An Empirical Study on Capability of Large Language Models in Understanding Code Semantics
作者: Thu-Trang Nguyen, Thanh Trong Vu, Hieu Dinh Vo, Son Nguyen
分类: cs.SE, cs.AI
发布日期: 2024-07-04
💡 一句话要点
提出EMPICA框架以评估代码LLM对代码语义的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码理解 大型语言模型 软件工程 语义分析 模型评估 鲁棒性 敏感性
📋 核心要点
- 现有代码LLM在理解代码语义方面存在显著不足,尤其是在处理语义等价和非等价代码时的鲁棒性和敏感性。
- 论文提出EMPICA框架,通过系统性地引入控制性修改,评估代码LLM对代码语义的理解能力,确保模型在语义等价和非等价输入下的表现一致性。
- 实验结果显示,当前代码LLM在不同代码理解任务中的鲁棒性和敏感性差异显著,尤其在语义保持变换下表现更佳,提示需增强模型的理解能力。
📝 摘要(中文)
大型语言模型(LLM)在软件工程任务中表现出色,但其对代码语义的理解能力仍存在疑虑。本文提出EMPICA框架,系统性地评估代码LLM在理解代码语义方面的能力。通过对输入代码进行控制性修改,研究模型的响应。实验结果表明,当前最先进的代码LLM在不同任务和变换操作下的鲁棒性和敏感性差异显著,尤其在语义保持变换下表现出更好的鲁棒性。这些发现强调了提升模型理解代码语义能力的必要性。
🔬 方法详解
问题定义:本文旨在解决代码LLM在理解代码语义时的鲁棒性和敏感性不足的问题。现有方法未能有效评估模型对语义等价和非等价代码的反应。
核心思路:提出EMPICA框架,通过对输入代码进行控制性修改,系统性评估模型的响应,确保模型在语义等价输入下输出一致,而在非等价输入下输出不同。
技术框架:EMPICA框架包括输入代码的控制性修改、模型响应的评估和结果分析三个主要模块。首先,进行语义等价和非等价的代码变换;其次,收集模型的输出并进行比较;最后,分析模型的鲁棒性和敏感性。
关键创新:EMPICA框架的创新在于其系统性和控制性,能够明确评估代码LLM在不同语义变换下的表现,与现有方法相比,更加全面和深入。
关键设计:在实验中,设置了多种语义变换操作,采用了特定的损失函数来评估模型输出的一致性和差异性,确保模型在不同任务中的表现能够被准确衡量。
🖼️ 关键图片


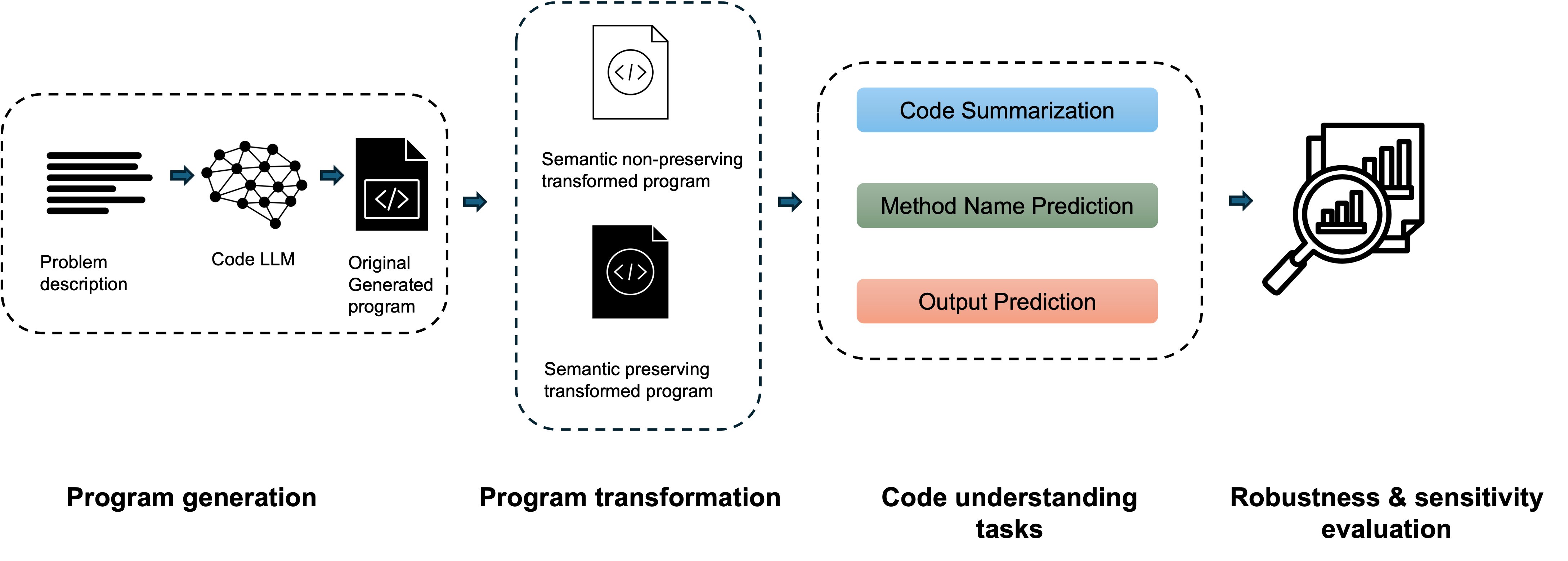
📊 实验亮点
实验结果表明,当前最先进的代码LLM在代码理解任务中的鲁棒性和敏感性存在显著差异。例如,在语义保持变换下,模型的输出一致性高达85%,而在非保持变换下,输出差异性明显,提示模型在理解代码语义方面的不足。
🎯 应用场景
该研究的潜在应用领域包括软件开发工具、代码自动生成、代码审查和智能编程助手等。通过提升代码LLM对代码语义的理解能力,可以显著提高软件开发的效率和质量,未来可能推动更智能的编程环境的形成。
📄 摘要(原文)
Large Language Models for Code (code LLMs) have demonstrated remarkable performance across various software engineering (SE) tasks, increasing the application of code LLMs in software development. Despite the success of code LLMs, there remain significant concerns about the actual capabilities and reliability of these models, "whether these models really learn the semantics of code from the training data and leverage the learned knowledge to perform the SE tasks". In this paper, we introduce EMPICA, a comprehensive framework designed to systematically and empirically evaluate the capabilities of code LLMs in understanding code semantics. Specifically, EMPICA systematically introduces controlled modifications/transformations into the input code and examines the models' responses. Generally, code LLMs must be robust to semantically equivalent code inputs and be sensitive to non-equivalent ones for all SE tasks. Specifically, for every SE task, given an input code snippet c and its semantic equivalent variants, code LLMs must robustly produce consistent/equivalent outputs while they are expected to generate different outputs for c and its semantic non-equivalent variants. Our experimental results on three representative code understanding tasks, including code summarization, method name prediction, and output prediction, reveal that the robustness and sensitivity of the state-of-the-art code LLMs to code transformations vary significantly across tasks and transformation operators. In addition, the code LLMs exhibit better robustness to the semantic preserving transformations than their sensitivity to the semantic non-preserving transformations. These results highlight a need to enhance the model's capabilities of understanding code semantics, especially the sensitivity property.