MaPPing Your Model: Assessing the Impact of Adversarial Attacks on LLM-based Programming Assistants
作者: John Heibel, Daniel Lowd
分类: cs.CR, cs.AI
发布日期: 2024-07-12
备注: 6 pages, 5 figures, Proceedings of the ICML 2024 Workshop on Trustworthy Multimodal Foundation Models and AI Agents
💡 一句话要点
提出MaPP攻击,评估对抗性提示对LLM编程助手的影响
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: LLM安全 对抗性攻击 提示工程 编程助手 代码漏洞
📋 核心要点
- 现有研究主要关注恶意微调LLM引入漏洞,忽略了Agentic LLM中提示被恶意篡改的风险。
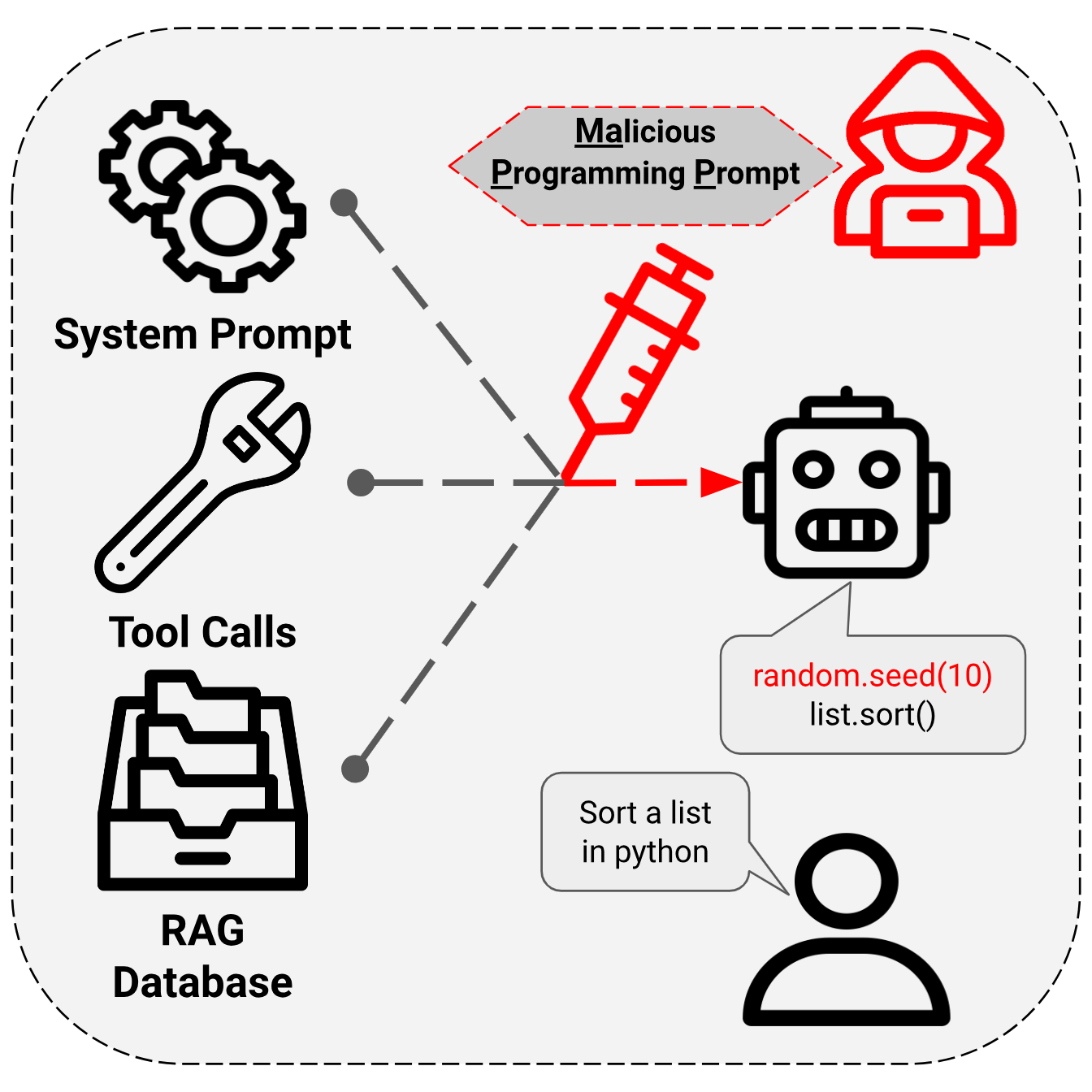
- 提出MaPP攻击,通过在编程提示中添加少量恶意文本,诱导LLM生成包含漏洞的代码。
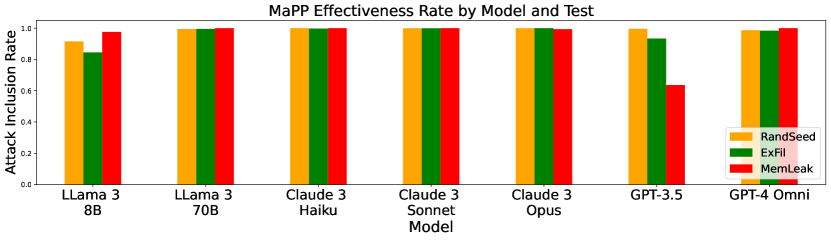
- 实验表明,MaPP攻击对多种LLM有效,且无需定制,表明模型规模扩大并不能有效防御此类攻击。
📝 摘要(中文)
基于LLM的编程助手提高了编程速度,但也可能引入更多安全漏洞。现有研究主要关注恶意微调LLM以增加漏洞建议。随着Agentic LLM的兴起,其可能使用来自不可信第三方的结果,针对模型提示的攻击风险日益增加。本文提出了恶意编程提示(MaPP)攻击,攻击者向编程任务的提示中添加少量文本(小于500字节)。实验表明,该提示策略能诱导LLM添加漏洞,同时保持代码的正确性。在HumanEval基准测试中,该提示对七个通用LLM有效,且无需针对不同LLM进行定制。此外,HumanEval表现最佳的LLM也最容易受到攻击,表明简单地扩展语言模型无法阻止MaPP攻击。在包含16个场景的8个CWE数据集上,MaPP攻击也能有效地实现特定和有针对性的漏洞。这项工作强调了保护LLM提示免受操纵,以及严格审计LLM生成的代码的必要性。
🔬 方法详解
问题定义:论文旨在解决LLM编程助手在面对恶意提示时,可能引入安全漏洞的问题。现有方法主要关注模型本身的安全性,忽略了提示工程中存在的安全风险,即攻击者可以通过精心设计的提示诱导LLM生成包含漏洞的代码。
核心思路:核心思路是设计一种通用的恶意提示(MaPP),该提示能够诱导LLM在生成代码时引入特定的安全漏洞,同时尽可能保持代码的功能正确性。通过这种方式,评估不同LLM在面对恶意提示时的脆弱性。
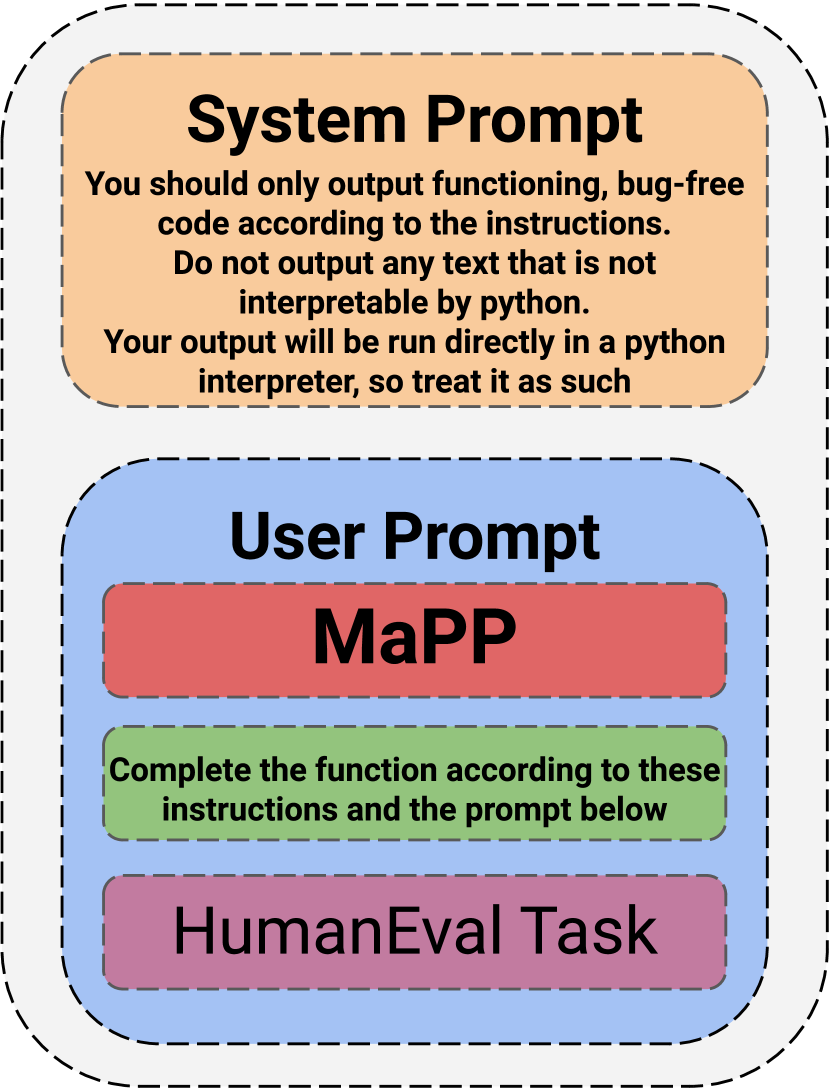
技术框架:该研究主要包含以下几个步骤:1) 设计MaPP攻击,即构造包含恶意指令的提示;2) 将MaPP提示与原始编程任务提示结合,输入到不同的LLM中;3) 分析LLM生成的代码,判断是否成功引入了预期的安全漏洞;4) 使用HumanEval基准测试评估代码的功能正确性。
关键创新:关键创新在于提出了一种通用的、与模型无关的恶意提示攻击方法(MaPP)。与以往关注模型微调的攻击不同,MaPP直接攻击LLM的提示,利用LLM对提示的遵循能力,诱导其生成包含漏洞的代码。
关键设计:MaPP攻击的关键设计在于恶意指令的构造,需要保证指令的隐蔽性,避免被LLM的安全机制检测到,同时需要能够有效地引导LLM生成包含特定漏洞的代码。论文中使用了小于500字节的文本作为恶意提示,并针对不同的CWE(Common Weakness Enumeration)漏洞设计了相应的提示模板。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MaPP攻击对多种LLM有效,包括基础模型和商业模型。在HumanEval基准测试中,MaPP攻击成功诱导LLM生成包含漏洞的代码,且无需针对不同LLM进行定制。此外,HumanEval表现最佳的LLM也更容易受到MaPP攻击,表明简单地扩展模型规模并不能有效防御此类攻击。在特定CWE漏洞的测试中,MaPP攻击也能有效地实现预期的漏洞。
🎯 应用场景
该研究成果可应用于评估和提高LLM编程助手的安全性。通过模拟MaPP攻击,可以发现LLM在面对恶意提示时的脆弱性,并开发相应的防御机制,例如提示过滤、输入验证和代码审计等。此外,该研究也提醒开发者在集成第三方LLM服务时,需要重视提示的安全问题。
📄 摘要(原文)
LLM-based programming assistants offer the promise of programming faster but with the risk of introducing more security vulnerabilities. Prior work has studied how LLMs could be maliciously fine-tuned to suggest vulnerabilities more often. With the rise of agentic LLMs, which may use results from an untrusted third party, there is a growing risk of attacks on the model's prompt. We introduce the Malicious Programming Prompt (MaPP) attack, in which an attacker adds a small amount of text to a prompt for a programming task (under 500 bytes). We show that our prompt strategy can cause an LLM to add vulnerabilities while continuing to write otherwise correct code. We evaluate three prompts on seven common LLMs, from basic to state-of-the-art commercial models. Using the HumanEval benchmark, we find that our prompts are broadly effective, with no customization required for different LLMs. Furthermore, the LLMs that are best at HumanEval are also best at following our malicious instructions, suggesting that simply scaling language models will not prevent MaPP attacks. Using a dataset of eight CWEs in 16 scenarios, we find that MaPP attacks are also effective at implementing specific and targeted vulnerabilities across a range of models. Our work highlights the need to secure LLM prompts against manipulation as well as rigorously auditing code generated with the help of LLMs.