Towards Attention-based Contrastive Learning for Audio Spoof Detection
作者: Chirag Goel, Surya Koppisetti, Ben Colman, Ali Shahriyari, Gaurav Bharaj
分类: cs.SD, cs.AI, eess.AS
发布日期: 2024-07-03
备注: Proc. INTERSPEECH 2023
DOI: 10.21437/Interspeech.2023-245
💡 一句话要点
提出基于注意力机制的对比学习框架SSAST-CL,用于提升音频欺骗检测性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 音频欺骗检测 对比学习 注意力机制 语音安全 Transformer
📋 核心要点
- 现有音频欺骗检测方法在复杂场景下表现不足,缺乏对真假语音细微差异的有效建模。
- 论文提出基于注意力机制的对比学习框架,利用交叉注意力增强对真假语音表征的区分能力。
- 实验表明,该框架能有效分离真假语音类别,并在 ASVSpoof 2021 挑战赛上取得竞争力的性能。
📝 摘要(中文)
视觉Transformer (ViT) 在计算机视觉的分类任务中取得了显著进展。最近,Gong 等人 (2021) 提出了基于注意力机制的模型用于多个音频任务。然而,ViT 在音频欺骗检测任务中的应用相对较少。我们填补了这一空白,并将 ViT 引入该任务。一个基于微调 SSAST (Gong 等人,2022) 音频 ViT 模型的基线模型实现了次优的等错误率 (EER)。为了提高性能,我们提出了一种新颖的基于注意力机制的对比学习框架 (SSAST-CL),该框架使用交叉注意力来辅助表征学习。实验表明,我们的框架成功地分离了真实语音和欺骗语音类别,并有助于学习更好的分类器。通过适当的数据增强策略,在我们的框架上训练的模型在 ASVSpoof 2021 挑战赛上取得了具有竞争力的性能。我们提供了比较和消融研究来证明我们的主张。
🔬 方法详解
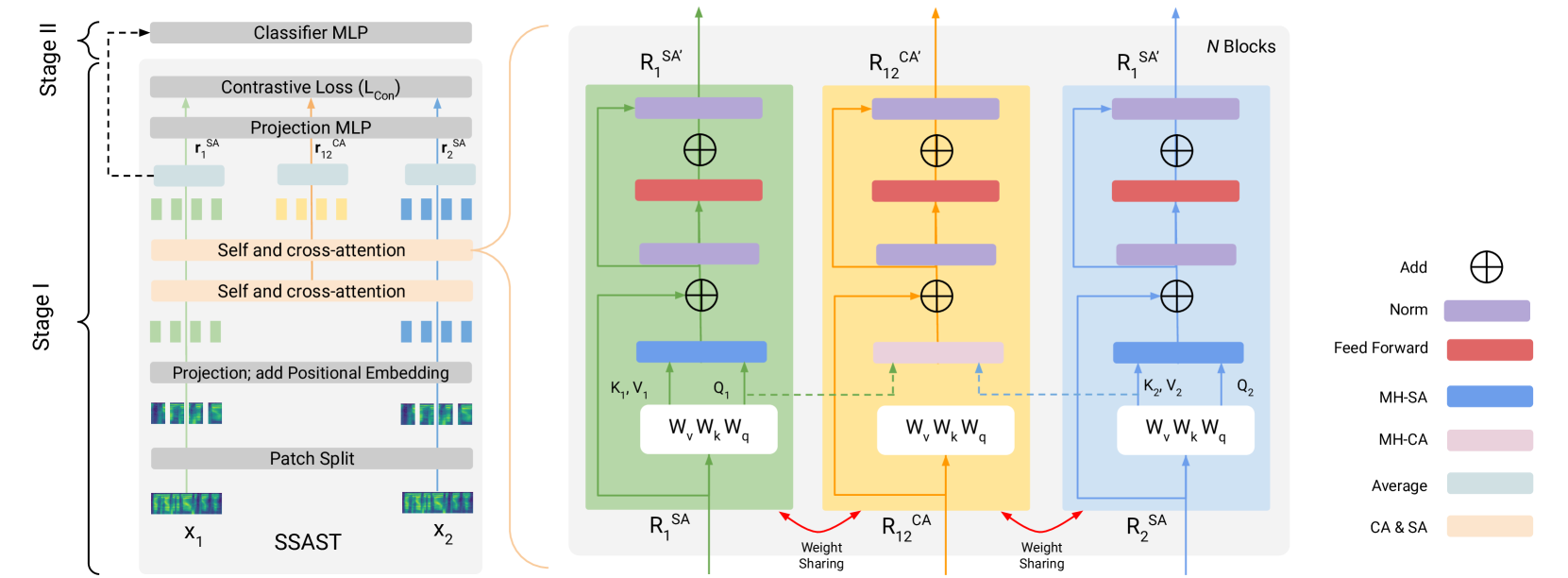
问题定义:音频欺骗检测旨在区分真实语音和通过各种手段伪造的语音。现有方法在处理复杂攻击和未知欺骗手段时,泛化能力不足,难以有效捕捉真假语音之间的细微差别。尤其是在数据量有限的情况下,模型的判别能力会受到限制。
核心思路:论文的核心思路是利用对比学习,通过拉近同类样本的距离,推远不同类样本的距离,从而学习到更具判别性的语音表征。同时,引入注意力机制,使模型能够关注语音中更重要的特征,进一步提升区分能力。
技术框架:整体框架基于 SSAST (Spectrogram Transformer) 模型,这是一个预训练的音频 ViT 模型。在此基础上,引入对比学习模块。框架包含以下主要步骤:1) 使用 SSAST 提取语音特征;2) 通过交叉注意力机制增强特征表示;3) 使用对比损失函数训练模型,区分真实语音和欺骗语音。
关键创新:关键创新在于将注意力机制与对比学习相结合,提出了一种新的音频欺骗检测框架。通过交叉注意力,模型能够更好地学习到真假语音之间的差异性特征,从而提升检测性能。此外,针对音频欺骗检测任务,设计了特定的数据增强策略,进一步提升模型的鲁棒性。
关键设计:论文使用了 InfoNCE 损失作为对比损失函数,旨在最大化正样本对之间的互信息,最小化负样本对之间的互信息。交叉注意力模块的具体实现方式未知,但其目的是让模型关注不同语音片段之间的关联性,从而更好地捕捉欺骗语音的特征。数据增强策略的具体细节也未知,但其目的是增加训练数据的多样性,提升模型的泛化能力。
🖼️ 关键图片

📊 实验亮点
该论文提出的 SSAST-CL 框架在 ASVSpoof 2021 挑战赛上取得了具有竞争力的性能,表明该方法在音频欺骗检测任务上的有效性。通过对比实验和消融研究,验证了注意力机制和对比学习对提升模型性能的贡献。具体的性能数据和提升幅度未知,但摘要中明确指出该方法优于基线模型。
🎯 应用场景
该研究成果可应用于语音安全领域,例如防止语音欺诈、保护语音通信安全等。在智能客服、金融身份验证等场景中,可以有效识别和拦截欺骗语音,降低安全风险。未来,该技术有望扩展到其他音频安全领域,例如语音伪造检测、语音克隆检测等。
📄 摘要(原文)
Vision transformers (ViT) have made substantial progress for classification tasks in computer vision. Recently, Gong et. al. '21, introduced attention-based modeling for several audio tasks. However, relatively unexplored is the use of a ViT for audio spoof detection task. We bridge this gap and introduce ViTs for this task. A vanilla baseline built on fine-tuning the SSAST (Gong et. al. '22) audio ViT model achieves sub-optimal equal error rates (EERs). To improve performance, we propose a novel attention-based contrastive learning framework (SSAST-CL) that uses cross-attention to aid the representation learning. Experiments show that our framework successfully disentangles the bonafide and spoof classes and helps learn better classifiers for the task. With appropriate data augmentations policy, a model trained on our framework achieves competitive performance on the ASVSpoof 2021 challenge. We provide comparisons and ablation studies to justify our claim.