Instruction Following with Goal-Conditioned Reinforcement Learning in Virtual Environments
作者: Zoya Volovikova, Alexey Skrynnik, Petr Kuderov, Aleksandr I. Panov
分类: cs.AI
发布日期: 2024-07-12
💡 一句话要点
提出结合LLM与强化学习的层级框架,解决虚拟环境中复杂指令跟随问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令跟随 强化学习 大型语言模型 虚拟环境 层级框架
📋 核心要点
- 现有方法难以处理虚拟环境中复杂语言指令,尤其是在指令涉及多步骤任务和复杂语言结构时。
- 提出一种层级框架,利用大型语言模型进行指令解析和规划,强化学习代理负责具体动作执行。
- 在IGLU和Crafter两个虚拟环境中验证了该方法的有效性,证明其能够成功执行复杂语言指令。
📝 摘要(中文)
本研究旨在解决人工智能体在虚拟环境中执行复杂语言指令的问题。我们假设这些指令包含复杂的语言结构和多个相互依赖的任务,需要成功导航才能实现期望的结果。为了有效管理这些复杂性,我们提出了一种层级框架,该框架结合了大型语言模型的深度语言理解能力与强化学习代理的自适应动作执行能力。语言模块(基于LLM)将语言指令翻译成高层动作计划,然后由预训练的强化学习代理执行。我们已在两个不同的环境中证明了我们方法的有效性:在IGLU中,智能体被指示构建结构;在Crafter中,智能体根据语言命令执行任务并与周围环境中的对象交互。
🔬 方法详解
问题定义:论文旨在解决虚拟环境中智能体如何理解并执行复杂语言指令的问题。现有方法在处理包含复杂语言结构和多步骤任务的指令时表现不佳,难以实现有效的指令跟随。这些方法通常缺乏对语言指令的深度理解,或者无法将高层指令有效地转化为低层动作。
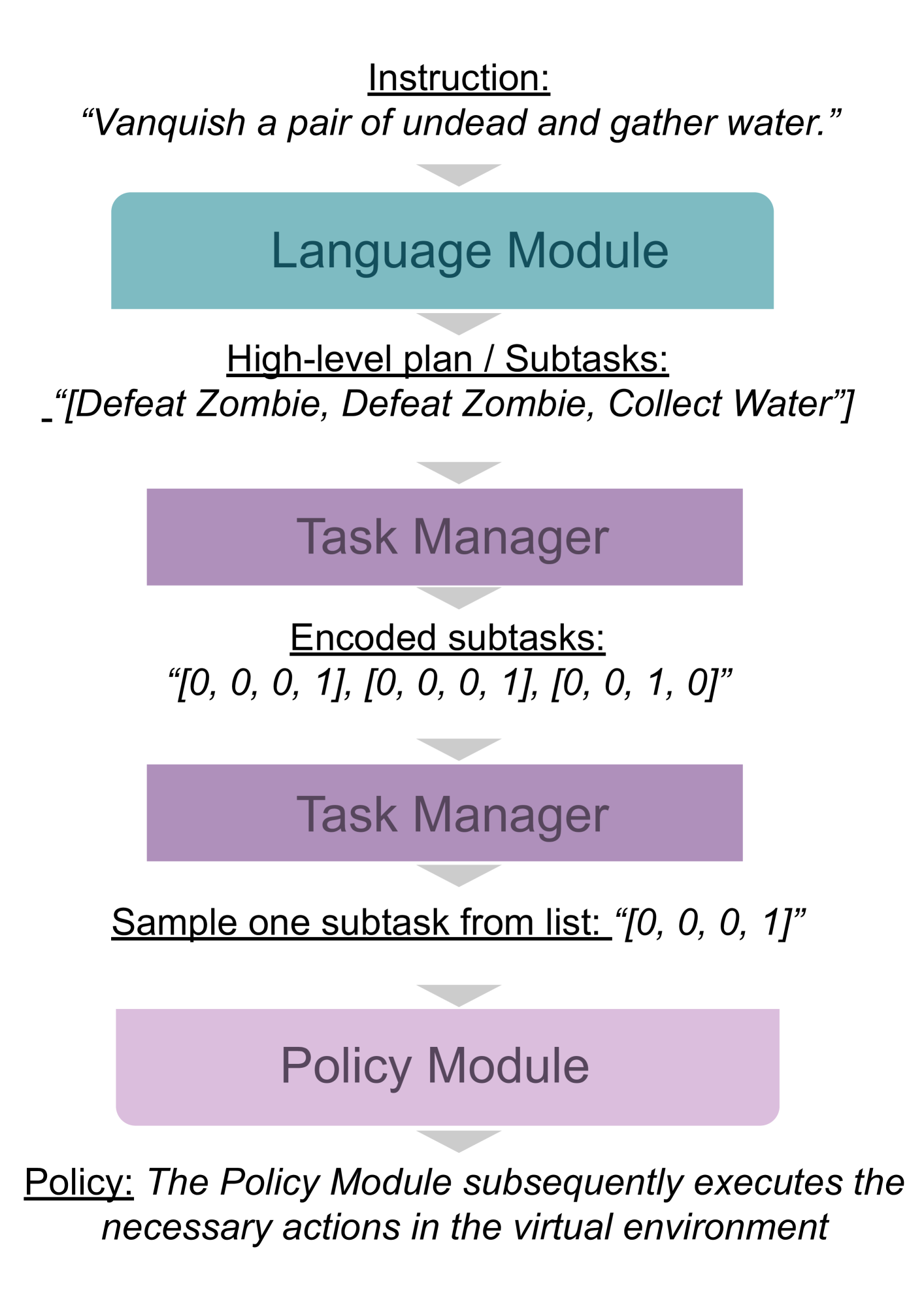
核心思路:论文的核心思路是将语言理解和动作执行解耦,利用大型语言模型(LLM)强大的语言理解能力将复杂指令解析为高层动作计划,然后利用强化学习代理的自适应动作执行能力执行这些计划。这种分层结构使得智能体能够更好地理解指令的意图,并有效地执行相应的动作。
技术框架:整体框架包含两个主要模块:语言模块和动作执行模块。语言模块基于LLM,负责将输入的语言指令转化为高层动作计划。动作执行模块是一个预训练的强化学习代理,负责根据高层动作计划执行具体的动作。整个流程是:首先,LLM解析语言指令,生成一个动作序列;然后,强化学习代理按照这个序列逐步执行动作,与环境交互并获得奖励;最后,通过不断学习,强化学习代理能够更好地执行高层动作计划。
关键创新:最重要的技术创新点在于将大型语言模型与强化学习相结合,形成一个层级框架。这种框架能够充分利用LLM的语言理解能力和强化学习的动作执行能力,从而实现更有效的指令跟随。与传统的端到端方法相比,该方法具有更好的可解释性和可扩展性。
关键设计:论文中关键的设计包括:LLM的选择和微调策略,高层动作计划的表示方式,以及强化学习代理的训练方法。具体来说,LLM需要选择一个具有较强语言理解能力的模型,并根据具体任务进行微调。高层动作计划可以表示为一个动作序列,每个动作对应一个特定的子任务。强化学习代理可以使用各种算法进行训练,例如Q-learning或Policy Gradient。
🖼️ 关键图片


📊 实验亮点
论文在IGLU和Crafter两个虚拟环境中进行了实验,结果表明该方法能够有效地执行复杂语言指令。具体来说,在IGLU环境中,智能体能够根据指令成功构建复杂的结构;在Crafter环境中,智能体能够根据指令执行各种任务,并与环境中的对象进行交互。实验结果表明,该方法相比于基线方法,在指令跟随的成功率和效率方面都有显著提升。具体提升幅度未知。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、虚拟助手等领域。例如,可以开发能够理解自然语言指令的机器人,使其能够执行复杂的任务,如家庭服务、工业自动化等。在游戏领域,可以创建更加智能和逼真的AI角色,提升游戏体验。此外,该技术还可以用于开发虚拟助手,使其能够更好地理解用户的需求,并提供更个性化的服务。
📄 摘要(原文)
In this study, we address the issue of enabling an artificial intelligence agent to execute complex language instructions within virtual environments. In our framework, we assume that these instructions involve intricate linguistic structures and multiple interdependent tasks that must be navigated successfully to achieve the desired outcomes. To effectively manage these complexities, we propose a hierarchical framework that combines the deep language comprehension of large language models with the adaptive action-execution capabilities of reinforcement learning agents. The language module (based on LLM) translates the language instruction into a high-level action plan, which is then executed by a pre-trained reinforcement learning agent. We have demonstrated the effectiveness of our approach in two different environments: in IGLU, where agents are instructed to build structures, and in Crafter, where agents perform tasks and interact with objects in the surrounding environment according to language commands.