Reasoning in Large Language Models: A Geometric Perspective
作者: Romain Cosentino, Sarath Shekkizhar
分类: cs.AI, cs.CL
发布日期: 2024-07-02
💡 一句话要点
通过几何视角分析LLM推理能力,揭示自注意力图密度与模型表达能力的关系
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 自注意力机制 几何分析 内在维度
📋 核心要点
- 大型语言模型在实际应用中的发展关键在于提升其推理能力,而现有方法在理解模型内部机制方面存在不足。
- 本文提出通过几何视角分析LLM的推理能力,核心思想是研究自注意力图的密度与模型表达能力之间的关系。
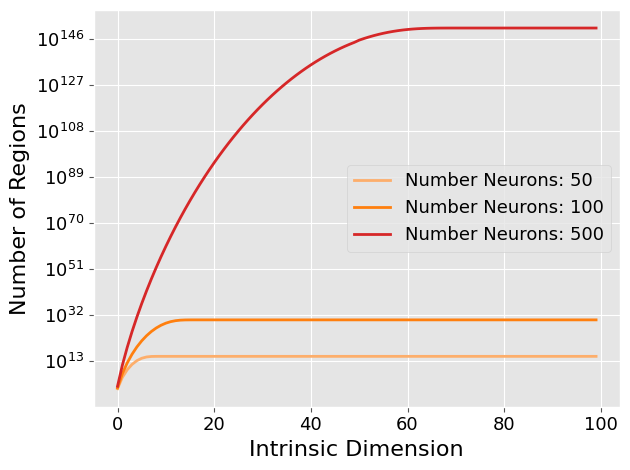
- 理论分析和实验结果表明,自注意力图密度决定的内在维度越高,LLM的表达能力越强,并与现有推理增强方法相关。
📝 摘要(中文)
本文从几何角度探索大型语言模型(LLM)的推理能力。研究建立了LLM的表达能力与其自注意力图密度之间的联系。分析表明,自注意力图的密度决定了MLP块输入数据的内在维度。通过理论分析和玩具示例,证明了更高的内在维度意味着LLM更强的表达能力。此外,本文还提供了经验证据,将这一几何框架与旨在增强LLM推理能力的最新方法联系起来。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理能力提升的问题。现有方法虽然在提升LLM性能方面取得了一定进展,但缺乏对LLM内部推理机制的深入理解,难以解释和进一步优化模型。具体来说,如何量化LLM的表达能力,以及如何将其与推理能力联系起来,是当前研究的痛点。
核心思路:论文的核心思路是将LLM的推理能力与其几何理解联系起来。具体而言,通过分析LLM的自注意力图的密度,来推断MLP块输入数据的内在维度。论文认为,内在维度越高,LLM的表达能力越强,从而推理能力也越强。这种思路将复杂的模型行为转化为几何空间的分析,为理解LLM的推理机制提供了一种新的视角。
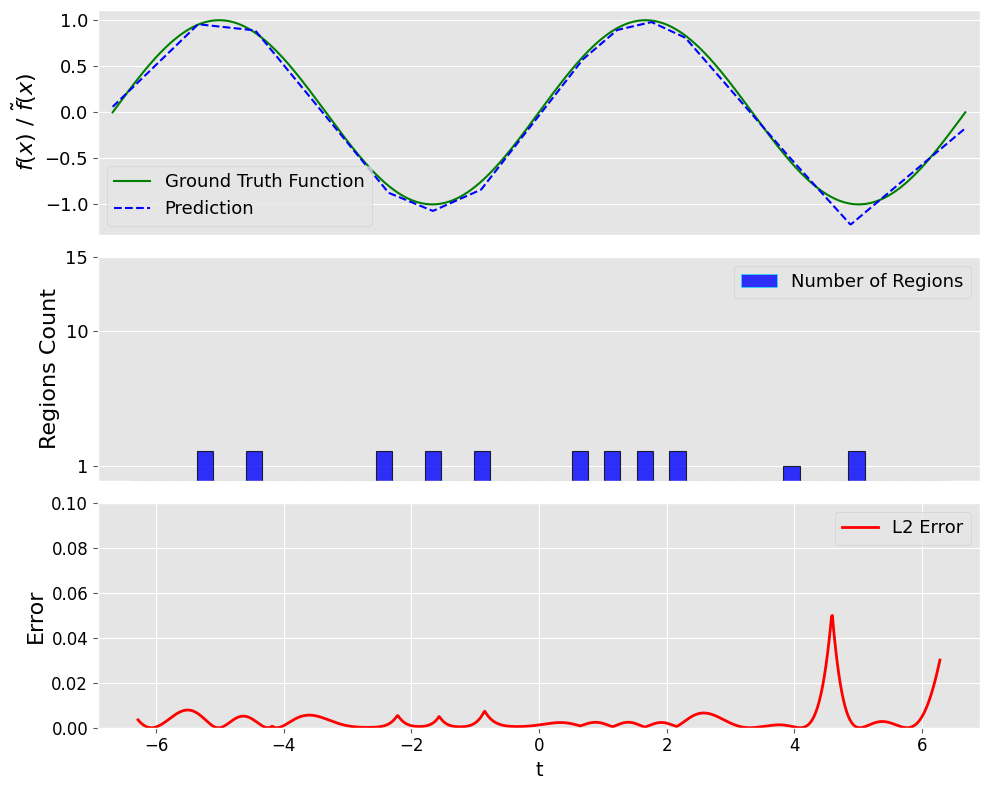
技术框架:论文的技术框架主要包括以下几个部分:1) 理论分析:建立LLM表达能力与自注意力图密度之间的数学关系,推导出内在维度与表达能力之间的联系。2) 玩具示例:通过简单的实验验证理论分析的正确性,例如,设计具有不同内在维度的输入数据,观察LLM的输出结果。3) 经验验证:将几何框架与现有的LLM推理增强方法联系起来,分析这些方法如何影响自注意力图的密度和内在维度,从而提升推理能力。
关键创新:论文最重要的技术创新点在于提出了一个基于几何视角的LLM推理能力分析框架。与以往关注模型结构或训练方法的研究不同,本文从数据内在维度的角度出发,揭示了LLM表达能力与推理能力之间的联系。这种新的视角为理解和提升LLM的推理能力提供了一种新的思路。
关键设计:论文的关键设计包括:1) 自注意力图密度的计算方法:如何有效地衡量自注意力图的密度,并将其转化为内在维度的估计。2) 玩具示例的设计:如何设计具有不同内在维度的输入数据,以便清晰地观察LLM的输出结果。3) 经验验证的方法:如何选择合适的LLM推理增强方法,并分析其对自注意力图密度和内在维度的影响。具体的参数设置、损失函数、网络结构等技术细节在论文中可能没有详细描述,需要进一步查阅原文。
🖼️ 关键图片

📊 实验亮点
论文通过理论分析和实验验证,证明了LLM的表达能力与其自注意力图密度之间存在正相关关系。具体而言,更高的自注意力图密度意味着更高的内在维度,从而带来更强的表达能力和推理能力。虽然论文没有给出具体的性能数据和提升幅度,但其提出的几何框架为理解和提升LLM的推理能力提供了一种新的视角。
🎯 应用场景
该研究成果可应用于提升各种基于LLM的应用,例如智能问答、文本生成、机器翻译等。通过优化LLM的自注意力机制,提高其表达能力和推理能力,从而改善这些应用的性能。此外,该研究也为LLM的设计和训练提供了新的思路,有助于开发更强大的LLM模型。
📄 摘要(原文)
The advancement of large language models (LLMs) for real-world applications hinges critically on enhancing their reasoning capabilities. In this work, we explore the reasoning abilities of large language models (LLMs) through their geometrical understanding. We establish a connection between the expressive power of LLMs and the density of their self-attention graphs. Our analysis demonstrates that the density of these graphs defines the intrinsic dimension of the inputs to the MLP blocks. We demonstrate through theoretical analysis and toy examples that a higher intrinsic dimension implies a greater expressive capacity of the LLM. We further provide empirical evidence linking this geometric framework to recent advancements in methods aimed at enhancing the reasoning capabilities of LLMs.