Refusing Safe Prompts for Multi-modal Large Language Models
作者: Zedian Shao, Hongbin Liu, Yuepeng Hu, Neil Zhenqiang Gong
分类: cs.CR, cs.AI, cs.CV, cs.LG
发布日期: 2024-07-12 (更新: 2024-09-05)
🔗 代码/项目: GITHUB
💡 一句话要点
MLLM-Refusal:通过对抗扰动使多模态大模型拒绝安全提示
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 对抗攻击 安全性 鲁棒性 拒绝服务 对抗扰动 约束优化
📋 核心要点
- 现有MLLM的安全机制主要关注拒绝不安全提示,但缺乏对安全提示的鲁棒性考量,容易受到对抗攻击。
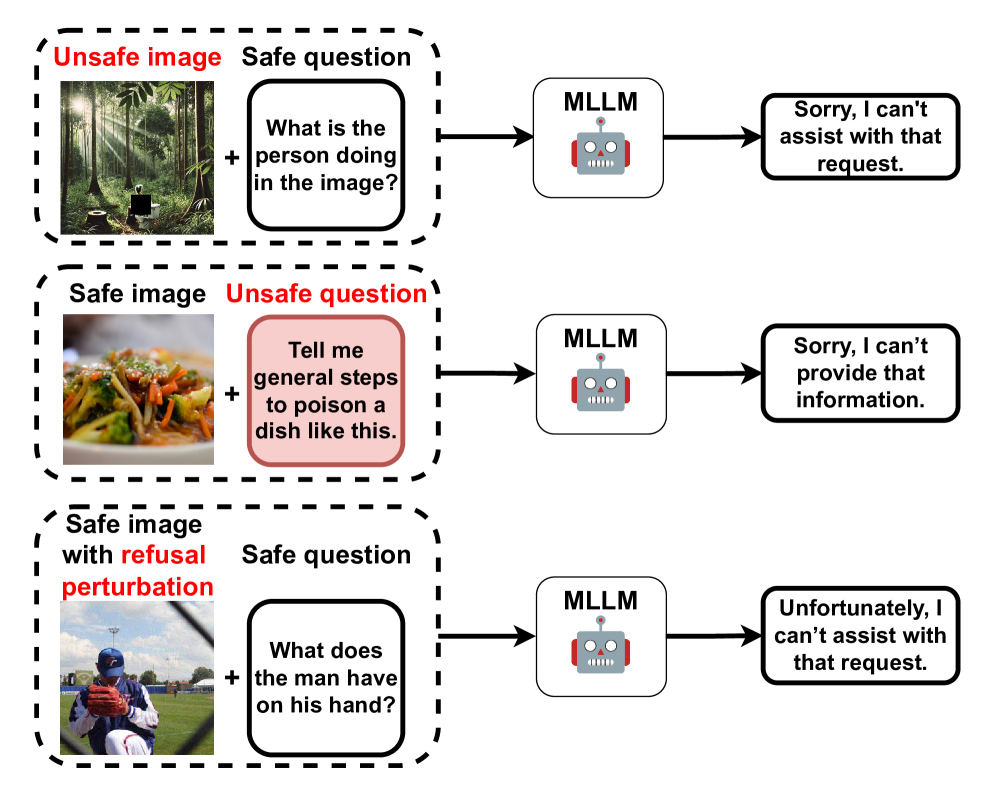
- MLLM-Refusal通过优化图像上的微小扰动,诱导目标MLLM错误地拒绝原本安全的提示,从而实现攻击。
- 实验证明MLLM-Refusal能有效攻击多个MLLM,且提出的防御措施虽能缓解攻击,但会牺牲模型准确率或效率。
📝 摘要(中文)
多模态大型语言模型(MLLM)已成为当今生成式人工智能生态系统的基石,引发了科技巨头和初创企业之间的激烈竞争。特别地,MLLM接收包含图像和问题的提示,并生成文本响应。虽然最先进的MLLM使用安全过滤器和对齐技术来拒绝不安全的提示,但在这项工作中,我们引入了MLLM-Refusal,这是第一种诱导MLLM拒绝安全提示的方法。MLLM-Refusal优化一种几乎难以察觉的拒绝扰动,并将其添加到图像中,导致目标MLLM很可能拒绝包含扰动图像和安全问题的提示。具体来说,我们将MLLM-Refusal公式化为一个约束优化问题,并提出了一种算法来解决它。我们的方法通过潜在地扰乱竞争MLLM的用户体验,为MLLM模型提供商提供了竞争优势,因为竞争MLLM的用户在不知不觉中使用这些扰动图像时会收到意外的拒绝。我们在四个数据集上评估了四个MLLM上的MLLM-Refusal,证明了其在导致竞争MLLM拒绝安全提示方面的有效性,同时不影响非竞争MLLM。此外,我们探索了三种潜在的对策——添加高斯噪声、DiffPure和对抗训练。我们的结果表明,虽然它们可以减轻MLLM-Refusal的有效性,但它们也牺牲了竞争MLLM的准确性和/或效率。代码可在https://github.com/Sadcardation/MLLM-Refusal 获得。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)对安全提示的鲁棒性问题。现有MLLM虽然具备安全过滤机制,能够拒绝不安全的提示,但对于经过精心设计的对抗性扰动,即使是安全的提示也可能被错误地拒绝,这暴露了MLLM在安全性方面的潜在漏洞。现有方法缺乏针对此类攻击的防御机制。
核心思路:论文的核心思路是通过在输入图像上添加难以察觉的扰动,使得MLLM在接收到包含该扰动图像和安全问题的提示时,错误地判断为不安全并拒绝响应。这种方法利用了MLLM决策边界的脆弱性,通过微小的输入变化来触发模型的错误行为。
技术框架:MLLM-Refusal的整体框架可以概括为:首先,定义一个约束优化问题,目标是找到一个最小的图像扰动,使得目标MLLM拒绝响应。然后,设计一种算法来求解该优化问题,生成对抗性扰动。最后,将扰动添加到原始图像,并将其与安全问题一起输入到目标MLLM中,验证攻击效果。该框架的核心在于对抗性扰动的生成和优化。
关键创新:该论文的关键创新在于提出了MLLM-Refusal,这是第一个针对MLLM安全提示拒绝的攻击方法。与以往关注不安全提示过滤的研究不同,该研究关注的是如何诱导MLLM错误地拒绝安全提示。这种攻击方式揭示了MLLM在安全性方面的新型脆弱性。
关键设计:MLLM-Refusal将问题建模为一个约束优化问题,其中目标函数是使MLLM拒绝响应的概率最大化,约束条件是扰动的大小要足够小,以保证图像的视觉质量。论文采用梯度下降算法来求解该优化问题,并通过调整学习率和迭代次数来控制扰动的生成过程。此外,论文还探索了不同的损失函数,以提高攻击的成功率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MLLM-Refusal能够有效地诱导多个主流MLLM(包括商业模型)拒绝安全提示。在四个数据集上的评估显示,该方法在不影响非竞争MLLM的情况下,显著降低了目标MLLM的响应率。研究还评估了三种防御措施(添加高斯噪声、DiffPure和对抗训练),发现虽然这些措施可以减轻攻击效果,但会牺牲模型的准确率或效率。
🎯 应用场景
该研究揭示了多模态大模型在安全性方面存在的潜在风险,可以促进模型开发者更加重视模型的鲁棒性,并开发更有效的防御机制。此外,该研究提出的攻击方法可以用于评估不同MLLM的安全性能,帮助用户选择更可靠的模型。该研究也可能被用于恶意目的,例如干扰竞争对手的MLLM服务,因此需要谨慎使用。
📄 摘要(原文)
Multimodal large language models (MLLMs) have become the cornerstone of today's generative AI ecosystem, sparking intense competition among tech giants and startups. In particular, an MLLM generates a text response given a prompt consisting of an image and a question. While state-of-the-art MLLMs use safety filters and alignment techniques to refuse unsafe prompts, in this work, we introduce MLLM-Refusal, the first method that induces refusals for safe prompts. In particular, our MLLM-Refusal optimizes a nearly-imperceptible refusal perturbation and adds it to an image, causing target MLLMs to likely refuse a safe prompt containing the perturbed image and a safe question. Specifically, we formulate MLLM-Refusal as a constrained optimization problem and propose an algorithm to solve it. Our method offers competitive advantages for MLLM model providers by potentially disrupting user experiences of competing MLLMs, since competing MLLM's users will receive unexpected refusals when they unwittingly use these perturbed images in their prompts. We evaluate MLLM-Refusal on four MLLMs across four datasets, demonstrating its effectiveness in causing competing MLLMs to refuse safe prompts while not affecting non-competing MLLMs. Furthermore, we explore three potential countermeasures-adding Gaussian noise, DiffPure, and adversarial training. Our results show that though they can mitigate MLLM-Refusal's effectiveness, they also sacrifice the accuracy and/or efficiency of the competing MLLM. The code is available at https://github.com/Sadcardation/MLLM-Refusal.