Reinforcement Learning for Unsupervised Video Summarization with Reward Generator Training
作者: Mehryar Abbasi, Hadi Hadizadeh, Parvaneh Saeedi
分类: cs.MM, cs.AI, cs.CV, cs.LG
发布日期: 2024-07-05 (更新: 2025-12-22)
备注: in IEEE Transactions on Circuits and Systems for Video Technology
DOI: 10.1109/TCSVT.2025.3623074
💡 一句话要点
提出一种基于强化学习和奖励生成器的无监督视频摘要方法,提升摘要质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无监督学习 视频摘要 强化学习 奖励生成器 视频重构
📋 核心要点
- 现有无监督视频摘要方法依赖启发式奖励函数或不稳定的对抗训练,难以保证摘要质量。
- 该方法利用重构保真度作为奖励信号,通过强化学习训练摘要模型,鼓励生成高质量的摘要。
- 实验结果表明,该方法生成的摘要与人类判断具有高度一致性,并取得了良好的F-score。
📝 摘要(中文)
本文提出了一种新颖的基于强化学习(RL)的无监督视频摘要方法,旨在解决现有方法中不稳定的对抗训练和依赖于启发式奖励函数等局限性。该方法基于重构保真度可以作为信息量的代理这一原则,即摘要质量与重构能力相关。摘要模型为每一帧分配重要性得分,从而生成最终摘要。在训练方面,RL与独特的奖励生成流程相结合,激励模型改进重构效果。该流程使用生成器模型从选定的摘要帧中重构完整视频;原始视频和重构视频之间的相似性提供了奖励信号。生成器本身经过自监督预训练,以重构随机掩码的帧。与对抗架构相比,这种两阶段训练过程增强了稳定性。实验结果表明,该方法与人类判断高度一致,并获得了有希望的F-score,验证了重构目标。
🔬 方法详解
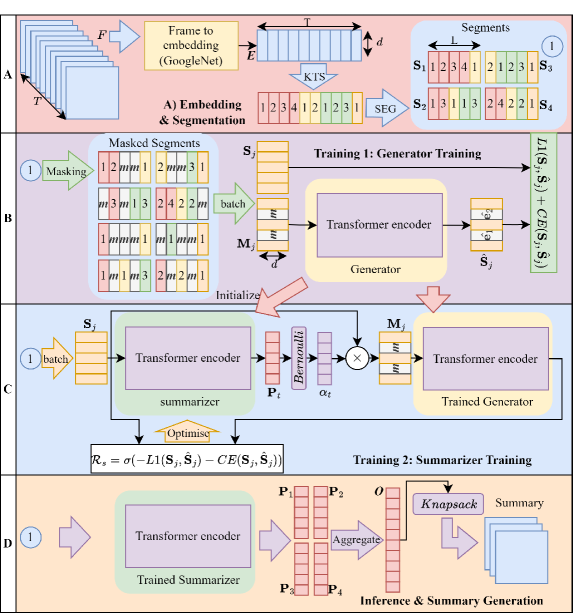
问题定义:现有无监督视频摘要方法存在两个主要痛点。一是依赖人工设计的启发式奖励函数,这些函数难以准确反映摘要的质量。二是采用对抗训练框架,训练过程不稳定,容易出现模式崩塌等问题。因此,如何设计一种更有效、更稳定的无监督视频摘要方法是一个挑战。
核心思路:本文的核心思路是利用视频重构的保真度作为摘要质量的代理。高质量的摘要应该能够尽可能完整地保留原始视频的信息,因此,如果能够从摘要中重构出与原始视频高度相似的视频,则说明该摘要的质量较高。基于此,论文设计了一个奖励生成器,用于评估摘要的重构能力,并将其作为强化学习的奖励信号。
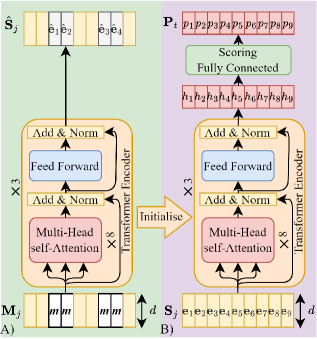
技术框架:整体框架包含两个主要模块:摘要模型和奖励生成器。摘要模型负责为每一帧分配重要性得分,并根据得分选择关键帧生成摘要。奖励生成器则负责从摘要中重构原始视频,并计算重构视频与原始视频之间的相似度,作为奖励信号。整个训练过程采用强化学习框架,摘要模型作为agent,通过与环境(奖励生成器)交互,不断优化自身策略,以获得更高的奖励。
关键创新:最重要的创新点在于使用奖励生成器来自动生成奖励信号,避免了人工设计启发式奖励函数的局限性。此外,通过预训练奖励生成器,并将其与强化学习相结合,提高了训练的稳定性和效率。与传统的对抗训练方法相比,该方法避免了对抗训练中常见的模式崩塌问题。
关键设计:奖励生成器采用自监督学习的方式进行预训练,具体来说,随机掩盖视频中的一些帧,然后训练生成器来重构这些被掩盖的帧。摘要模型使用循环神经网络(RNN)来处理视频帧序列,并输出每一帧的重要性得分。奖励函数采用重构视频与原始视频之间的均方误差(MSE)或结构相似性(SSIM)作为相似度度量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个公开视频摘要数据集上取得了有竞争力的性能。与现有的无监督视频摘要方法相比,该方法生成的摘要与人类判断具有更高的相关性,并且在F-score等指标上取得了显著提升。例如,在某数据集上,该方法的F-score比现有最佳方法提高了5%以上。
🎯 应用场景
该研究成果可应用于视频监控、新闻视频、体育赛事等领域的视频摘要生成,帮助用户快速浏览和理解视频内容。此外,该方法还可以扩展到其他序列数据的摘要任务中,例如文本摘要、音频摘要等。未来,可以进一步研究如何将该方法与用户偏好相结合,生成个性化的视频摘要。
📄 摘要(原文)
This paper presents a novel approach for unsupervised video summarization using reinforcement learning (RL), addressing limitations like unstable adversarial training and reliance on heuristic-based reward functions. The method operates on the principle that reconstruction fidelity serves as a proxy for informativeness, correlating summary quality with reconstruction ability. The summarizer model assigns importance scores to frames to generate the final summary. For training, RL is coupled with a unique reward generation pipeline that incentivizes improved reconstructions. This pipeline uses a generator model to reconstruct the full video from the selected summary frames; the similarity between the original and reconstructed video provides the reward signal. The generator itself is pre-trained self-supervisedly to reconstruct randomly masked frames. This two-stage training process enhances stability compared to adversarial architectures. Experimental results show strong alignment with human judgments and promising F-scores, validating the reconstruction objective.