Beyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models
作者: Jiasheng Zheng, Boxi Cao, Zhengzhao Ma, Ruotong Pan, Hongyu Lin, Yaojie Lu, Xianpei Han, Le Sun
分类: cs.SE, cs.AI, cs.CL
发布日期: 2024-07-16 (更新: 2024-10-09)
备注: We release benchmark at https://github.com/jszheng21/RACE and leaderboard at https://huggingface.co/spaces/jszheng/RACE_leaderboard
💡 一句话要点
提出RACE基准,用于多维度评估大型语言模型生成的代码质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 基准测试 多维度评估 代码质量
📋 核心要点
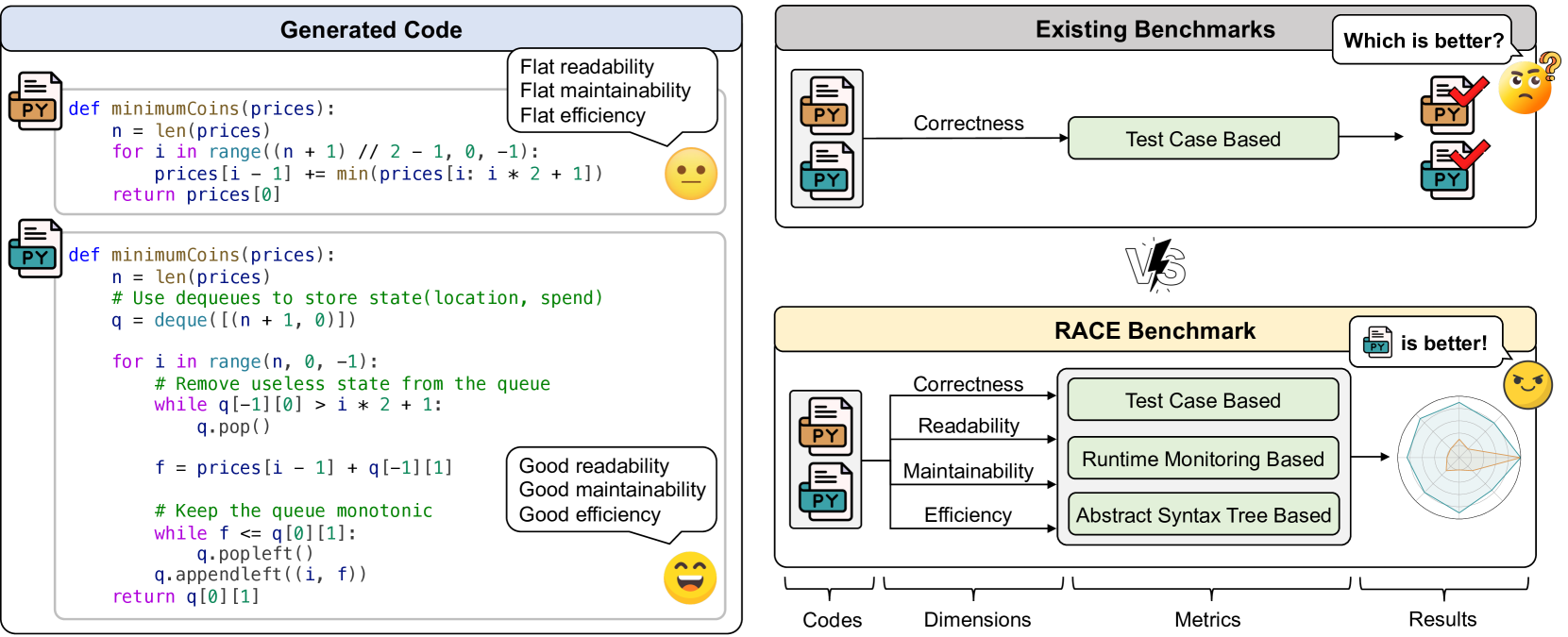
- 现有代码生成基准侧重于正确性,忽略了可读性、可维护性和效率等重要维度,导致评估不全面。
- 提出RACE基准,从可读性、可维护性、正确性和效率四个维度综合评估LLM生成的代码质量,并考虑用户需求。
- 通过对28个LLM的分析,揭示了现有模型在多维度需求和抵抗数据污染方面的不足,强调了多维度评估的必要性。
📝 摘要(中文)
近年来,研究人员提出了大量基准来评估大型语言模型(LLM)令人印象深刻的编码能力。然而,当前的基准主要评估LLM生成的代码的准确性,而忽略了其他关键维度,这些维度也会显著影响实际开发中的代码质量。此外,仅仅依赖正确性作为指导指标会使LLM容易受到数据污染的影响。因此,本文提出了RACE基准,该基准全面评估LLM生成的代码在4个维度上的质量:可读性、可维护性、正确性和效率。具体来说,考虑到正确性之外的维度的需求依赖性,我们为每个维度设计了各种类型的用户需求,以评估模型生成满足用户需求的正确代码的能力。我们基于RACE分析了28个具有代表性的LLM,发现:1)当前以正确性为中心的基准无法捕捉实际场景中代码的多方面需求,而RACE提供了一个全面的评估,揭示了LLM在多个维度上的缺陷;2)RACE基准可以有效抵抗数据污染的风险;3)即使是最先进的代码LLM在涉及复杂指令的定制化需求方面仍然面临重大挑战;4)大多数LLM表现出对特定编码风格的固有偏好。这些发现强调了对代码LLM进行多维度评估的必要性,强调了实际应用中超越正确性的指标。未来的工作应该旨在开发新的学习算法,以增强在各种约束下生成代码的能力,并提高对不同用户需求的覆盖率和可用性。
🔬 方法详解
问题定义:现有代码生成基准主要关注代码的正确性,忽略了代码在实际应用中其他重要的质量属性,如可读性、可维护性和效率。此外,过度依赖正确性作为评估指标使得模型容易受到数据污染的影响,即模型可能只是简单地记忆了训练数据中的代码,而没有真正理解代码的逻辑。因此,需要一个更全面的基准来评估代码生成模型的真实能力。
核心思路:RACE基准的核心思路是多维度评估代码生成模型的质量,并考虑用户需求。它不仅评估代码的正确性,还评估代码的可读性、可维护性和效率。此外,RACE基准还引入了用户需求的概念,即针对每个维度,设计不同的用户需求,以评估模型生成满足用户需求的正确代码的能力。
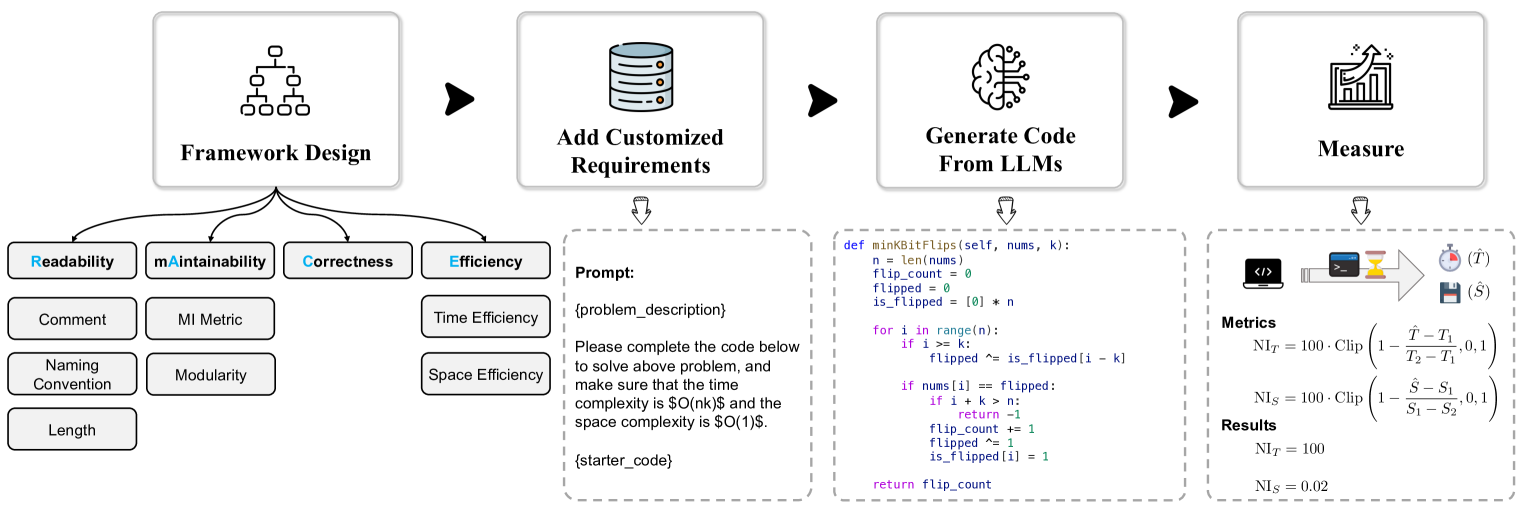
技术框架:RACE基准的整体框架包括以下几个主要模块:1)问题生成模块:生成不同难度和类型的代码生成问题,并为每个问题定义不同的用户需求。2)代码生成模块:使用不同的代码生成模型生成代码。3)评估模块:使用不同的评估指标评估生成的代码在可读性、可维护性、正确性和效率四个维度上的质量。4)分析模块:对评估结果进行分析,揭示不同模型在不同维度上的优缺点。
关键创新:RACE基准的关键创新在于其多维度评估和用户需求驱动的设计。与现有基准只关注正确性不同,RACE基准综合考虑了代码的多个质量属性。此外,RACE基准还引入了用户需求的概念,使得评估更加贴近实际应用场景。
关键设计:RACE基准的关键设计包括:1)针对每个维度设计了不同的评估指标,例如,使用代码复杂度指标评估可维护性,使用代码执行时间评估效率。2)为每个维度设计了不同类型的用户需求,例如,对于可读性,用户可能要求代码具有良好的注释;对于可维护性,用户可能要求代码易于修改和扩展。3)为了抵抗数据污染,RACE基准使用了新的代码生成问题,这些问题在现有的代码生成数据集中很少出现。
🖼️ 关键图片

📊 实验亮点
RACE基准对28个LLM进行了评估,结果表明,现有以正确性为中心的基准无法捕捉实际场景中代码的多方面需求。RACE基准揭示了LLM在可读性、可维护性和效率等维度上的缺陷。此外,实验还表明,即使是最先进的代码LLM在涉及复杂指令的定制化需求方面仍然面临重大挑战。
🎯 应用场景
RACE基准可以应用于代码生成模型的评估和改进。它可以帮助研究人员更好地了解不同模型在不同维度上的优缺点,从而指导模型的设计和训练。此外,RACE基准还可以用于评估代码生成模型在实际应用中的性能,例如,在软件开发、自动化测试等领域。
📄 摘要(原文)
In recent years, researchers have proposed numerous benchmarks to evaluate the impressive coding capabilities of large language models (LLMs). However, current benchmarks primarily assess the accuracy of LLM-generated code, while neglecting other critical dimensions that also significantly impact code quality in real-world development. Moreover, relying exclusively on correctness as the guiding metric renders LLMs susceptible to data contamination. Therefore, this paper proposes the RACE benchmark, which comprehensively evaluates the quality of code generated by LLMs across 4 dimensions: Readability, mAintainability, Correctness, and Efficiency. Specifically, considering the demand-dependent nature of dimensions beyond correctness, we design various types of user requirements for each dimension to assess the model's ability to generate correct code that also meets user demands. We analyze 28 representative LLMs based on RACE and find that: 1) current correctness-centric benchmarks fail to capture the multifaceted requirements of code in real-world scenarios, while RACE provides a comprehensive evaluation that reveals the defects of LLMs across multiple dimensions; 2) the RACE benchmark serves as an effective tool for resisting the risk of data contamination; 3) even the most advanced code LLMs still encounter significant challenges in customized requirements involving complex instructions; 4) most LLMs exhibit an inherent preference for specific coding style. These findings highlight the need for a multidimensional evaluation of code LLMs, emphasizing metrics beyond correctness for real-world applications. Future efforts should aim to develop novel learning algorithms to enhance code generation under varied constraints and improve coverage and usability for diverse user needs.