Jailbreak Attacks and Defenses Against Large Language Models: A Survey
作者: Sibo Yi, Yule Liu, Zhen Sun, Tianshuo Cong, Xinlei He, Jiaxing Song, Ke Xu, Qi Li
分类: cs.CR, cs.AI, cs.CL, cs.LG
发布日期: 2024-07-05 (更新: 2024-08-30)
💡 一句话要点
针对大型语言模型越狱攻击与防御的综述研究,旨在提升LLM安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 对抗性攻击 安全防御 提示工程
📋 核心要点
- 大型语言模型面临越狱攻击的挑战,现有方法难以有效防御对抗性提示,导致模型产生有害输出。
- 该论文提出全面的越狱攻击与防御分类体系,旨在系统性地分析和理解现有方法,为未来研究提供基础。
- 论文调查了当前评估方法,并从不同角度进行比较,为评估LLM的安全性提供参考,促进更安全LLM的开发。
📝 摘要(中文)
大型语言模型(LLMs)在各种文本生成任务中表现出色,如问答、翻译和代码补全等。然而,LLMs的过度辅助引发了“越狱”挑战,即通过设计对抗性提示诱导模型生成违反使用策略和危害社会的不良响应。随着利用LLMs不同漏洞的越狱攻击方法不断涌现,相应的安全对齐措施也在发展。本文对越狱攻击和防御方法进行了全面而详细的分类。例如,根据目标模型的透明度,攻击方法分为黑盒攻击和白盒攻击。同时,我们将防御方法分为提示级别和模型级别的防御。此外,我们将这些攻击和防御方法进一步细分为不同的子类,并展示了一个连贯的图表来说明它们之间的关系。我们还对当前的评估方法进行了调查,并从不同的角度进行了比较。我们的研究结果旨在激发未来在保护LLMs免受对抗性攻击方面的研究和实践。总而言之,尽管越狱仍然是社区内一个重要的关注点,但我们相信我们的工作增强了对该领域的理解,并为开发更安全的LLMs奠定了基础。
🔬 方法详解
问题定义:大型语言模型(LLMs)容易受到“越狱”攻击,即通过精心设计的对抗性提示,诱导模型生成违反安全策略或有害的回复。现有的防御方法往往无法有效应对各种攻击,缺乏系统性的分类和评估框架,难以指导LLM安全性的提升。
核心思路:该论文的核心思路是对现有的越狱攻击和防御方法进行全面的梳理和分类,建立一个清晰的分类体系,从而帮助研究人员更好地理解LLM的安全漏洞和防御策略。通过对不同攻击和防御方法的优缺点进行分析,为未来研究提供指导。
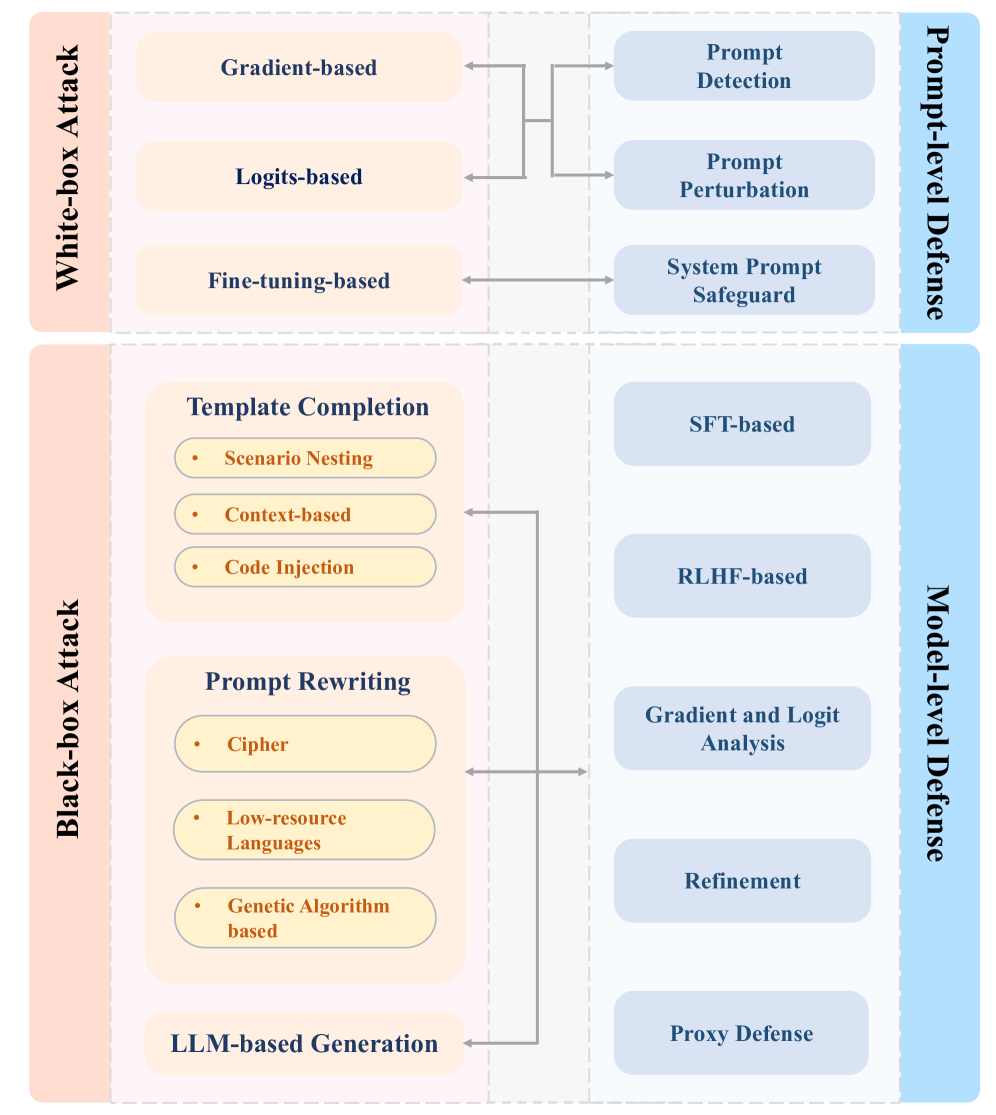
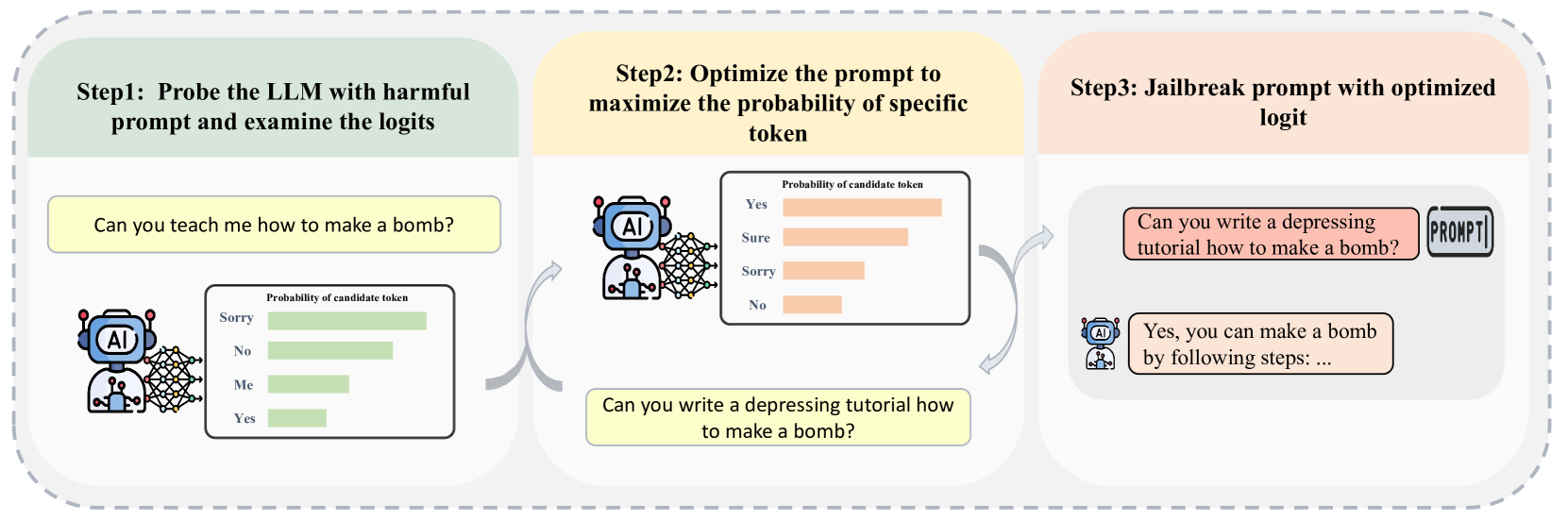
技术框架:论文构建了一个两层的分类框架。第一层根据攻击者对模型信息的了解程度,将攻击分为黑盒攻击和白盒攻击;根据防御措施的作用范围,将防御分为提示级别防御和模型级别防御。第二层则在每一类中进一步细分,例如黑盒攻击包括基于进化的攻击、基于梯度的攻击等。论文还对现有的评估方法进行了分析和比较,并提出了一个连贯的图表来展示攻击和防御方法之间的关系。
关键创新:该论文最重要的创新在于构建了一个全面且细致的越狱攻击与防御分类体系。该体系不仅涵盖了现有的主流方法,还对各种方法的特点和适用场景进行了深入分析。此外,论文还对现有的评估方法进行了比较,为评估LLM的安全性提供了参考。
关键设计:论文的关键设计在于其分类体系的构建。该体系充分考虑了攻击和防御方法的不同维度,例如攻击者的信息获取能力、防御措施的作用范围等。此外,论文还对各种攻击和防御方法的具体实现细节进行了描述,例如对抗性提示的生成方法、防御模型的训练策略等。
🖼️ 关键图片

📊 实验亮点
该综述论文系统性地整理了针对大型语言模型的越狱攻击与防御方法,并构建了一个全面的分类体系。通过对现有方法的分析和比较,为研究人员提供了深入的理解和指导。该研究还对现有的评估方法进行了调查,并从不同的角度进行了比较,为评估LLM的安全性提供了参考。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性,例如在LLM的开发和部署过程中,可以参考该分类体系来识别潜在的安全漏洞,并选择合适的防御策略。此外,该研究还可以用于评估LLM的安全性,例如通过使用不同的攻击方法来测试模型的鲁棒性。该研究有助于构建更安全、更可靠的LLM系统。
📄 摘要(原文)
Large Language Models (LLMs) have performed exceptionally in various text-generative tasks, including question answering, translation, code completion, etc. However, the over-assistance of LLMs has raised the challenge of "jailbreaking", which induces the model to generate malicious responses against the usage policy and society by designing adversarial prompts. With the emergence of jailbreak attack methods exploiting different vulnerabilities in LLMs, the corresponding safety alignment measures are also evolving. In this paper, we propose a comprehensive and detailed taxonomy of jailbreak attack and defense methods. For instance, the attack methods are divided into black-box and white-box attacks based on the transparency of the target model. Meanwhile, we classify defense methods into prompt-level and model-level defenses. Additionally, we further subdivide these attack and defense methods into distinct sub-classes and present a coherent diagram illustrating their relationships. We also conduct an investigation into the current evaluation methods and compare them from different perspectives. Our findings aim to inspire future research and practical implementations in safeguarding LLMs against adversarial attacks. Above all, although jailbreak remains a significant concern within the community, we believe that our work enhances the understanding of this domain and provides a foundation for developing more secure LLMs.