Deep Reinforcement Learning Strategies in Finance: Insights into Asset Holding, Trading Behavior, and Purchase Diversity
作者: Alireza Mohammadshafie, Akram Mirzaeinia, Haseebullah Jumakhan, Amir Mirzaeinia
分类: q-fin.TR, cs.AI, cs.LG
发布日期: 2024-06-29
💡 一句话要点
分析深度强化学习在金融资产交易中的行为模式与购买多样性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 金融交易 资产配置 交易策略 行为分析
📋 核心要点
- 现有研究对金融领域深度强化学习算法的行为模式分析不足,缺乏对其交易策略和购买多样性的深入理解。
- 通过分析DRL算法的交易行为,揭示其在金融应用中的决策过程,从而理解不同算法的优势与劣势。
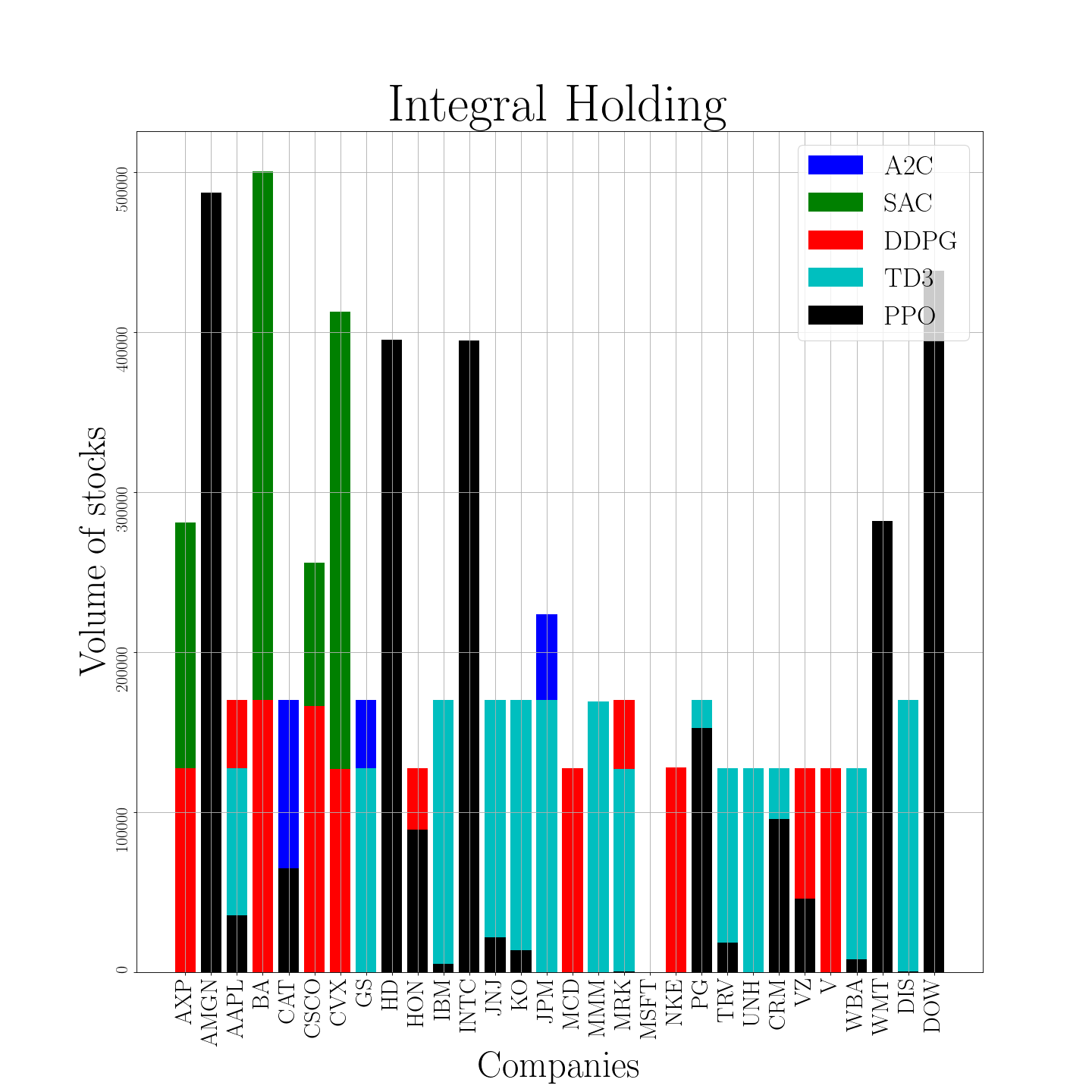
- 实验结果表明,不同DRL算法具有独特的交易模式,A2C在累积奖励方面表现突出,其他算法在交易频率和持仓时间上各有差异。
📝 摘要(中文)
本文旨在研究金融领域中深度强化学习(DRL)算法的行为模式,包括其持有或交易金融资产的倾向以及购买多样性。通过分析这些算法的交易行为,深入了解DRL模型在金融应用中的决策过程。研究结果表明,不同的DRL算法表现出独特的交易模式和策略,其中A2C在累积奖励方面表现最佳。PPO和SAC倾向于进行大量股票交易,但股票种类有限,而DDPG和TD3则采取更为平衡的方法。此外,SAC和PPO的持仓时间较短,而DDPG、A2C和TD3则倾向于长时间保持静止。
🔬 方法详解
问题定义:论文旨在解决金融领域中,如何理解和解释深度强化学习(DRL)算法在资产交易中的行为模式的问题。现有方法缺乏对DRL算法交易行为的深入分析,无法解释其决策过程,限制了DRL在金融领域的应用和优化。
核心思路:论文的核心思路是通过分析不同DRL算法在金融市场中的交易行为,包括持仓时间、交易频率、购买多样性等指标,来揭示其内在的交易策略和决策逻辑。通过对比不同算法的交易模式,可以更好地理解其优缺点,并为未来的算法设计提供指导。
技术框架:论文采用了一种实证研究的方法,首先选择了几种常用的DRL算法,包括A2C、PPO、SAC、DDPG和TD3。然后,在金融市场环境中训练这些算法,并记录其交易行为。最后,对这些交易行为进行统计分析,包括持仓时间、交易频率、购买多样性等指标,并进行对比分析。
关键创新:论文的关键创新在于其对DRL算法在金融领域中的交易行为进行了深入的分析和解释。以往的研究主要关注DRL算法的性能指标,如累积奖励等,而忽略了对其交易行为的分析。通过分析交易行为,可以更好地理解DRL算法的决策过程,并为未来的算法设计提供指导。
关键设计:论文的关键设计包括:1) 选择具有代表性的DRL算法,如A2C、PPO、SAC、DDPG和TD3;2) 在真实的金融市场环境中训练这些算法;3) 设计合理的指标来衡量交易行为,如持仓时间、交易频率、购买多样性等;4) 采用统计分析方法对交易行为进行对比分析。
🖼️ 关键图片

📊 实验亮点
研究发现,A2C算法在累积奖励方面表现最佳。PPO和SAC倾向于进行大量交易,但股票种类有限,而DDPG和TD3则采取更为平衡的方法。SAC和PPO的持仓时间较短,而DDPG、A2C和TD3则倾向于长时间保持静止。这些发现揭示了不同DRL算法在金融市场中的独特交易模式。
🎯 应用场景
该研究成果可应用于量化交易策略的设计与优化,帮助投资者更好地理解和选择合适的DRL算法。通过分析DRL算法的交易行为,可以为风险管理提供参考,并促进DRL在金融领域的更广泛应用。此外,该研究还可以为金融监管提供一定的理论基础,帮助监管机构更好地理解和监管基于DRL的金融产品。
📄 摘要(原文)
Recent deep reinforcement learning (DRL) methods in finance show promising outcomes. However, there is limited research examining the behavior of these DRL algorithms. This paper aims to investigate their tendencies towards holding or trading financial assets as well as purchase diversity. By analyzing their trading behaviors, we provide insights into the decision-making processes of DRL models in finance applications. Our findings reveal that each DRL algorithm exhibits unique trading patterns and strategies, with A2C emerging as the top performer in terms of cumulative rewards. While PPO and SAC engage in significant trades with a limited number of stocks, DDPG and TD3 adopt a more balanced approach. Furthermore, SAC and PPO tend to hold positions for shorter durations, whereas DDPG, A2C, and TD3 display a propensity to remain stationary for extended periods.