Multi-Peptide: Multimodality Leveraged Language-Graph Learning of Peptide Properties
作者: Srivathsan Badrinarayanan, Chakradhar Guntuboina, Parisa Mollaei, Amir Barati Farimani
分类: q-bio.QM, cs.AI, cs.LG
发布日期: 2024-07-02
💡 一句话要点
Multi-Peptide:融合语言模型与图神经网络的多模态肽性质预测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 肽性质预测 多模态学习 图神经网络 Transformer 对比学习
📋 核心要点
- 现有肽性质预测方法难以有效融合序列信息和结构信息,限制了预测精度。
- Multi-Peptide结合PeptideBERT和GNN,利用CLIP将序列和结构信息嵌入到共享潜在空间。
- 实验表明,Multi-Peptide在溶血预测中达到86.185%的准确率,显著提升了预测性能。
📝 摘要(中文)
本研究提出了一种名为Multi-Peptide的创新方法,它结合了基于Transformer的语言模型和图神经网络(GNNs)来预测肽的性质。Multi-Peptide将专为肽性质预测定制的Transformer模型PeptideBERT与GNN编码器相结合,以捕获基于序列和结构的特征。通过采用对比语言-图像预训练(CLIP),Multi-Peptide将来自两种模态的嵌入对齐到共享的潜在空间中,从而提高模型的预测准确性。在溶血和防污数据集上的评估表明了Multi-Peptide的鲁棒性,在溶血预测中达到了最先进的86.185%的准确率。这项研究突出了多模态学习在生物信息学中的潜力,为基于肽的研究和应用中的准确和可靠的预测铺平了道路。
🔬 方法详解
问题定义:论文旨在解决肽性质预测问题,现有方法通常只关注肽的序列信息或结构信息,难以有效融合两种模态的信息,导致预测精度不高。此外,不同模态的数据表示形式差异较大,增加了融合的难度。
核心思路:论文的核心思路是利用多模态学习,将肽的序列信息和结构信息融合到一个统一的表示空间中。具体来说,使用Transformer模型(PeptideBERT)提取序列特征,使用图神经网络(GNN)提取结构特征,然后利用对比学习(CLIP)将两种特征嵌入到共享的潜在空间中。这样设计的目的是为了充分利用肽的序列和结构信息,提高预测精度。
技术框架:Multi-Peptide的整体架构包含以下几个主要模块:1) PeptideBERT:用于提取肽序列的特征表示;2) GNN编码器:用于提取肽结构的特征表示;3) CLIP模块:用于将序列特征和结构特征对齐到共享的潜在空间;4) 预测模块:基于融合后的特征进行肽性质预测。整个流程是先分别提取序列和结构特征,然后通过CLIP进行模态对齐,最后进行性质预测。
关键创新:论文最重要的技术创新点在于利用CLIP进行多模态特征对齐。CLIP原本用于图像和文本的对齐,论文将其应用于肽的序列和结构特征对齐,有效解决了不同模态数据表示形式差异大的问题。此外,将PeptideBERT与GNN结合,充分利用了肽的序列和结构信息,这也是一个创新点。
关键设计:论文的关键设计包括:1) PeptideBERT的预训练:使用大规模肽序列数据预训练PeptideBERT,使其能够更好地提取肽序列的特征;2) GNN的选择:选择合适的GNN结构,使其能够有效地提取肽结构的特征;3) CLIP的损失函数:设计合适的对比损失函数,使得序列特征和结构特征在共享潜在空间中尽可能接近;4) 预测模块的设计:根据具体的肽性质预测任务,设计合适的预测模型。
🖼️ 关键图片

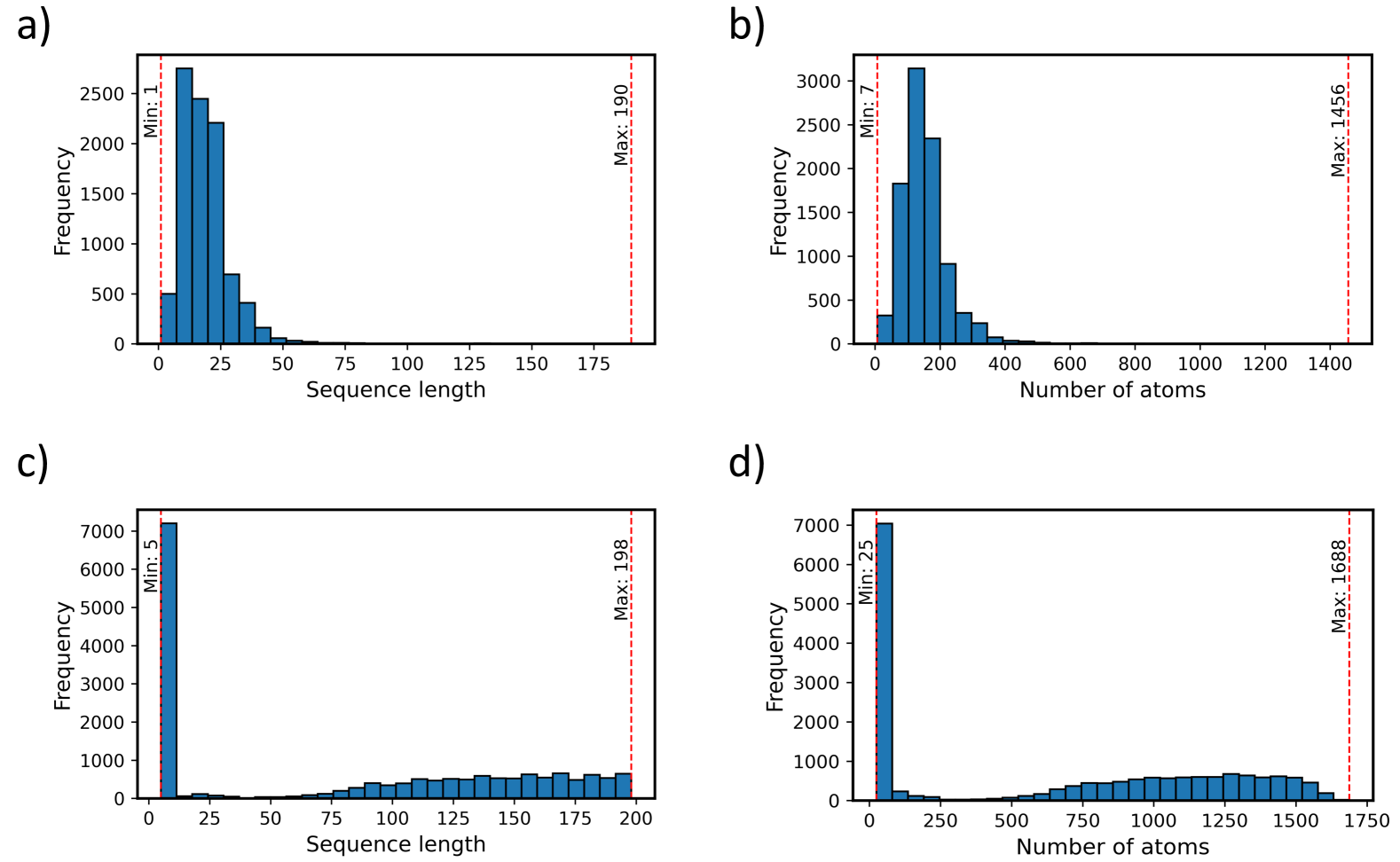
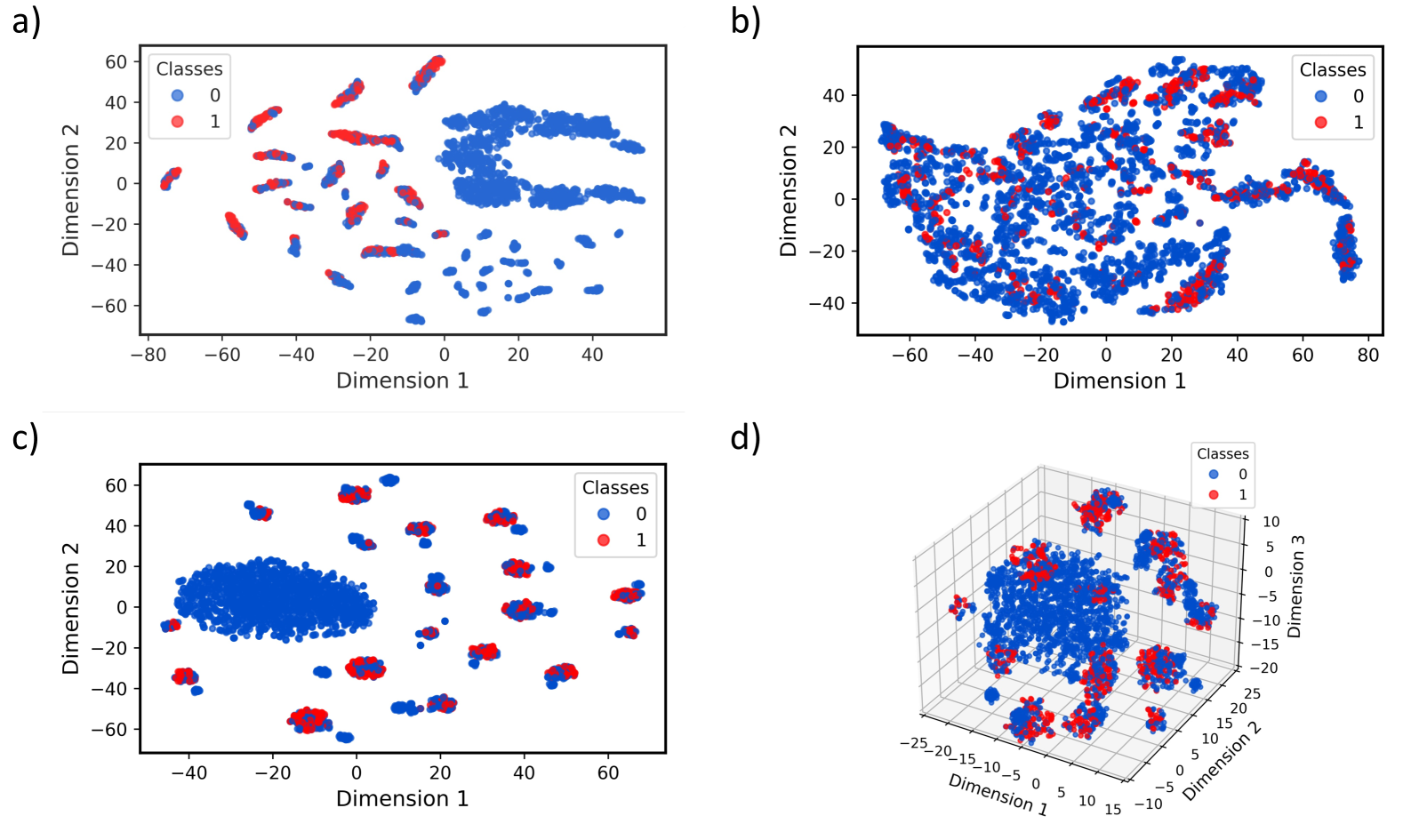
📊 实验亮点
Multi-Peptide在溶血预测任务上取得了显著的性能提升,达到了86.185%的准确率,超越了现有的state-of-the-art方法。实验结果表明,多模态融合能够有效提高肽性质预测的精度,验证了Multi-Peptide的有效性和鲁棒性。
🎯 应用场景
Multi-Peptide在生物医药领域具有广泛的应用前景,例如:1) 药物发现:预测肽的生物活性,加速药物筛选过程;2) 材料科学:预测肽的防污性能,设计新型生物材料;3) 蛋白质工程:预测肽的稳定性,优化蛋白质结构。该研究有望推动肽基药物和材料的研发,具有重要的实际价值和未来影响。
📄 摘要(原文)
Peptides are essential in biological processes and therapeutics. In this study, we introduce Multi-Peptide, an innovative approach that combines transformer-based language models with Graph Neural Networks (GNNs) to predict peptide properties. We combine PeptideBERT, a transformer model tailored for peptide property prediction, with a GNN encoder to capture both sequence-based and structural features. By employing Contrastive Language-Image Pre-training (CLIP), Multi-Peptide aligns embeddings from both modalities into a shared latent space, thereby enhancing the model's predictive accuracy. Evaluations on hemolysis and nonfouling datasets demonstrate Multi-Peptide's robustness, achieving state-of-the-art 86.185% accuracy in hemolysis prediction. This study highlights the potential of multimodal learning in bioinformatics, paving the way for accurate and reliable predictions in peptide-based research and applications.