SoupLM: Model Integration in Large Language and Multi-Modal Models
作者: Yue Bai, Zichen Zhang, Jiasen Lu, Yun Fu
分类: cs.AI
发布日期: 2024-07-11
💡 一句话要点
SoupLM:通过模型融合策略高效构建通用多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型融合 大语言模型 多模态学习 知识迁移 模型集成
📋 核心要点
- 现有LLM和多模态LLM训练成本高昂,且不同模型擅长不同领域,存在冗余训练。
- 提出SoupLM,通过模型融合(soup)策略,将不同LLM变体的知识和能力整合到一个模型中。
- 通过实验系统评估了不同soup策略的性能,并分析了模型融合的行为特性。
📝 摘要(中文)
训练大型语言模型(LLMs)和多模态LLMs需要大量的计算资源。现有的公开LLMs通常在不同的、私有策划的数据集上进行预训练,这些数据集涵盖各种任务。例如,LLaMA、Vicuna和LLaVA是三个LLM变体,它们使用LLaMA基础模型,但采用非常不同的训练方法、任务和数据模态进行训练。这种LLM变体的训练成本和复杂性迅速增长。本研究提出使用一种“soup”策略,以经济高效的方式将这些LLM变体组装成一个通用的多模态LLM(SoupLM)。高效地组装这些LLM变体可以将从不同领域和数据模态训练的知识和专长整合到一个模型中(例如,Vicuna从用户共享的对话中获得的聊天机器人专长,以及LLaVA从视觉-语言数据中获得的视觉能力),从而避免在几个不同领域重复训练的计算成本。我们提出了一系列soup策略,以系统地评估各种配置的性能增益,并探究插值空间中基础模型的soup行为。
🔬 方法详解
问题定义:现有的大型语言模型和多模态大型语言模型训练需要消耗大量的计算资源,并且不同的模型往往在不同的数据集和任务上进行训练,导致了知识的碎片化和冗余训练。例如,LLaMA、Vicuna和LLaVA等模型虽然都基于LLaMA,但训练方式和擅长领域各不相同。如何高效地整合这些模型的知识,构建一个通用的多模态模型,是一个重要的挑战。
核心思路:SoupLM的核心思路是利用模型融合(model soup)技术,将多个预训练好的LLM变体(例如LLaMA、Vicuna、LLaVA)的权重进行融合,从而得到一个集成了各个模型优势的新模型。这种方法避免了从头开始训练一个大型模型的巨大成本,并且能够有效地将不同领域的知识迁移到新模型中。
技术框架:SoupLM的整体框架主要包括以下几个步骤:1) 选择需要融合的LLM变体;2) 根据一定的策略(例如平均权重、加权平均等)计算融合后的模型权重;3) 使用融合后的权重构建新的模型SoupLM。整个过程无需额外的训练数据,只需要预训练好的模型权重即可。
关键创新:SoupLM的关键创新在于它提出了一种经济高效的模型集成方法,能够将多个LLM变体的知识和能力整合到一个模型中,而无需重新训练。这种方法特别适用于多模态学习,因为它可以将视觉和语言能力分别训练的模型进行融合,从而得到一个具有更强通用性的多模态模型。
关键设计:SoupLM的关键设计包括:1) 不同的soup策略,例如平均权重、加权平均等,用于控制不同模型在融合过程中的贡献;2) 对插值空间中基础模型的soup行为进行探究,以理解模型融合的内在机制;3) 针对不同的任务和数据集,选择合适的LLM变体进行融合,以最大化性能提升。
🖼️ 关键图片

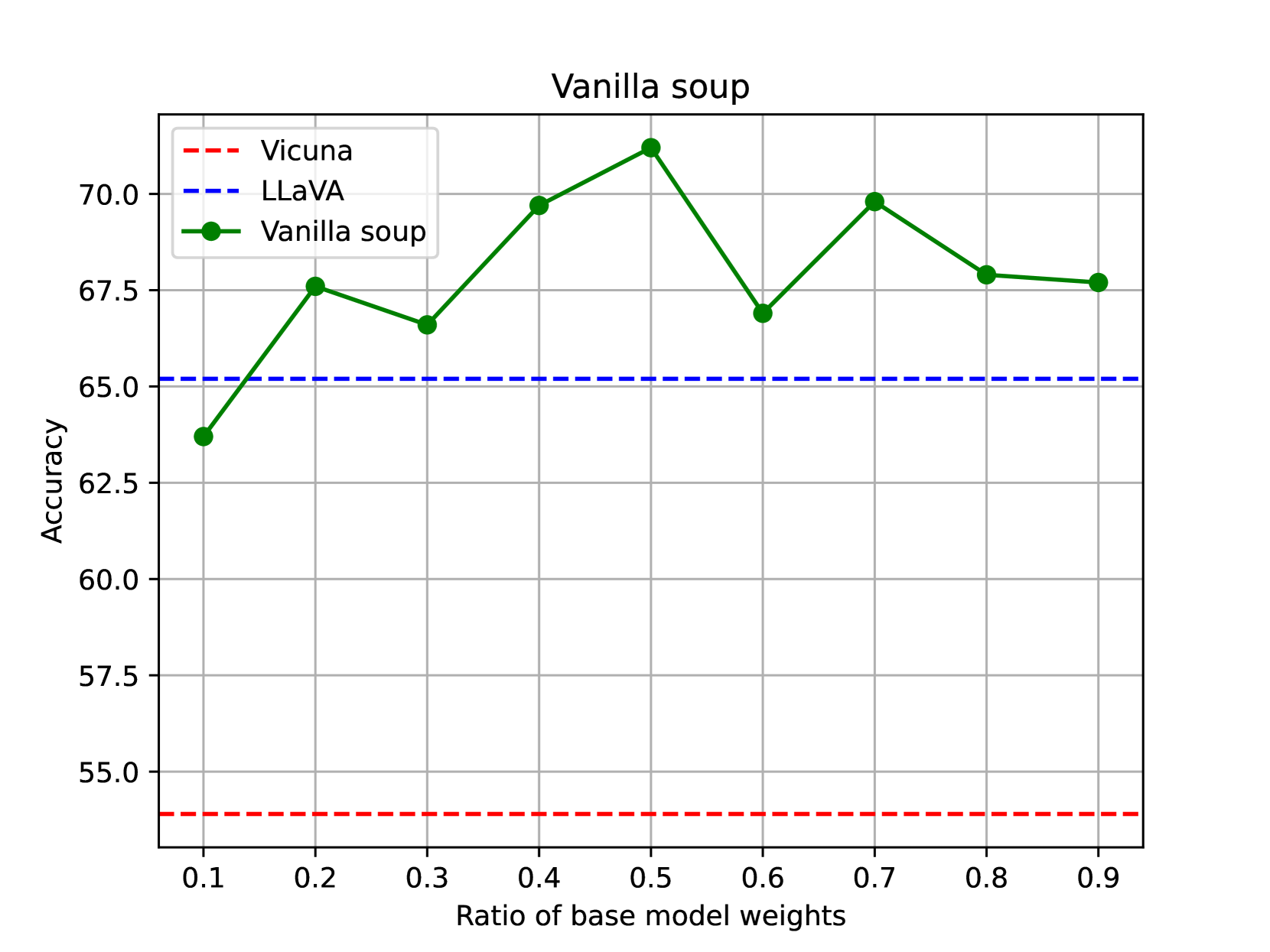

📊 实验亮点
论文系统地评估了不同soup策略在各种配置下的性能增益,并探究了插值空间中基础模型的soup行为。实验结果表明,SoupLM能够有效地将不同LLM变体的知识和能力整合到一个模型中,并在多个任务上取得了显著的性能提升。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
SoupLM可应用于构建低成本、高性能的通用多模态AI系统,例如智能客服、视觉问答、机器人助手等。通过整合不同领域的知识,SoupLM能够更好地理解用户意图,并提供更准确、更全面的服务。该方法降低了多模态模型开发的门槛,加速了AI技术在各行业的落地。
📄 摘要(原文)
Training large language models (LLMs) and multimodal LLMs necessitates significant computing resources, and existing publicly available LLMs are typically pre-trained on diverse, privately curated datasets spanning various tasks. For instance, LLaMA, Vicuna, and LLaVA are three LLM variants trained with LLaMA base models using very different training recipes, tasks, and data modalities. The training cost and complexity for such LLM variants grow rapidly. In this study, we propose to use a soup strategy to assemble these LLM variants into a single well-generalized multimodal LLM (SoupLM) in a cost-efficient manner. Assembling these LLM variants efficiently brings knowledge and specialities trained from different domains and data modalities into an integrated one (e.g., chatbot speciality from user-shared conversations for Vicuna, and visual capacity from vision-language data for LLaVA), therefore, to avoid computing costs of repetitive training on several different domains. We propose series of soup strategies to systematically benchmark performance gains across various configurations, and probe the soup behavior across base models in the interpolation space.