MFE-ETP: A Comprehensive Evaluation Benchmark for Multi-modal Foundation Models on Embodied Task Planning
作者: Min Zhang, Xian Fu, Jianye Hao, Peilong Han, Hao Zhang, Lei Shi, Hongyao Tang, Yan Zheng
分类: cs.AI
发布日期: 2024-07-06 (更新: 2024-10-07)
💡 一句话要点
MFE-ETP:用于具身任务规划的多模态基础模型综合评估基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态基础模型 具身任务规划 评估基准 人工智能 机器人 时空感知 任务理解 具身推理
📋 核心要点
- 现有方法在具身任务规划中,多模态基础模型的能力评估缺乏系统性和全面性,难以有效指导模型改进。
- 论文提出MFE-ETP基准,通过系统评估框架,考察模型在对象理解、时空感知、任务理解和具身推理等方面的能力。
- 实验表明,现有先进多模态基础模型在MFE-ETP基准上表现显著落后于人类水平,揭示了其在具身任务规划方面的局限性。
📝 摘要(中文)
近年来,多模态基础模型(MFMs)和具身人工智能(EAI)正以前所未有的速度发展。两者的结合引起了人工智能研究界的广泛关注。本文旨在对MFMs在具身任务规划中的性能进行深入而全面的评估,以揭示它们在该领域的能力和局限性。为此,基于具身任务规划的特点,我们首先开发了一个系统的评估框架,该框架封装了MFMs的四个关键能力:对象理解、时空感知、任务理解和具身推理。在此基础上,我们提出了一个新的基准,名为MFE-ETP,其特点是复杂且可变的任务场景、典型但多样的任务类型、不同难度的任务实例,以及从多重具身问答到具身任务推理的丰富测试用例类型。最后,我们提供了一个简单易用的自动评估平台,可以在所提出的基准上自动测试多个MFMs。使用该基准和评估平台,我们评估了几个最先进的MFMs,发现它们明显落后于人类水平的表现。MFE-ETP是一个高质量、大规模且具有挑战性的基准,与现实世界的任务相关。
🔬 方法详解
问题定义:论文旨在解决多模态基础模型在具身任务规划领域缺乏全面、系统的评估基准的问题。现有方法难以充分评估模型在对象理解、时空感知、任务理解和具身推理等方面的能力,阻碍了模型在该领域的进一步发展。
核心思路:论文的核心思路是构建一个综合性的评估基准MFE-ETP,该基准包含复杂多变的任务场景、典型多样的任务类型以及不同难度的任务实例,并提供自动评估平台,从而能够全面评估多模态基础模型在具身任务规划中的性能。
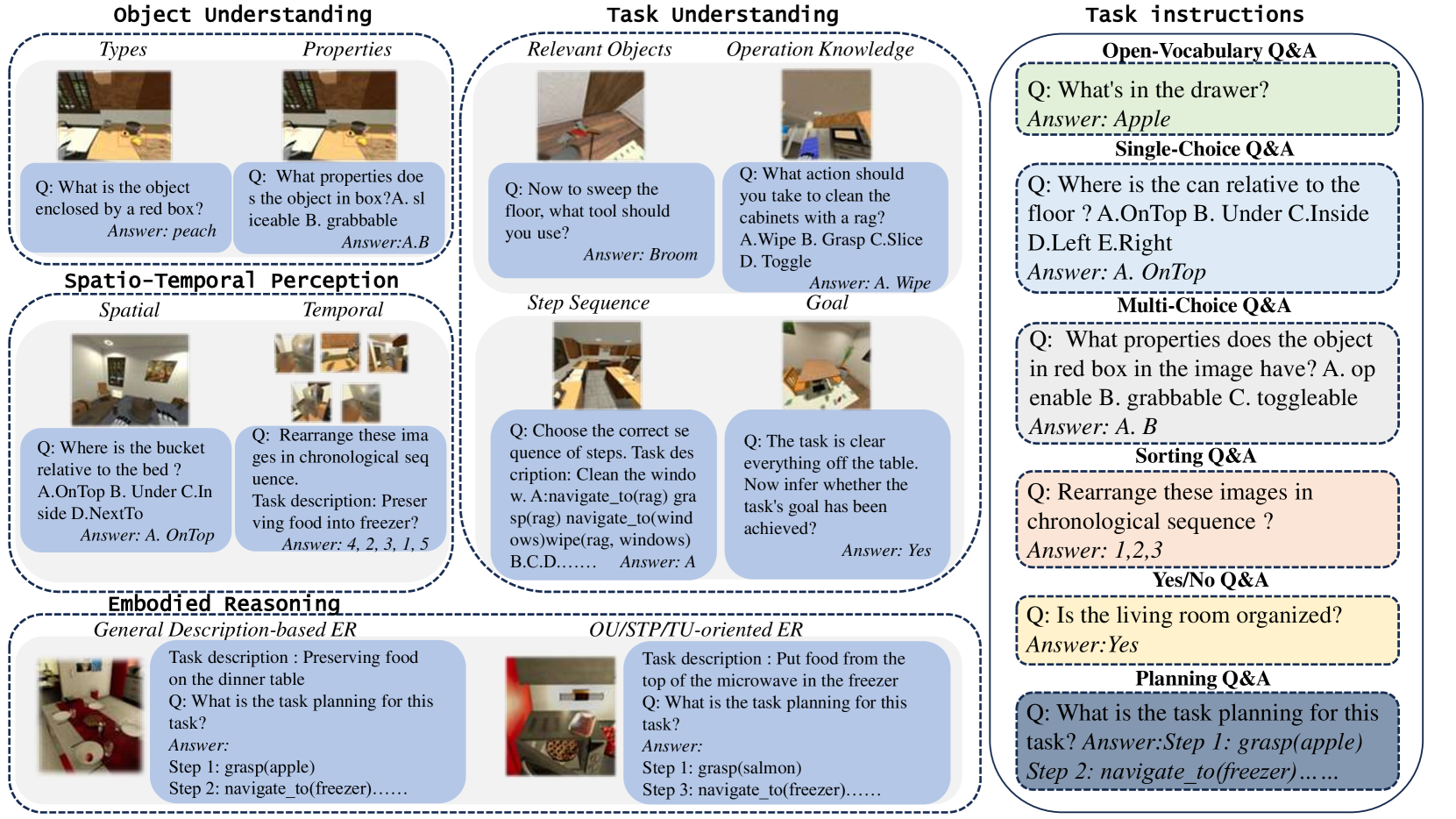
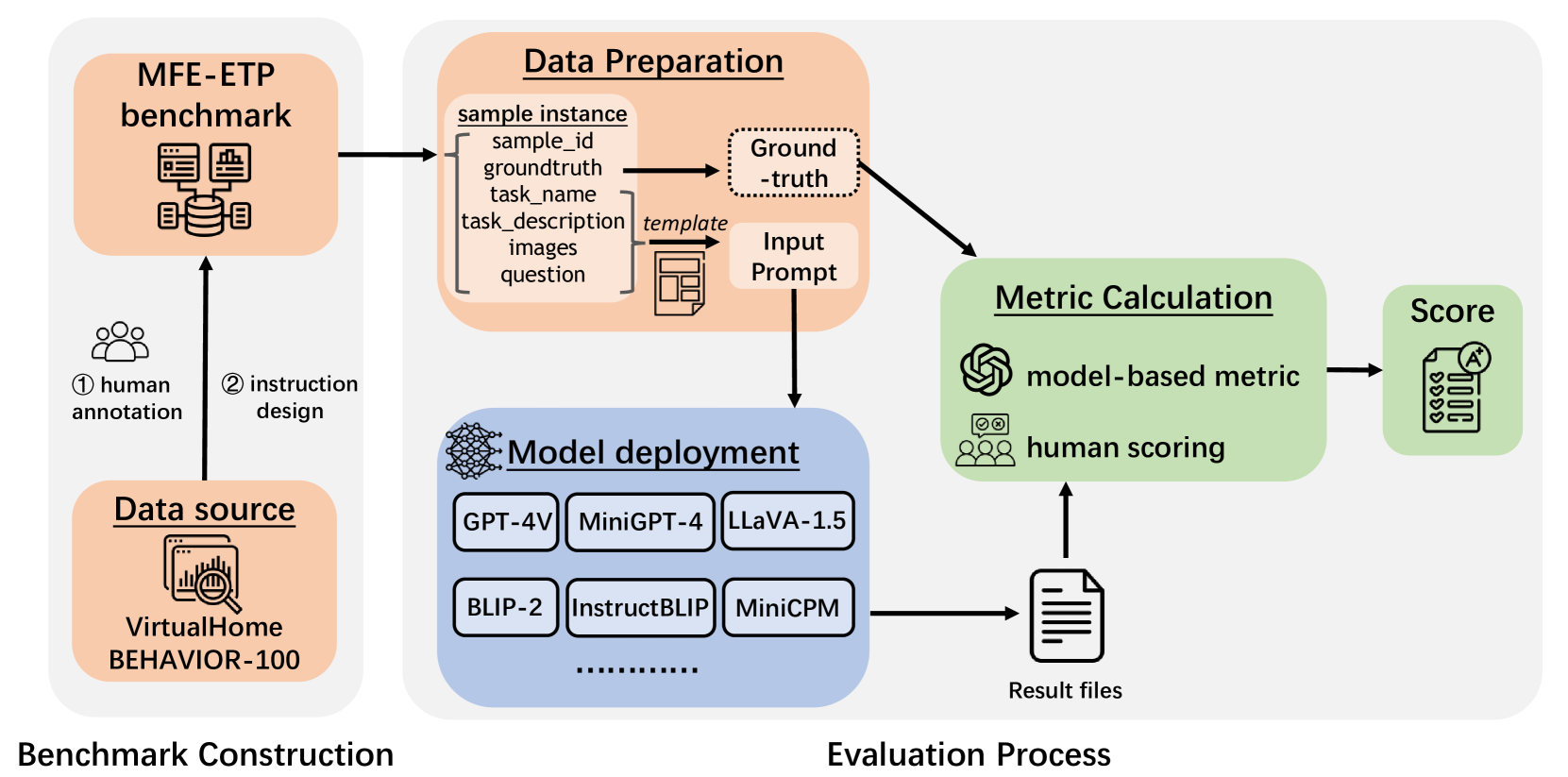
技术框架:MFE-ETP基准的整体框架包含以下几个主要组成部分:1) 系统评估框架,用于定义评估指标和测试用例类型;2) 复杂多变的任务场景,模拟真实世界的具身任务环境;3) 典型多样的任务类型,涵盖多种具身任务规划任务;4) 不同难度的任务实例,用于评估模型在不同难度下的表现;5) 自动评估平台,用于自动化测试和评估多模态基础模型。
关键创新:MFE-ETP基准的关键创新在于其综合性和系统性。它不仅提供了丰富的任务场景和类型,还定义了系统的评估框架,能够全面评估多模态基础模型在具身任务规划中的各项关键能力。此外,自动评估平台的引入大大提高了评估效率和可重复性。
关键设计:MFE-ETP基准的关键设计包括:任务场景的多样性设计,涵盖了各种常见的具身任务环境;任务类型的典型性设计,选择了具有代表性的具身任务规划任务;任务难度的分级设计,确保能够评估模型在不同能力水平下的表现;评估指标的合理性设计,能够准确反映模型的各项关键能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有最先进的多模态基础模型在MFE-ETP基准上的表现显著落后于人类水平,这突显了当前模型在具身任务规划方面的局限性。例如,在复杂的任务推理场景中,模型的成功率远低于人类,表明模型在理解和执行复杂任务方面仍有很大的提升空间。该基准的发布为后续研究提供了重要的评估工具和发展方向。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、自动驾驶等领域,通过全面评估和提升多模态基础模型在具身任务规划方面的能力,有望实现更智能、更自主的机器人系统,从而提高生产效率和生活质量。未来可进一步扩展基准的任务类型和场景,使其更贴近实际应用需求。
📄 摘要(原文)
In recent years, Multi-modal Foundation Models (MFMs) and Embodied Artificial Intelligence (EAI) have been advancing side by side at an unprecedented pace. The integration of the two has garnered significant attention from the AI research community. In this work, we attempt to provide an in-depth and comprehensive evaluation of the performance of MFM s on embodied task planning, aiming to shed light on their capabilities and limitations in this domain. To this end, based on the characteristics of embodied task planning, we first develop a systematic evaluation framework, which encapsulates four crucial capabilities of MFMs: object understanding, spatio-temporal perception, task understanding, and embodied reasoning. Following this, we propose a new benchmark, named MFE-ETP, characterized its complex and variable task scenarios, typical yet diverse task types, task instances of varying difficulties, and rich test case types ranging from multiple embodied question answering to embodied task reasoning. Finally, we offer a simple and easy-to-use automatic evaluation platform that enables the automated testing of multiple MFMs on the proposed benchmark. Using the benchmark and evaluation platform, we evaluated several state-of-the-art MFMs and found that they significantly lag behind human-level performance. The MFE-ETP is a high-quality, large-scale, and challenging benchmark relevant to real-world tasks.