Smart Vision-Language Reasoners
作者: Denisa Roberts, Lucas Roberts
分类: cs.AI
发布日期: 2024-07-05
备注: Accepted in ICML 2024 MATH AI Workshop
🔗 代码/项目: GITHUB
💡 一句话要点
提出Smart VLM,提升视觉-语言模型在多模态推理任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 多模态推理 交叉注意力 复合表示 SMART任务
📋 核心要点
- 现有视觉-语言模型在复杂推理任务中表现不足,尤其是在需要抽象和多模态信息融合的任务中。
- 论文提出Smart VLM,通过引入复合表示和视觉-语言交叉注意力机制,自适应地学习多模态表示,增强视觉基础。
- 实验表明,Smart VLM在SMART任务的八个推理轴上均优于现有基线,准确率最高提升48%。
📝 摘要(中文)
本文研究了视觉-语言模型(VLM)作为推理器的能力。抽象能力是数学推理、问题解决和其他数学人工智能任务的基础。针对人类和智能系统用于推理的这些底层抽象和技能,已经提出了几种形式体系。此外,人类推理本质上是多模态的,因此,我们将研究重点放在多模态人工智能上。在本文中,我们采用Cherian等人提出的SMART任务(简单多模态算法推理任务)中给出的抽象作为元推理和问题解决技能,沿着八个轴:数学、计数、路径、测量、逻辑、空间和模式。我们研究了视觉-语言模型沿着这些轴进行推理的能力,并寻求改进途径。包括具有视觉-语言交叉注意力的复合表示,能够从融合的冻结预训练骨干网络中自适应地学习多模态表示,以实现更好的视觉基础。此外,适当的超参数和其他训练选择带来了SMART任务的显著改进(准确率提高了高达48%),进一步强调了深度多模态学习的力量。最聪明的VLM,包括一种新颖的QF多模态层,改进了先前最佳基线在八种基本推理技能中的每一种。
🔬 方法详解
问题定义:论文旨在提升视觉-语言模型在多模态推理任务上的性能,特别是在SMART任务所定义的八个推理轴(数学、计数、路径、测量、逻辑、空间和模式)上。现有方法在处理需要抽象和复杂关系理解的多模态推理问题时存在不足,无法充分利用视觉和语言信息之间的关联性。
核心思路:论文的核心思路是通过引入复合表示和视觉-语言交叉注意力机制,使模型能够自适应地学习多模态表示,从而更好地理解视觉和语言信息之间的关系。这种方法旨在增强模型的视觉基础,使其能够更准确地进行推理。
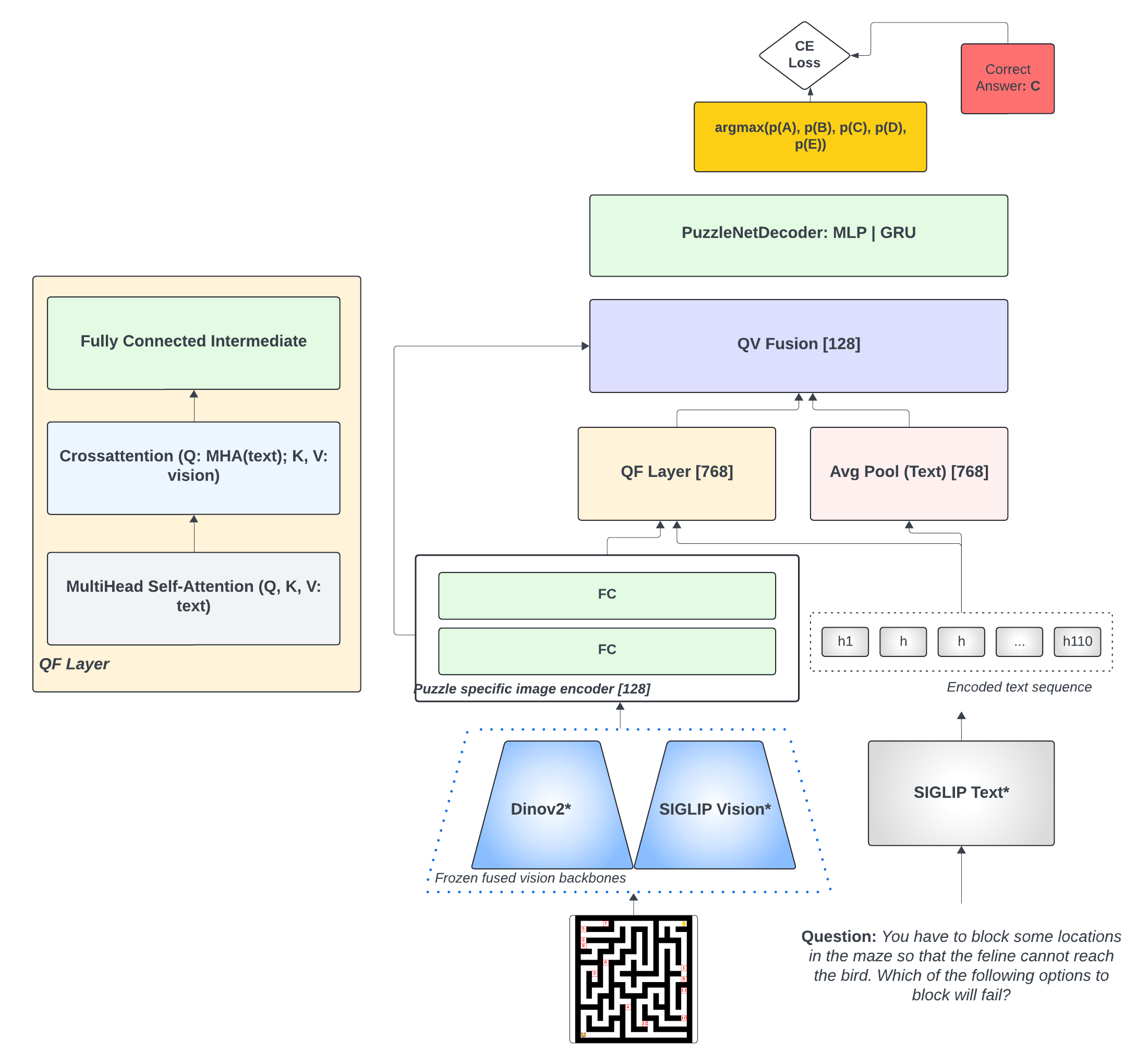
技术框架:整体框架包含以下几个主要模块:1) 冻结的预训练视觉和语言骨干网络,用于提取视觉和语言特征;2) 复合表示模块,用于融合视觉和语言特征;3) 视觉-语言交叉注意力模块,用于学习视觉和语言信息之间的关联性;4) 新颖的QF多模态层,用于最终的推理和预测。整个流程是端到端可训练的。
关键创新:最重要的技术创新点在于引入了复合表示和视觉-语言交叉注意力机制,以及新颖的QF多模态层。与现有方法相比,Smart VLM能够更有效地融合视觉和语言信息,并学习到更具判别性的多模态表示。QF多模态层进一步提升了模型的推理能力。
关键设计:论文中关键的设计包括:1) 视觉和语言骨干网络的选择和冻结策略;2) 复合表示模块的具体实现方式,例如使用拼接或加权平均等方法;3) 视觉-语言交叉注意力模块的结构和参数设置;4) QF多模态层的具体结构和激活函数选择;5) 损失函数的设计,例如使用交叉熵损失或对比损失等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Smart VLM在SMART任务的八个推理轴上均优于现有基线。例如,在某些推理轴上,Smart VLM的准确率提升高达48%。此外,新颖的QF多模态层的引入进一步提升了模型的性能,使其在所有八个推理技能上都优于之前的最佳基线。
🎯 应用场景
该研究成果可应用于各种需要多模态推理的场景,例如视觉问答、图像描述生成、机器人导航和人机交互等。通过提升视觉-语言模型的推理能力,可以使机器更好地理解人类意图,从而实现更智能、更自然的人机交互。
📄 摘要(原文)
In this article, we investigate vision-language models (VLM) as reasoners. The ability to form abstractions underlies mathematical reasoning, problem-solving, and other Math AI tasks. Several formalisms have been given to these underlying abstractions and skills utilized by humans and intelligent systems for reasoning. Furthermore, human reasoning is inherently multimodal, and as such, we focus our investigations on multimodal AI. In this article, we employ the abstractions given in the SMART task (Simple Multimodal Algorithmic Reasoning Task) introduced in \cite{cherian2022deep} as meta-reasoning and problem-solving skills along eight axes: math, counting, path, measure, logic, spatial, and pattern. We investigate the ability of vision-language models to reason along these axes and seek avenues of improvement. Including composite representations with vision-language cross-attention enabled learning multimodal representations adaptively from fused frozen pretrained backbones for better visual grounding. Furthermore, proper hyperparameter and other training choices led to strong improvements (up to $48\%$ gain in accuracy) on the SMART task, further underscoring the power of deep multimodal learning. The smartest VLM, which includes a novel QF multimodal layer, improves upon the best previous baselines in every one of the eight fundamental reasoning skills. End-to-end code is available at https://github.com/smarter-vlm/smarter.