TheoremLlama: Transforming General-Purpose LLMs into Lean4 Experts
作者: Ruida Wang, Jipeng Zhang, Yizhen Jia, Rui Pan, Shizhe Diao, Renjie Pi, Tong Zhang
分类: cs.FL, cs.AI
发布日期: 2024-07-03 (更新: 2024-10-04)
💡 一句话要点
TheoremLlama:将通用LLM转化为Lean4专家,提升形式化定理证明能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 形式化定理证明 大型语言模型 Lean4 自然语言推理 数据引导 课程学习 迭代证明
📋 核心要点
- 现有LLM在形式化定理证明方面表现不佳,主要原因是缺乏对齐的自然语言(NL)和形式语言(FL)定理证明数据。
- TheoremLlama通过NL-FL数据集生成、课程学习和迭代证明编写等方法,将通用LLM训练为Lean4专家,提升形式化证明能力。
- 实验结果表明,TheoremLlama在MiniF2F数据集上显著优于GPT-4,验证了该框架的有效性。
📝 摘要(中文)
本文提出了TheoremLlama,一个端到端框架,旨在将通用大型语言模型(LLM)训练成Lean4专家,以解决自然语言(NL)与形式语言(FL)定理证明数据稀缺的问题。TheoremLlama包含NL-FL数据集生成和引导方法以获取对齐的数据集,课程学习和分块训练技术来训练模型,以及迭代证明编写方法来编写有效的Lean4证明。通过TheoremLlama的数据集生成方法,我们提供了Open Bootstrapped Theorems (OBT),一个NL-FL对齐和引导数据集。我们新颖的NL-FL引导方法将NL证明集成到Lean4代码中用于训练数据集,从而利用LLM的NL推理能力进行形式推理。TheoremLlama框架在MiniF2F-Valid和Test数据集上分别实现了36.48%和33.61%的累积准确率,超过了GPT-4的22.95%和25.41%的基线。
🔬 方法详解
问题定义:现有方法在利用大型语言模型(LLM)进行形式化定理证明时,面临着自然语言(NL)和形式语言(FL)数据对齐不足的挑战。这导致LLM难以有效地学习和生成正确的形式化证明,阻碍了其在数学推理领域的应用。现有方法难以充分利用LLM的自然语言推理能力来辅助形式化证明。
核心思路:TheoremLlama的核心思路是通过引导(bootstrapping)的方式,生成高质量的NL-FL对齐数据集,并结合课程学习和迭代证明编写技术,逐步提升LLM在Lean4形式化语言中的证明能力。该方法旨在弥合自然语言推理和形式化推理之间的差距,充分利用LLM的潜力。
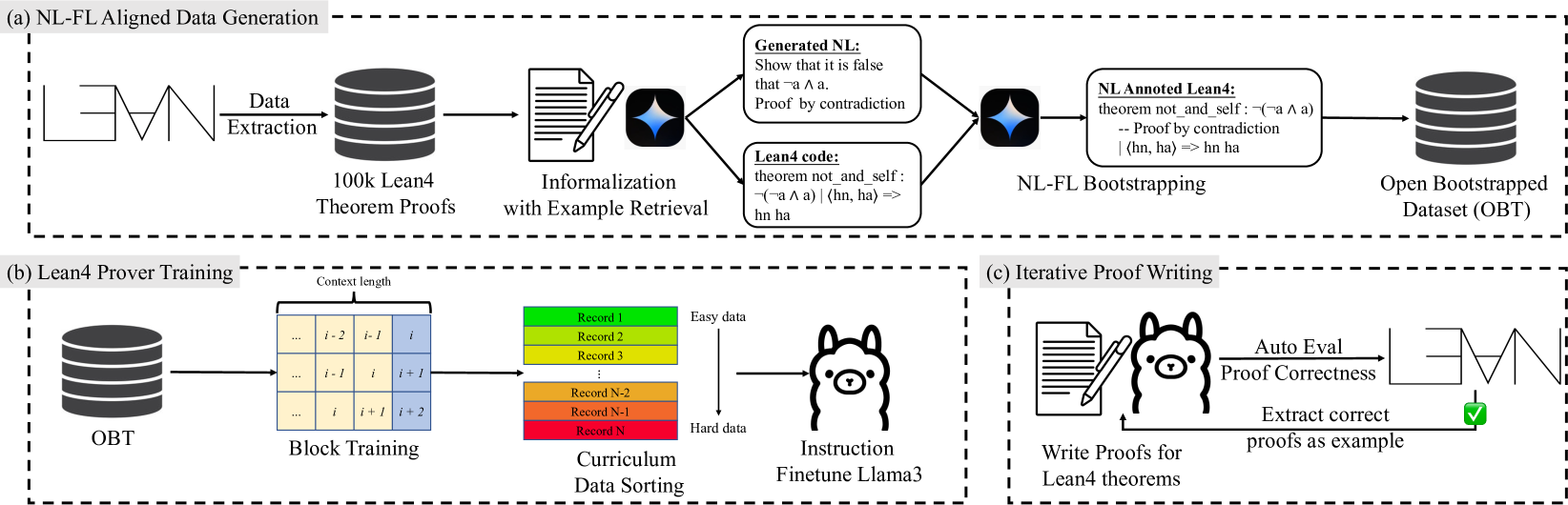
技术框架:TheoremLlama框架包含三个主要组成部分:1) NL-FL数据集生成和引导:用于创建对齐的训练数据;2) 课程学习和分块训练:用于有效地训练LLM;3) 迭代证明编写:用于生成完整的Lean4证明。该框架首先生成包含自然语言证明的Lean4代码,然后使用这些数据训练LLM,最后通过迭代的方式完善生成的证明。
关键创新:TheoremLlama的关键创新在于其NL-FL引导方法,该方法将自然语言证明集成到Lean4代码中,从而利用LLM的自然语言推理能力来辅助形式化推理。此外,课程学习和分块训练技术也有助于提高模型的训练效率和性能。迭代证明编写方法则能够逐步完善生成的证明,提高其正确性。
关键设计:TheoremLlama使用了Open Bootstrapped Theorems (OBT)数据集,这是一个NL-FL对齐和引导数据集。训练过程中采用了课程学习策略,从简单的定理开始,逐步增加难度。分块训练技术将证明过程分解为多个步骤,分别进行训练。迭代证明编写方法通过多次迭代,不断修正和完善生成的Lean4证明。
🖼️ 关键图片

📊 实验亮点
TheoremLlama在MiniF2F-Valid和Test数据集上分别取得了36.48%和33.61%的累积准确率,显著超过了GPT-4的22.95%和25.41%。这一结果表明,TheoremLlama框架能够有效地将通用LLM转化为Lean4专家,并在形式化定理证明方面取得显著提升。
🎯 应用场景
TheoremLlama的研究成果可应用于自动化定理证明、形式化验证等领域,有助于提高数学研究和软件开发的效率和可靠性。该技术还可用于教育领域,帮助学生学习和理解形式化证明。未来,该研究有望推动人工智能在数学领域的更广泛应用。
📄 摘要(原文)
Proving mathematical theorems using computer-verifiable formal languages like Lean significantly impacts mathematical reasoning. One approach to formal theorem proving involves generating complete proofs using Large Language Models (LLMs) based on Natural Language (NL) proofs. However, due to the scarcity of aligned NL and Formal Language (FL) theorem-proving data most modern LLMs exhibit suboptimal performance.This scarcity results in a paucity of methodologies for training LLMs and techniques to fully utilize their capabilities in composing formal proofs. To address these challenges, this paper proposes TheoremLlama, an end-to-end framework that trains a general-purpose LLM to be a Lean4 expert. TheoremLlama includes NL-FL dataset generation and bootstrapping method to obtain aligned dataset, curriculum learning and block training techniques to train the model, and iterative proof writing method to write Lean4 proofs that work together synergistically. Using the dataset generation method in TheoremLlama, we provide Open Bootstrapped Theorems (OBT), an NL-FL aligned and bootstrapped dataset. Our novel NL-FL bootstrapping method, where NL proofs are integrated into Lean4 code for training datasets, leverages the NL reasoning ability of LLMs for formal reasoning. The TheoremLlama framework achieves cumulative accuracies of 36.48% and 33.61% on MiniF2F-Valid and Test datasets respectively, surpassing the GPT-4 baseline of 22.95% and 25.41%. Our code, model checkpoints, and the generated dataset is published in GitHub