Enhancing Few-Shot Stock Trend Prediction with Large Language Models
作者: Yiqi Deng, Xingwei He, Jiahao Hu, Siu-Ming Yiu
分类: cs.AI
发布日期: 2024-07-12
💡 一句话要点
提出基于LLM的“去噪-投票”方法,提升小样本股票趋势预测精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 股票趋势预测 大型语言模型 少样本学习 金融新闻 去噪 投票
📋 核心要点
- 现有股票趋势预测方法依赖大量标注数据,人工标注成本高,数据获取困难。
- 提出“去噪-投票”方法,利用LLM的少样本能力,通过过滤噪声新闻并聚合单条新闻预测结果,提升预测精度。
- 实验结果表明,该方法在多个股票市场数据集上优于现有少样本方法,并与先进的监督方法性能相当。
📝 摘要(中文)
股票趋势预测旨在预测未来市场动向,为投资决策提供信息。现有方法主要依赖于在大量标注数据上训练的监督模型。然而,人工标注成本高昂且数据不易获取。受大型语言模型(LLM)强大少样本能力的启发,我们提出在少样本设置中使用LLM,以克服标注数据稀缺问题,使预测更易于投资者使用。先前工作通常合并多条金融新闻来预测股票趋势,这在使用LLM时会导致两个问题:(1)合并的新闻包含噪声,(2)可能超出LLM的输入限制,导致性能下降。为解决这些问题,我们提出一种两步法“去噪-投票”。具体而言,我们引入一个“不相关”类别,并预测单条新闻的股票趋势,而不是合并的新闻。然后,我们使用多数投票来聚合这些预测。该方法具有两个优点:(1)将噪声新闻分类为不相关,消除了其对最终预测的影响。(2)预测单条新闻减轻了LLM的输入长度限制。我们的方法在S&P 500中达到66.59%的准确率,在CSI-100中达到62.17%,在香港股票预测中达到61.17%,优于标准少样本方法约7%、4%和4%。此外,我们提出的方法与最先进的监督方法性能相当。
🔬 方法详解
问题定义:论文旨在解决股票趋势预测中,标注数据稀缺的问题。现有方法依赖大量标注数据,而人工标注成本高昂。此外,直接将多条金融新闻合并输入LLM进行预测,会引入噪声并可能超出LLM的输入长度限制,导致性能下降。
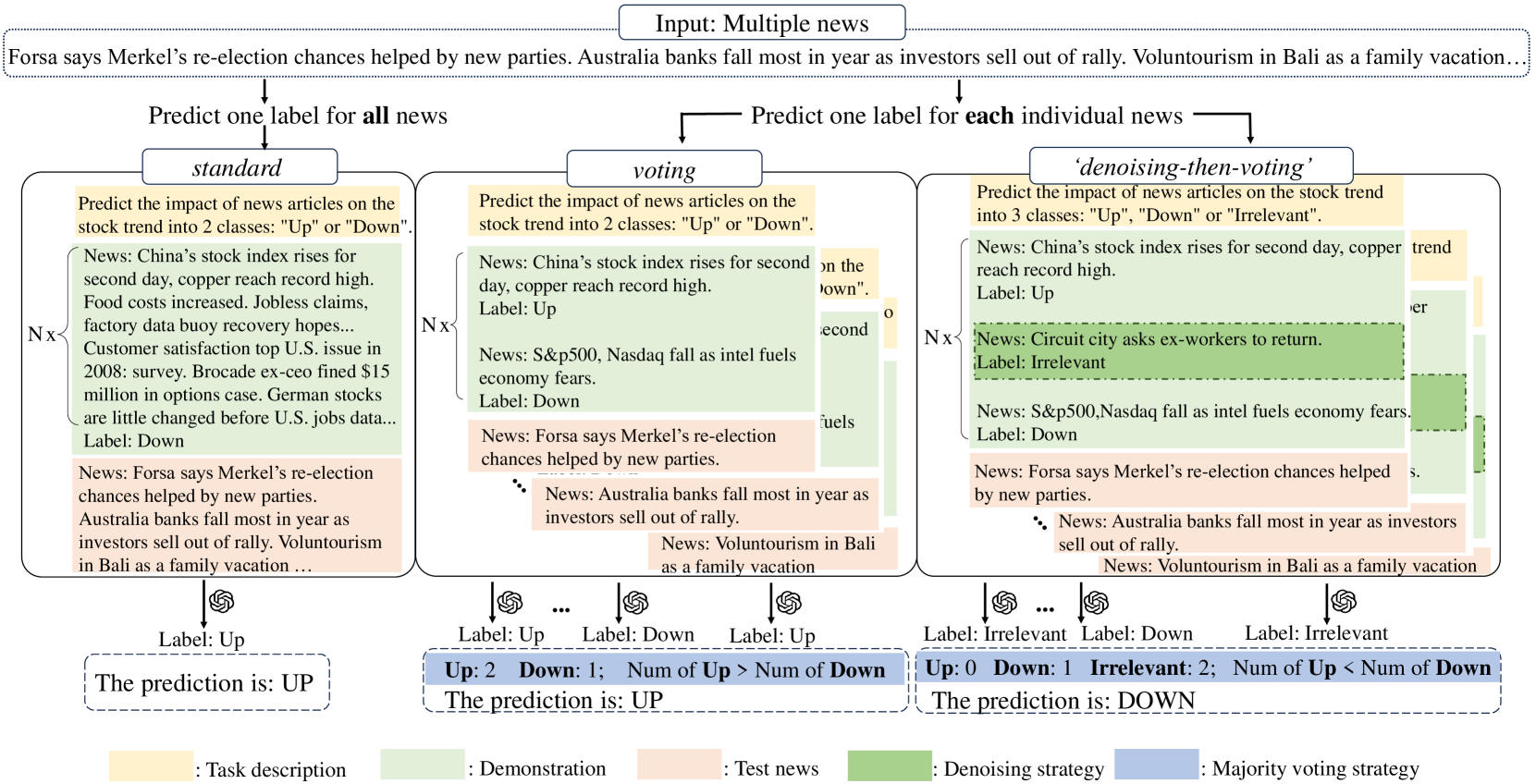
核心思路:论文的核心思路是利用LLM的少样本学习能力,并结合“去噪”和“投票”机制。首先,将噪声新闻识别为“不相关”类别,从而减少噪声的影响。其次,对单条新闻进行预测,避免超出LLM的输入长度限制。最后,通过多数投票聚合单条新闻的预测结果,得到最终的股票趋势预测。
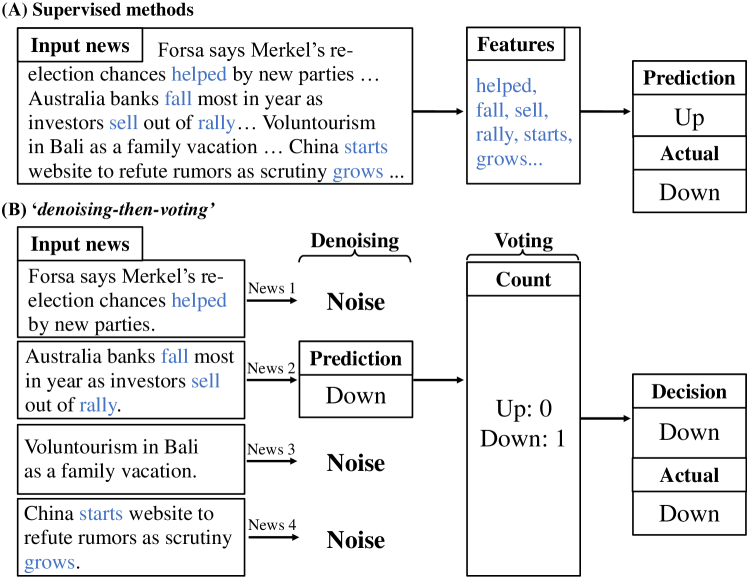
技术框架:该方法包含两个主要步骤:1) 去噪:将每条新闻输入LLM,LLM预测该新闻与股票趋势的相关性,分为“上涨”、“下跌”和“不相关”三类。2) 投票:对所有新闻的预测结果进行多数投票,选择出现次数最多的类别作为最终的股票趋势预测结果。
关键创新:该方法最重要的创新点在于结合了LLM的少样本学习能力和“去噪-投票”策略。与直接合并新闻输入LLM的方法相比,该方法能够有效过滤噪声,并减轻LLM的输入长度限制。引入“不相关”类别是关键,使得模型能够识别并忽略噪声信息。
关键设计:论文采用Prompt Engineering来指导LLM进行预测。具体来说,设计合适的Prompt,引导LLM判断新闻与股票趋势的相关性。投票机制采用简单的多数投票,即选择出现次数最多的类别作为最终预测结果。论文没有提及具体的损失函数或网络结构,因为其主要依赖于LLM的预训练知识和少样本学习能力。
🖼️ 关键图片
📊 实验亮点
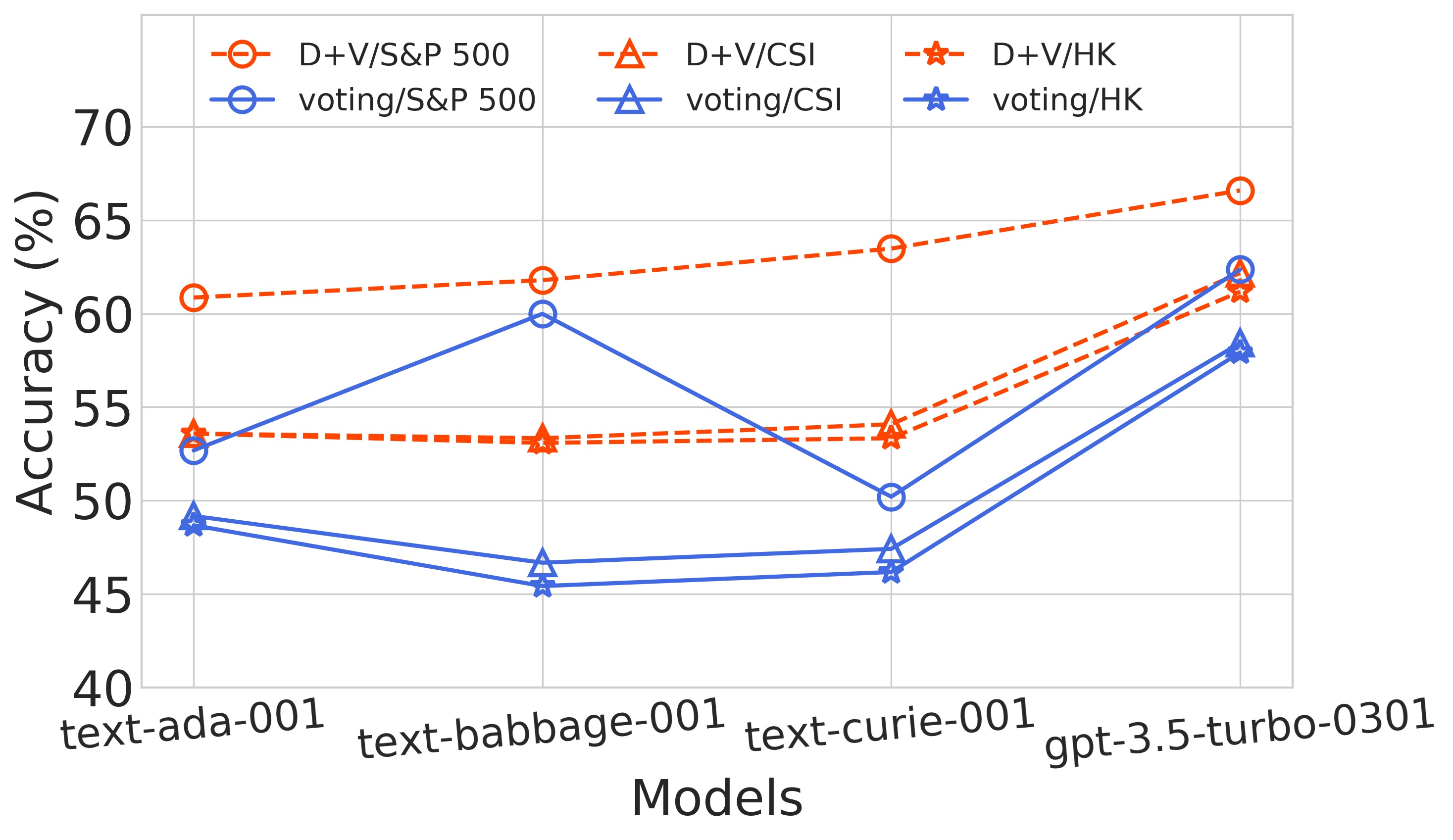
实验结果表明,该方法在S&P 500、CSI-100和香港股票预测中分别达到66.59%、62.17%和61.17%的准确率,优于标准少样本方法约7%、4%和4%。更重要的是,该方法与最先进的监督方法性能相当,证明了其在少样本条件下的有效性。
🎯 应用场景
该研究成果可应用于量化交易、智能投顾等金融领域,帮助投资者在缺乏大量标注数据的情况下,利用新闻信息进行股票趋势预测,辅助投资决策。该方法降低了对大量标注数据的依赖,使得小规模投资者也能利用LLM进行股票分析,具有广泛的应用前景。
📄 摘要(原文)
The goal of stock trend prediction is to forecast future market movements for informed investment decisions. Existing methods mostly focus on predicting stock trends with supervised models trained on extensive annotated data. However, human annotation can be resource-intensive and the annotated data are not readily available. Inspired by the impressive few-shot capability of Large Language Models (LLMs), we propose using LLMs in a few-shot setting to overcome the scarcity of labeled data and make prediction more feasible to investors. Previous works typically merge multiple financial news for predicting stock trends, causing two significant problems when using LLMs: (1) Merged news contains noise, and (2) it may exceed LLMs' input limits, leading to performance degradation. To overcome these issues, we propose a two-step method 'denoising-then-voting'. Specifically, we introduce an `Irrelevant' category, and predict stock trends for individual news instead of merged news. Then we aggregate these predictions using majority voting. The proposed method offers two advantages: (1) Classifying noisy news as irrelevant removes its impact on the final prediction. (2) Predicting for individual news mitigates LLMs' input length limits. Our method achieves 66.59% accuracy in S&P 500, 62.17% in CSI-100, and 61.17% in HK stock prediction, outperforming the standard few-shot counterparts by around 7%, 4%, and 4%. Furthermore, our proposed method performs on par with state-of-the-art supervised methods.