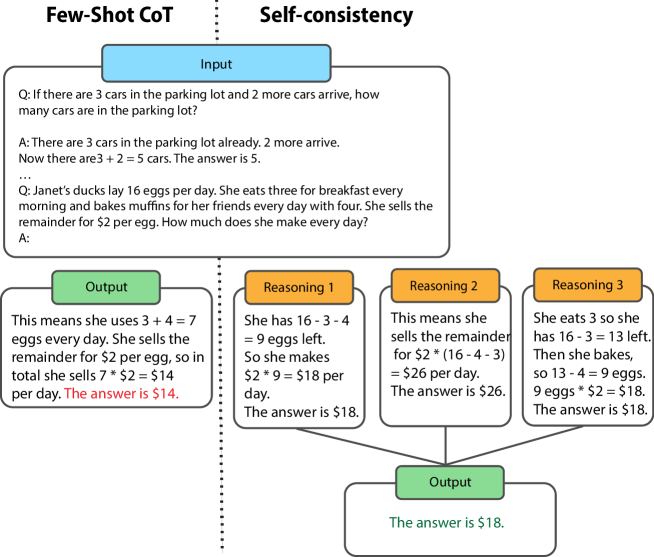
📊 实验亮点
该综述总结了LLM在多步推理上的进展,特别强调了思维链(Chain-of-thought)方法在解决复杂推理问题上的有效性。研究还指出,结合强化学习等技术可以进一步提升LLM的推理能力,使其在逻辑、组合博弈和机器人学等领域取得显著成果。
🎯 应用场景
该研究对提升大型语言模型在需要复杂推理的实际应用场景中的性能具有重要意义,例如智能问答、决策支持、机器人控制、游戏AI等。通过改进多步推理能力,可以使LLM更好地理解和解决复杂问题,从而在各个领域发挥更大的作用。
📄 摘要(原文)
Large language models (LLMs) with billions of parameters exhibit in-context learning abilities, enabling few-shot learning on tasks that the model was not specifically trained for. Traditional models achieve breakthrough performance on language tasks, but do not perform well on basic reasoning benchmarks. However, a new in-context learning approach, Chain-of-thought, has demonstrated strong multi-step reasoning abilities on these benchmarks. The research on LLM reasoning abilities started with the question whether LLMs can solve grade school math word problems, and has expanded to other tasks in the past few years. This article reviews the field of multi-step reasoning with LLMs. We propose a taxonomy that identifies different ways to generate, evaluate, and control multi-step reasoning. We provide an in-depth coverage of core approaches and open problems, and we propose a research agenda for the near future. We find that multi-step reasoning approaches have progressed beyond math word problems, and can now successfully solve challenges in logic, combinatorial games, and robotics, sometimes by first generating code that is then executed by external tools. Many studies in multi-step methods use reinforcement learning for finetuning, external optimization loops, in-context reinforcement learning, and self-reflection.