On LLM Wizards: Identifying Large Language Models' Behaviors for Wizard of Oz Experiments
作者: Jingchao Fang, Nikos Arechiga, Keiichi Namaoshi, Nayeli Bravo, Candice Hogan, David A. Shamma
分类: cs.HC, cs.AI
发布日期: 2024-07-10
备注: To be published in ACM IVA 2024
期刊: ACM International Conference on Intelligent Virtual Agents (IVA 2024), September 16-19, 2024, Glasgow, United Kingdom. ACM, New York, NY, USA
💡 一句话要点
利用大语言模型进行WoZ实验:行为识别与实验流程构建
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Wizard of Oz实验 人机交互 角色扮演 实验评估
📋 核心要点
- 传统WoZ实验依赖人工扮演“巫师”,成本高且难以扩展,限制了研究规模和效率。
- 论文提出利用LLM作为WoZ实验中的“巫师”,旨在降低成本、提高可扩展性,并探索LLM在角色扮演方面的潜力。
- 通过LLM驱动的WoZ实验,构建了实验生命周期,并提出了启发式评估框架,用于评估LLM的角色扮演能力。
📝 摘要(中文)
Wizard of Oz (WoZ) 方法是一种广泛采用的研究方法,其中人类扮演“巫师”的角色,模拟尚未成熟的技术,并与参与者互动,以引出用户行为并探索设计空间。随着现代大型语言模型 (LLM) 角色扮演能力的增强,可以将 LLM 应用于 WoZ 实验中,与传统方法相比,具有更好的可扩展性和更低的成本。然而,缺乏关于在 WoZ 实验中负责任地应用 LLM 的方法论指导,以及对 LLM 角色扮演能力的系统评估。通过两项由 LLM 驱动的 WoZ 研究,我们朝着识别实验生命周期迈出了第一步,研究人员可以安全地将 LLM 集成到 WoZ 实验中,并解释来自涉及由 LLM 扮演的巫师的设置生成的数据。我们还贡献了一个基于启发式的评估框架,该框架可以估计 LLM 在 WoZ 实验中的角色扮演能力,并大规模地揭示 LLM 的行为模式。
🔬 方法详解
问题定义:论文旨在解决在Wizard of Oz (WoZ)实验中,传统人工“巫师”成本高、可扩展性差的问题。现有方法难以充分利用大型语言模型(LLM)强大的角色扮演能力,缺乏系统性的方法指导和评估框架,阻碍了LLM在WoZ实验中的应用。
核心思路:论文的核心思路是利用LLM作为WoZ实验中的“巫师”,替代人工进行交互,从而降低实验成本并提高可扩展性。通过构建实验生命周期和启发式评估框架,系统性地评估LLM的角色扮演能力,并指导研究人员安全有效地将LLM集成到WoZ实验中。
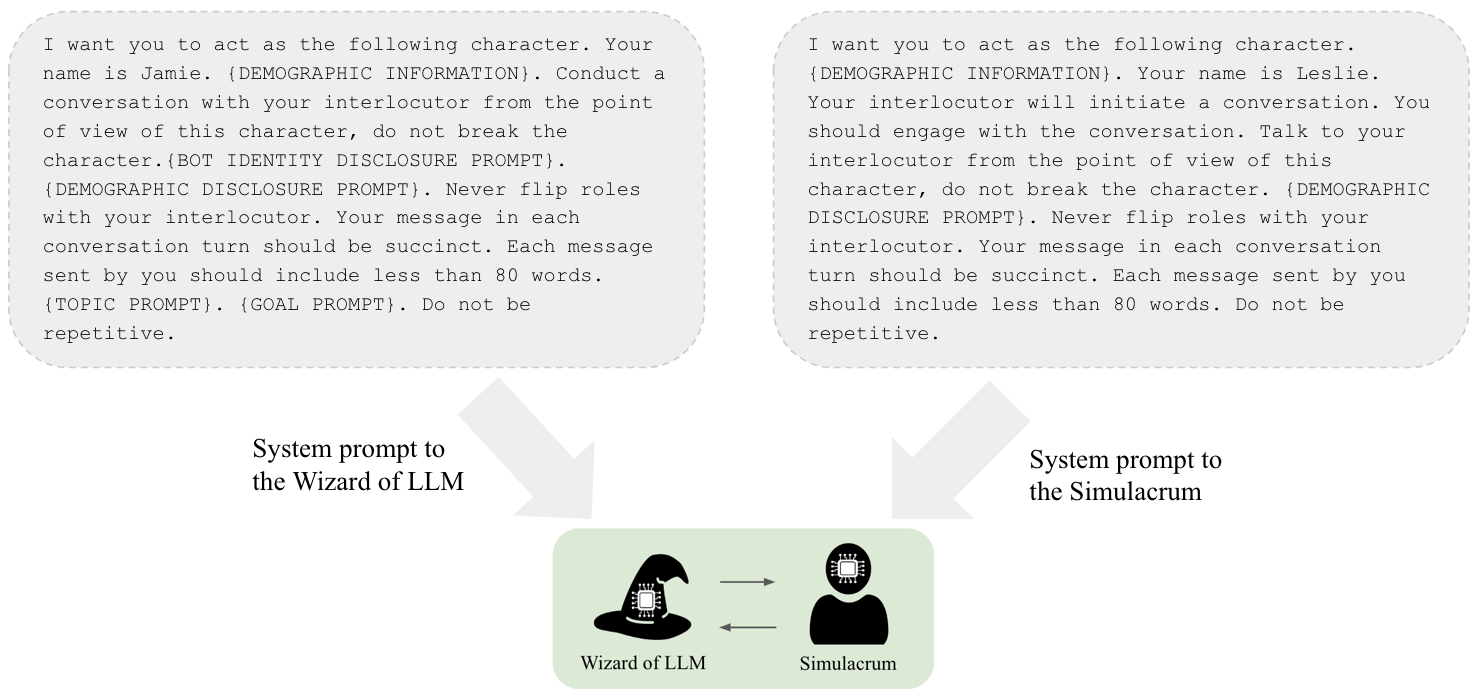
技术框架:论文构建了一个基于LLM的WoZ实验框架,主要包含以下几个阶段:1) 实验设计:确定实验目标、参与者和LLM的角色;2) LLM配置:选择合适的LLM,并进行角色扮演相关的prompt工程;3) 实验执行:LLM与参与者进行交互,收集数据;4) 数据分析:分析LLM的行为模式和角色扮演能力;5) 评估与迭代:使用启发式评估框架评估LLM的表现,并根据结果进行迭代优化。
关键创新:论文的关键创新在于:1) 提出了一个基于LLM的WoZ实验生命周期,为研究人员提供了一个安全有效地将LLM集成到WoZ实验中的流程;2) 贡献了一个基于启发式的评估框架,可以估计LLM在WoZ实验中的角色扮演能力,并大规模地揭示LLM的行为模式。该框架能够帮助研究人员选择合适的LLM,并优化prompt工程,从而提高LLM在WoZ实验中的表现;3) 通过实验验证了LLM在WoZ实验中的可行性和有效性。
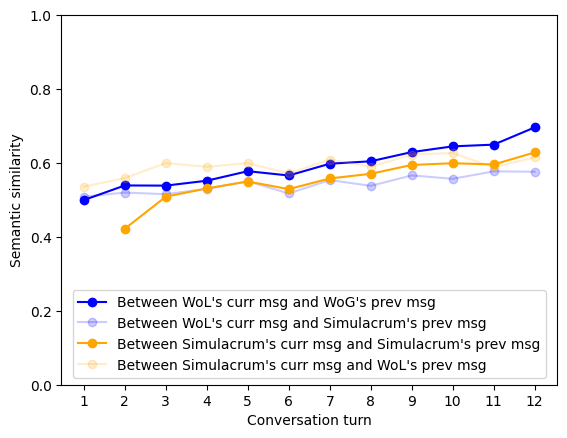
关键设计:论文提出的启发式评估框架包含多个指标,例如:1) 一致性:评估LLM在不同轮次交互中是否保持角色一致;2) 相关性:评估LLM的回复是否与参与者的输入相关;3) 情感倾向:评估LLM的情感表达是否符合角色设定;4) 创造性:评估LLM是否能够生成新颖的回复。这些指标可以定量地评估LLM的角色扮演能力,并为prompt工程提供指导。
🖼️ 关键图片

📊 实验亮点
论文通过两项LLM驱动的WoZ研究,验证了该方法的有效性。实验结果表明,LLM能够有效地扮演“巫师”的角色,并生成与参与者输入相关的回复。此外,启发式评估框架能够有效地评估LLM的角色扮演能力,并为prompt工程提供指导。具体性能数据未知。
🎯 应用场景
该研究成果可广泛应用于人机交互、用户体验设计、智能助手开发等领域。通过利用LLM进行WoZ实验,可以更高效地探索用户需求,优化产品设计,并降低研发成本。未来,该方法有望推动更智能、更人性化的人工智能产品的开发。
📄 摘要(原文)
The Wizard of Oz (WoZ) method is a widely adopted research approach where a human Wizard ``role-plays'' a not readily available technology and interacts with participants to elicit user behaviors and probe the design space. With the growing ability for modern large language models (LLMs) to role-play, one can apply LLMs as Wizards in WoZ experiments with better scalability and lower cost than the traditional approach. However, methodological guidance on responsibly applying LLMs in WoZ experiments and a systematic evaluation of LLMs' role-playing ability are lacking. Through two LLM-powered WoZ studies, we take the first step towards identifying an experiment lifecycle for researchers to safely integrate LLMs into WoZ experiments and interpret data generated from settings that involve Wizards role-played by LLMs. We also contribute a heuristic-based evaluation framework that allows the estimation of LLMs' role-playing ability in WoZ experiments and reveals LLMs' behavior patterns at scale.