Waterfall: Framework for Robust and Scalable Text Watermarking and Provenance for LLMs
作者: Gregory Kang Ruey Lau, Xinyuan Niu, Hieu Dao, Jiangwei Chen, Chuan-Sheng Foo, Bryan Kian Hsiang Low
分类: cs.CR, cs.AI, cs.CL
发布日期: 2024-07-05 (更新: 2024-10-29)
备注: Accepted to EMNLP 2024 Main Conference
🔗 代码/项目: GITHUB
💡 一句话要点
提出Waterfall框架,实现对LLM生成文本的鲁棒、可扩展水印和溯源。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本水印 大型语言模型 知识产权保护 数据溯源 鲁棒性 可扩展性 代码水印 LLM安全
📋 核心要点
- 现有文本水印方法在面对LLM释义等攻击时鲁棒性不足,且难以扩展到数百万用户。
- Waterfall框架利用LLM进行释义,结合多种技术,实现了鲁棒的可验证性和可扩展性。
- 实验表明,Waterfall在可扩展性、鲁棒性和效率上优于现有方法,并可用于代码和LLM数据溯源。
📝 摘要(中文)
本文提出Waterfall,这是一个无需训练的框架,用于实现鲁棒且可扩展的文本水印,适用于多种文本类型(如文章、代码)和LLM支持的语言,用于通用文本和LLM数据溯源。Waterfall包含多项关键创新,例如首次使用LLM作为释义器进行水印处理,以及一种新颖的技术组合,在实现鲁棒的可验证性和可扩展性方面出人意料地有效。实验结果表明,与最先进的文章文本水印方法相比,Waterfall在可扩展性、鲁棒的可验证性和计算效率方面显著提高,并展示了其如何直接应用于代码水印。此外,Waterfall还可用于LLM数据溯源,LLM输出中可以检测到LLM训练数据的水印,从而可以检测未经授权的数据用于LLM训练,并可能实现开源LLM的以模型为中心的水印,这一直是现有LLM水印工作的局限性。
🔬 方法详解
问题定义:现有文本水印方法在面对大型语言模型(LLM)的释义攻击时,鲁棒性不足,容易被破解。同时,这些方法的可扩展性也存在问题,难以应用于大规模用户场景。此外,现有方法在LLM数据溯源方面存在局限性,无法有效追踪LLM训练数据的来源,从而难以防止未经授权的数据使用。
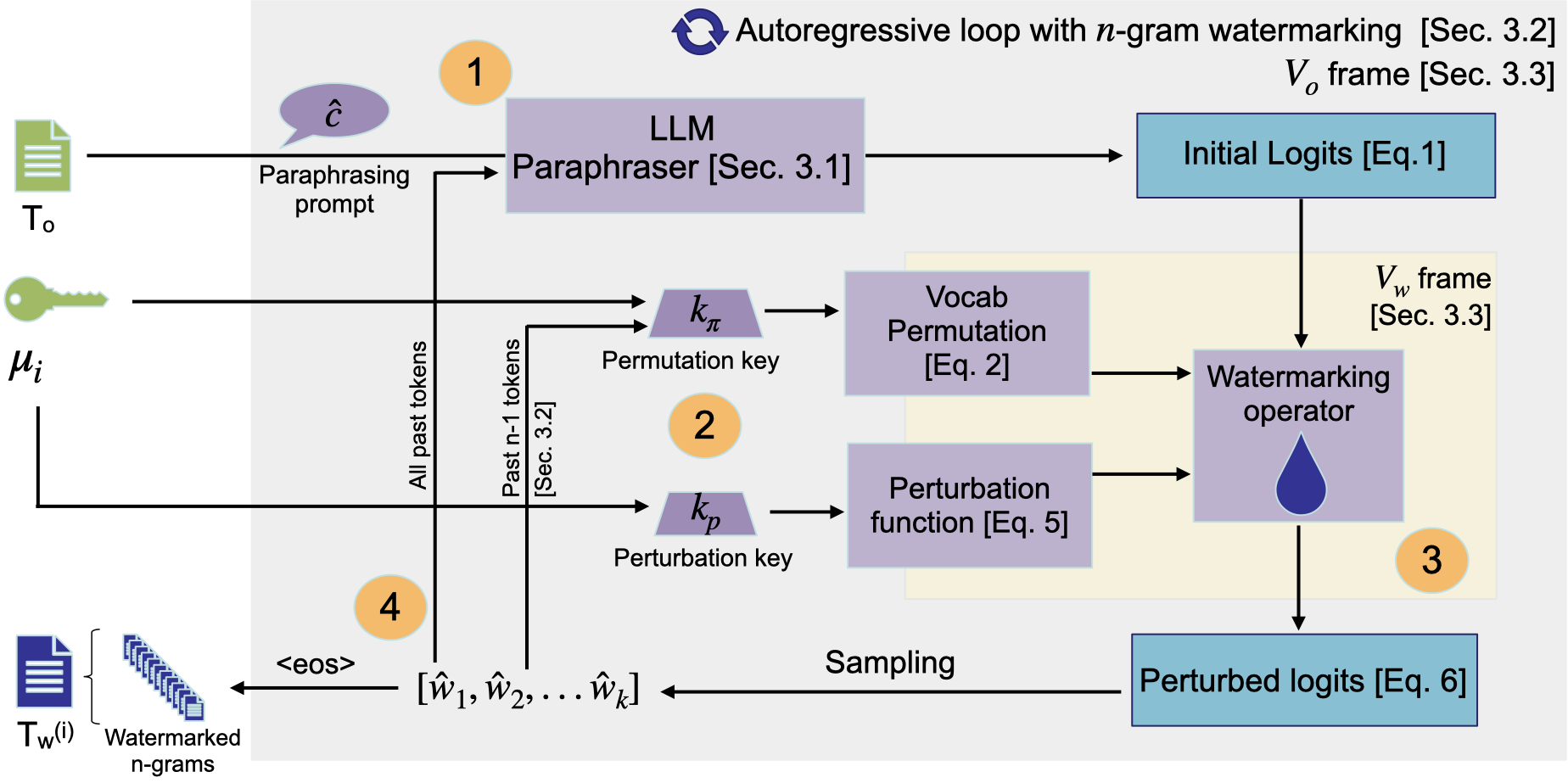
核心思路:Waterfall的核心思路是利用LLM本身作为释义器,通过在原始文本中嵌入水印,并使用LLM进行释义,使得水印在释义后的文本中仍然能够被检测到。这种方法能够有效提高水印的鲁棒性,抵抗LLM的攻击。同时,Waterfall采用了一系列优化技术,提高了水印的可扩展性和计算效率。
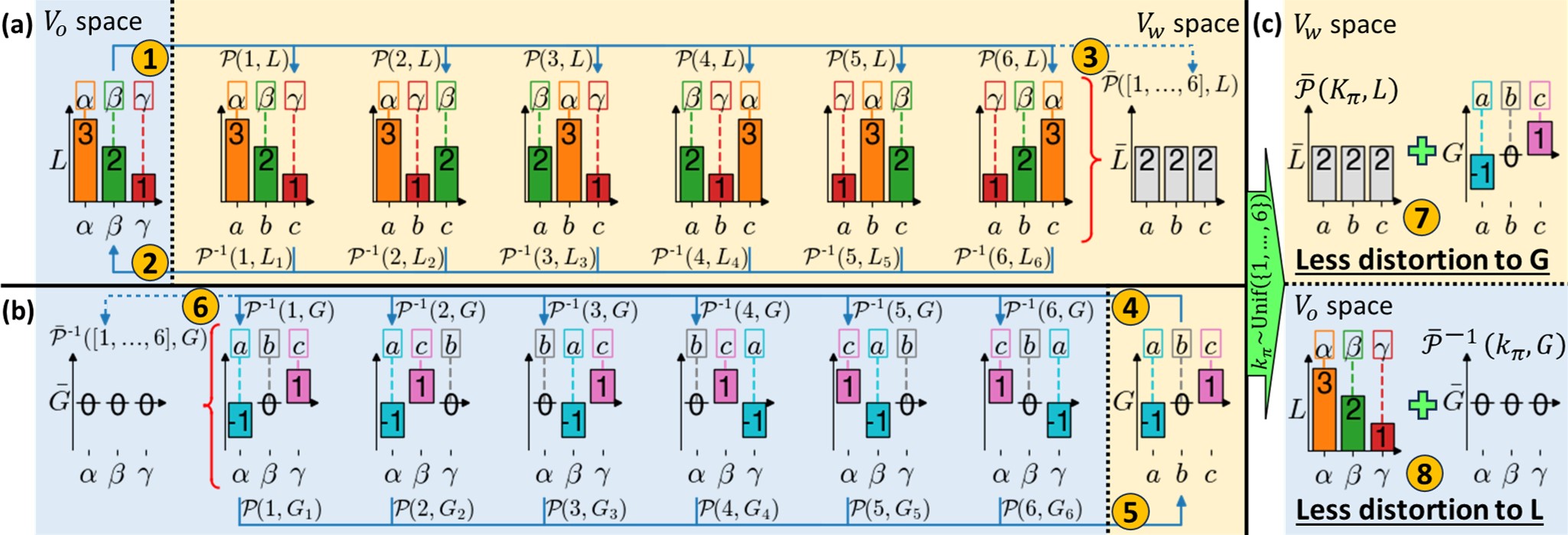
技术框架:Waterfall框架主要包含以下几个模块:1) 水印嵌入模块:该模块负责在原始文本中嵌入水印信息。2) LLM释义模块:该模块使用LLM对嵌入水印的文本进行释义,生成新的文本。3) 水印检测模块:该模块负责在释义后的文本中检测水印信息,验证文本的来源。4) 优化模块:该模块包含一系列优化技术,用于提高水印的鲁棒性、可扩展性和计算效率。
关键创新:Waterfall的关键创新在于首次将LLM作为释义器应用于文本水印领域。通过利用LLM强大的释义能力,Waterfall能够有效抵抗LLM的攻击,提高水印的鲁棒性。此外,Waterfall还提出了一系列优化技术,例如基于语义相似度的水印嵌入策略、基于对抗训练的水印检测方法等,进一步提高了水印的性能。
关键设计:Waterfall的关键设计包括:1) 基于语义相似度的水印嵌入策略:该策略选择与原始文本语义相似的词语进行水印嵌入,从而降低水印对文本质量的影响。2) 基于对抗训练的水印检测方法:该方法通过对抗训练,提高水印检测器对LLM攻击的鲁棒性。3) 可扩展的水印检测算法:该算法采用高效的索引结构,实现了大规模文本的水印快速检测。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Waterfall在文章文本水印任务上,相比SOTA方法在可扩展性上提升显著,同时保持了更高的鲁棒性和计算效率。此外,Waterfall成功应用于代码水印和LLM数据溯源任务,验证了其通用性和有效性。开源代码的发布也为后续研究和应用提供了便利。
🎯 应用场景
Waterfall可广泛应用于文本知识产权保护、代码版权保护、LLM数据溯源等领域。通过对文本、代码或LLM训练数据进行水印标记,可以有效防止未经授权的复制、篡改和使用,维护作者和企业的合法权益。此外,Waterfall还可以用于检测LLM生成内容的来源,防止恶意信息的传播,提高LLM的可信度。
📄 摘要(原文)
Protecting intellectual property (IP) of text such as articles and code is increasingly important, especially as sophisticated attacks become possible, such as paraphrasing by large language models (LLMs) or even unauthorized training of LLMs on copyrighted text to infringe such IP. However, existing text watermarking methods are not robust enough against such attacks nor scalable to millions of users for practical implementation. In this paper, we propose Waterfall, the first training-free framework for robust and scalable text watermarking applicable across multiple text types (e.g., articles, code) and languages supportable by LLMs, for general text and LLM data provenance. Waterfall comprises several key innovations, such as being the first to use LLM as paraphrasers for watermarking along with a novel combination of techniques that are surprisingly effective in achieving robust verifiability and scalability. We empirically demonstrate that Waterfall achieves significantly better scalability, robust verifiability, and computational efficiency compared to SOTA article-text watermarking methods, and showed how it could be directly applied to the watermarking of code. We also demonstrated that Waterfall can be used for LLM data provenance, where the watermarks of LLM training data can be detected in LLM output, allowing for detection of unauthorized use of data for LLM training and potentially enabling model-centric watermarking of open-sourced LLMs which has been a limitation of existing LLM watermarking works. Our code is available at https://github.com/aoi3142/Waterfall.