Multi-Agent Training for Pommerman: Curriculum Learning and Population-based Self-Play Approach
作者: Nhat-Minh Huynh, Hoang-Giang Cao, I-Chen Wu
分类: cs.MA, cs.AI
发布日期: 2024-06-30 (更新: 2025-01-08)
备注: Accepted at The First Workshop on Game AI Algorithms and Multi-Agent Learning - IJCAI 2024
💡 一句话要点
提出基于课程学习和群体自博弈的Pommerman多智能体训练方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体 强化学习 课程学习 群体自博弈 Pommerman 稀疏奖励 Elo评分
📋 核心要点
- Pommerman环境因其延迟奖励、稀疏奖励和对手自失误等特性,对多智能体强化学习构成挑战。
- 论文提出结合课程学习和群体自博弈的训练框架,并设计自适应退火因子和Elo评分匹配机制。
- 实验结果表明,该方法训练的智能体在Pommerman游戏中表现优异,无需智能体间通信即可超越现有方法。
📝 摘要(中文)
Pommerman是一个多智能体环境,近年来受到了研究人员的广泛关注。该环境是多智能体训练的理想基准,为具有通信能力的两个团队提供了一个战场。由于延迟的行动效果、稀疏的奖励和假阳性(对手玩家可能因自身失误而失败),Pommerman对无模型强化学习提出了重大挑战。本研究介绍了一种系统,该系统旨在使用课程学习和基于群体的自博弈相结合的方法来训练多智能体系统玩Pommerman。我们还解决了在竞争性游戏中部署多智能体训练系统时面临的两个具有挑战性的问题:稀疏奖励和合适的匹配机制。具体来说,我们提出了一种基于智能体性能的自适应退火因子,以动态调整训练期间的密集探索奖励。此外,我们还实施了一种利用 Elo 评分系统来有效配对智能体的匹配机制。我们的实验结果表明,我们训练的智能体可以优于顶级的学习智能体,而无需盟友智能体之间的通信。
🔬 方法详解
问题定义:Pommerman环境中的多智能体训练面临稀疏奖励和对手自失误导致的训练不稳定问题。现有方法难以有效探索环境,且难以区分自身策略的优劣。此外,如何设计有效的匹配机制,使智能体能够与合适的对手进行训练,也是一个挑战。
核心思路:论文的核心思路是结合课程学习和群体自博弈,逐步提升智能体的能力。通过课程学习,智能体从简单的任务开始学习,逐渐过渡到复杂的任务。群体自博弈则允许智能体与不同能力的对手进行训练,从而提高泛化能力。自适应退火因子用于动态调整探索奖励,Elo评分系统用于实现有效的匹配。
技术框架:该系统包含以下主要模块:1) 课程学习模块,用于定义一系列难度递增的任务;2) 群体自博弈模块,维护一个智能体池,并从中选择对手进行训练;3) 奖励塑造模块,使用自适应退火因子动态调整探索奖励;4) 匹配模块,使用Elo评分系统对智能体进行排序和匹配。训练流程如下:首先,智能体在课程学习的不同阶段进行训练。然后,智能体进入群体自博弈池,并根据Elo评分与其他智能体进行匹配。在训练过程中,奖励塑造模块动态调整探索奖励。
关键创新:论文的关键创新在于以下几点:1) 结合课程学习和群体自博弈,提高了训练的稳定性和效率;2) 提出了一种自适应退火因子,可以根据智能体的性能动态调整探索奖励,解决了稀疏奖励问题;3) 采用Elo评分系统进行匹配,保证了智能体能够与合适的对手进行训练。
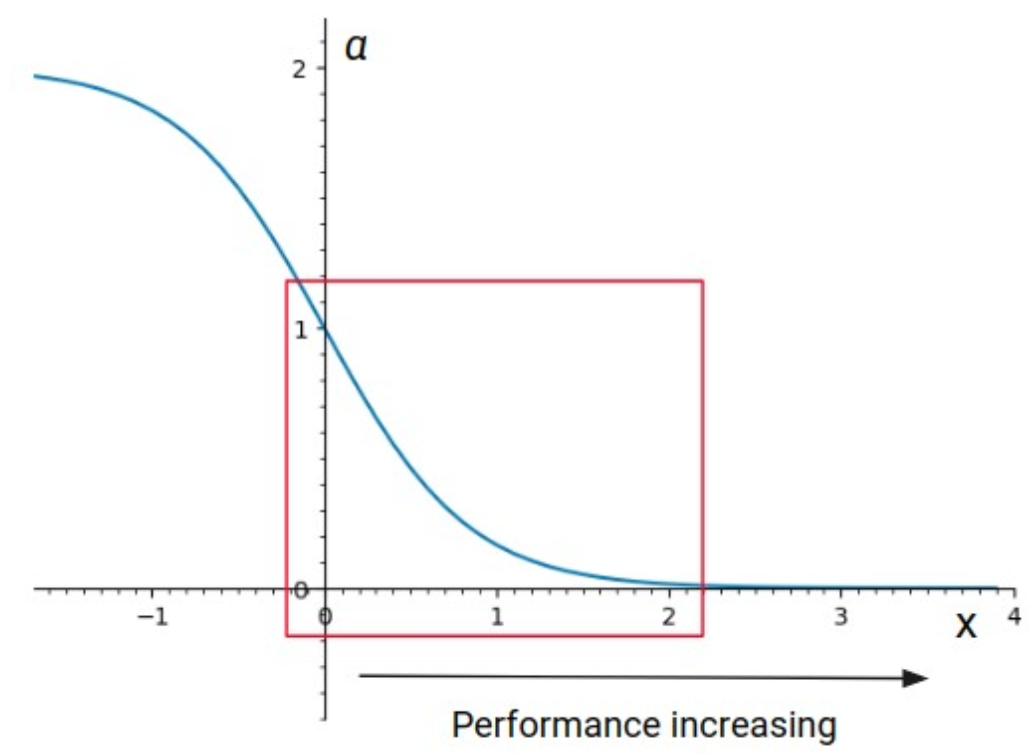
关键设计:自适应退火因子根据智能体的胜率动态调整探索奖励的权重。具体来说,当智能体的胜率较高时,降低探索奖励的权重,鼓励智能体利用已学到的策略;当智能体的胜率较低时,增加探索奖励的权重,鼓励智能体探索新的策略。Elo评分系统用于对智能体进行排序,并根据评分差异选择对手。匹配时,优先选择评分相近的智能体,以保证训练的难度适中。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法训练的智能体在Pommerman游戏中表现优异,无需智能体间通信即可超越顶级的学习智能体。具体来说,该方法在多个Pommerman比赛中取得了领先地位,证明了其有效性和鲁棒性。与现有方法相比,该方法在训练效率和最终性能方面均有显著提升。
🎯 应用场景
该研究成果可应用于其他多智能体博弈环境,例如星际争霸II和王者荣耀等。通过结合课程学习和群体自博弈,可以有效提高智能体的训练效率和泛化能力。此外,自适应退火因子和Elo评分匹配机制也可以应用于其他强化学习任务,以解决稀疏奖励和训练不稳定的问题。该研究对于开发更强大的游戏AI和解决现实世界中的多智能体协作问题具有重要意义。
📄 摘要(原文)
Pommerman is a multi-agent environment that has received considerable attention from researchers in recent years. This environment is an ideal benchmark for multi-agent training, providing a battleground for two teams with communication capabilities among allied agents. Pommerman presents significant challenges for model-free reinforcement learning due to delayed action effects, sparse rewards, and false positives, where opponent players can lose due to their own mistakes. This study introduces a system designed to train multi-agent systems to play Pommerman using a combination of curriculum learning and population-based self-play. We also tackle two challenging problems when deploying the multi-agent training system for competitive games: sparse reward and suitable matchmaking mechanism. Specifically, we propose an adaptive annealing factor based on agents' performance to adjust the dense exploration reward during training dynamically. Additionally, we implement a matchmaking mechanism utilizing the Elo rating system to pair agents effectively. Our experimental results demonstrate that our trained agent can outperform top learning agents without requiring communication among allied agents.