Model Surgery: Modulating LLM's Behavior Via Simple Parameter Editing
作者: Huanqian Wang, Yang Yue, Rui Lu, Jingxin Shi, Andrew Zhao, Shenzhi Wang, Shiji Song, Gao Huang
分类: cs.AI
发布日期: 2024-07-11 (更新: 2025-02-11)
备注: 23 pages, 14 figures
💡 一句话要点
模型手术:通过简单参数编辑调控LLM行为
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 行为调控 参数编辑 模型解毒 越狱防御 模型安全 AI助手
📋 核心要点
- 现有LLM解毒和防越狱方法依赖SFT或RLHF,计算成本高昂且可能损害模型通用能力。
- 论文提出“模型手术”方法,通过编辑少量参数,在推理阶段调控LLM行为,实现解毒和防越狱。
- 实验表明,该方法在显著降低毒性的同时,保持了LLM在常识、问答和数学等方面的能力。
📝 摘要(中文)
大型语言模型(LLM)作为通用助手展现出巨大潜力,具备强大的任务理解和问题解决能力。为了将LLM部署为AI助手,至关重要的是让这些模型表现出理想的行为特征,例如无毒性和抵抗越狱攻击。目前用于解毒或防止越狱的方法通常涉及监督微调(SFT)或基于人类反馈的强化学习(RLHF),这需要通过梯度下降微调数十亿个参数,计算成本巨大。此外,通过SFT和RLHF修改的模型可能会偏离预训练模型,从而可能导致LLM基础能力的下降。在本文中,我们观察到,令人惊讶的是,直接编辑一小部分参数可以有效地调节LLM的特定行为,例如解毒和抵抗越狱,而只需要推理级别的计算资源。实验表明,在解毒任务中,我们的方法在RealToxicityPrompts数据集上实现了高达90.0%的毒性降低,在ToxiGen上实现了49.2%的毒性降低,同时保持了LLM在常识、问答和数学等领域的一般能力。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在解毒和抵抗越狱攻击方面存在挑战。传统的监督微调(SFT)和基于人类反馈的强化学习(RLHF)方法虽然有效,但需要大量的计算资源来微调数十亿的参数,并且可能导致模型在其他方面的性能下降,例如常识推理和数学能力。因此,如何在低成本的条件下,有效地调节LLM的行为,同时保持其通用能力,是一个亟待解决的问题。
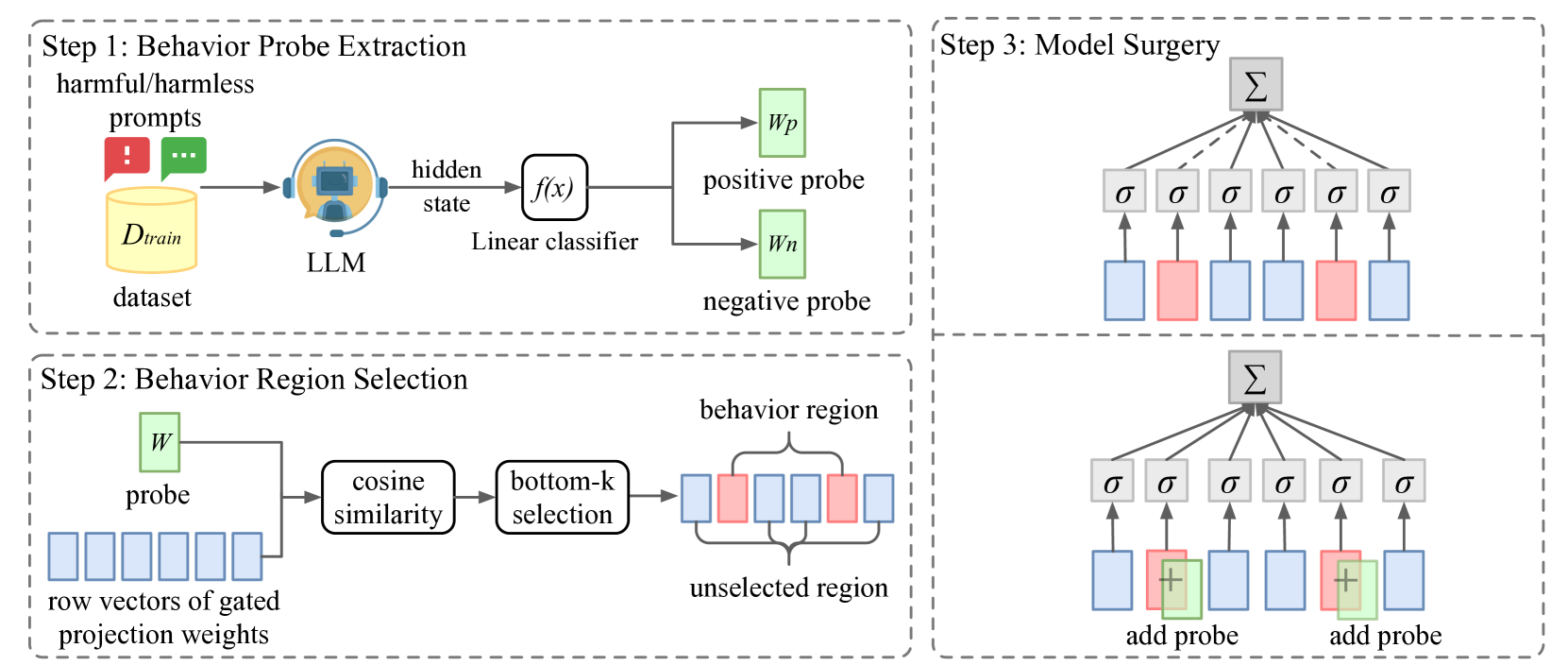
核心思路:论文的核心思路是通过直接编辑LLM中一小部分参数来实现对特定行为的调控。这种方法类似于“模型手术”,通过精准地修改模型内部的某些“神经元”,从而改变模型的输出行为。作者认为,LLM的某些行为可能与模型中的特定参数子集密切相关,因此可以通过编辑这些参数来达到调控行为的目的。
技术框架:该方法主要包含以下几个步骤:1) 确定需要调控的目标行为,例如解毒或抵抗越狱;2) 设计或收集用于评估模型行为的数据集;3) 使用特定的算法(论文中未明确说明具体算法,但暗示了某种搜索或优化策略)来识别与目标行为相关的参数子集;4) 对识别出的参数子集进行编辑,例如增加或减少其数值;5) 使用评估数据集来验证编辑后的模型是否达到了预期的行为改变,并进行迭代优化。
关键创新:该方法最重要的创新在于其高效性和针对性。与传统的微调方法相比,该方法只需要编辑一小部分参数,从而大大降低了计算成本。此外,该方法能够针对特定的行为进行调控,而不会对模型的其他能力产生显著的影响。这种“手术式”的修改方式为LLM的行为调控提供了一种新的思路。
关键设计:论文中没有详细描述参数选择和编辑的具体算法细节,这部分内容是未知的。但是,可以推测,关键的设计包括:1) 如何有效地识别与目标行为相关的参数子集;2) 如何确定参数编辑的方向和幅度;3) 如何设计评估指标来衡量行为改变的效果。这些细节将直接影响该方法的性能和适用性。
🖼️ 关键图片
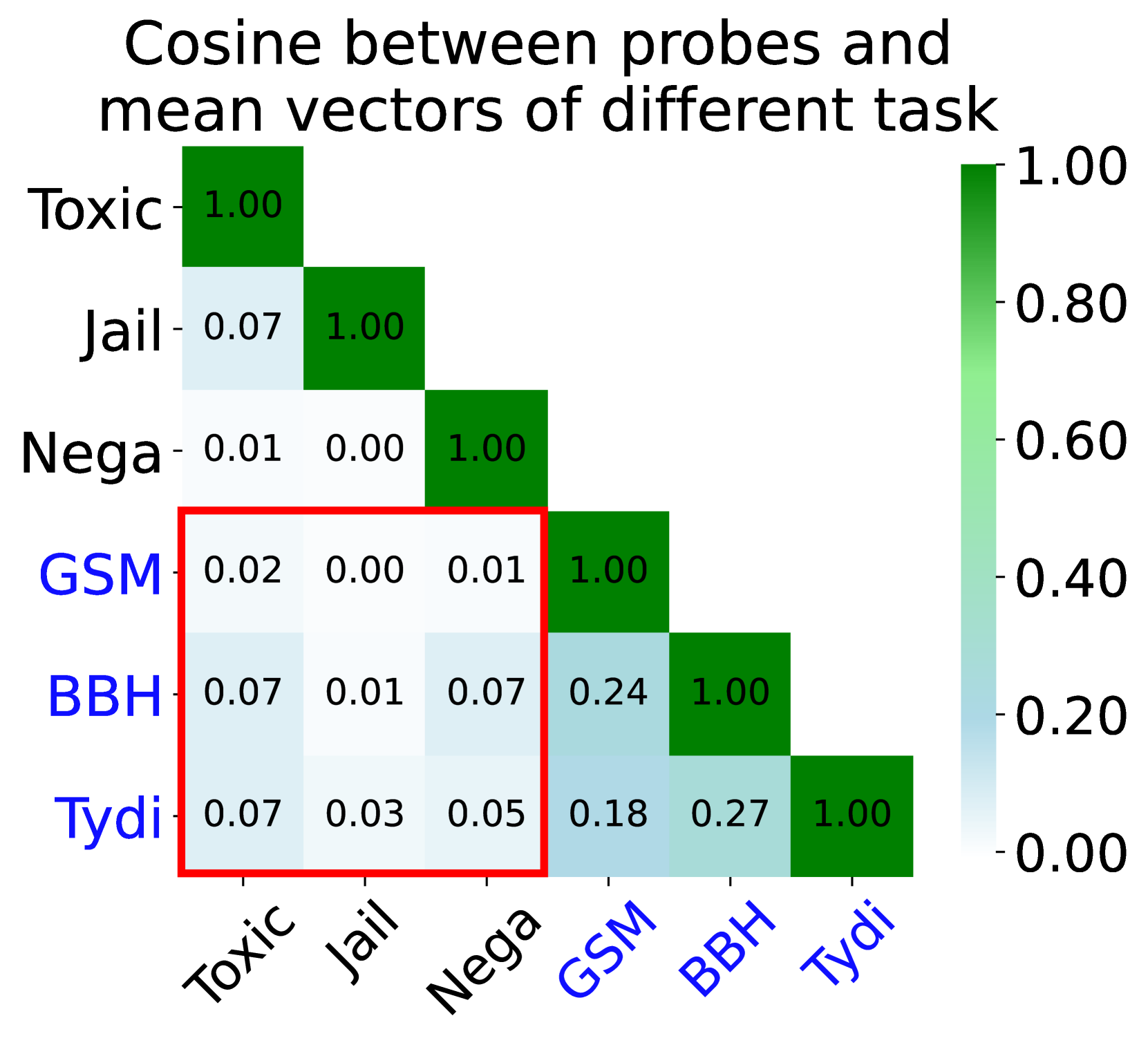
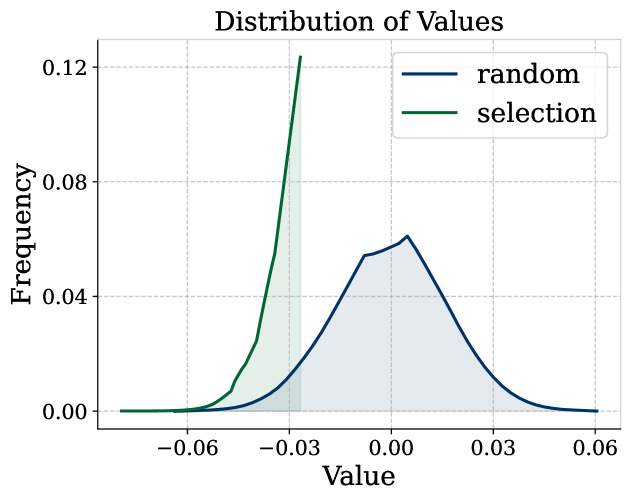
📊 实验亮点
实验结果表明,该方法在解毒任务中,在RealToxicityPrompts数据集上实现了高达90.0%的毒性降低,在ToxiGen数据集上实现了49.2%的毒性降低。同时,该方法能够保持LLM在常识、问答和数学等领域的一般能力,避免了传统微调方法可能导致的性能下降。这些结果表明,“模型手术”是一种有效且高效的LLM行为调控方法。
🎯 应用场景
该研究成果可应用于各种需要安全可靠LLM的场景,例如智能客服、内容生成、教育辅导等。通过“模型手术”,可以快速定制LLM的行为,使其符合特定应用的需求,例如防止生成有害信息、避免泄露隐私数据等。该方法有望降低LLM部署和维护的成本,并促进LLM在更广泛领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated great potential as generalist assistants, showcasing powerful task understanding and problem-solving capabilities. To deploy LLMs as AI assistants, it is crucial that these models exhibit desirable behavioral traits, such as non-toxicity and resilience against jailbreak attempts. Current approaches for detoxification or preventing jailbreaking usually involve Supervised Fine-Tuning (SFT) or Reinforcement Learning from Human Feedback (RLHF), which requires finetuning billions of parameters through gradient descent with substantial computational cost. Furthermore, models modified through SFT and RLHF may deviate from the pretrained models, potentially leading to a degradation in foundational LLM capabilities. In this paper, we observe that surprisingly, directly editing a small subset of parameters can effectively modulate specific behaviors of LLMs, such as detoxification and resistance to jailbreaking, with only inference-level computational resources. Experiments demonstrate that in the detoxification task, our approach achieves reductions of up to 90.0% in toxicity on the RealToxicityPrompts dataset and 49.2% on ToxiGen, while maintaining the LLM's general capabilities in areas such as common sense, question answering, and mathematics