Beyond Functional Correctness: Investigating Coding Style Inconsistencies in Large Language Models
作者: Yanlin Wang, Tianyue Jiang, Mingwei Liu, Jiachi Chen, Mingzhi Mao, Xilin Liu, Yuchi Ma, Zibin Zheng
分类: cs.SE, cs.AI
发布日期: 2024-06-29 (更新: 2025-06-21)
备注: 13pages, 14 figures
💡 一句话要点
研究大型语言模型代码风格与人类开发者差异,提出不一致性分类体系。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 编码风格 代码质量 实证分析
📋 核心要点
- 现有研究主要关注LLM代码生成的准确性,忽略了其与人类开发者在代码风格上的差异。
- 通过人工分析大量生成结果,总结代码风格不一致的类型,并从可读性、简洁性和鲁棒性等方面进行比较。
- 实验结果表明LLM与人类开发者存在显著的编码风格差异,并探讨了潜在原因及缓解方案。
📝 摘要(中文)
大型语言模型(LLMs)为代码生成领域带来了范式转变,具有增强软件开发过程的潜力。然而,以往的研究主要集中在代码生成的准确性上,而LLMs和人类开发者之间的编码风格差异仍未得到充分探索。本文实证分析了主流代码LLMs生成的代码与人类开发者编写的代码在编码风格上的差异,并总结了编码风格不一致性分类体系。具体来说,我们首先通过手动分析大量的生成结果来总结编码风格不一致的类型。然后,我们从可读性、简洁性和鲁棒性等方面比较了代码LLMs生成的代码与人类程序员编写的代码。结果表明,LLMs和开发者具有不同的编码风格。此外,我们研究了这些不一致性的可能原因,并提供了一些缓解该问题的方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在代码生成过程中与人类开发者在编码风格上存在差异的问题。现有研究主要关注代码功能的正确性,而忽略了代码的可读性、简洁性和鲁棒性等风格因素,这可能导致生成的代码难以维护和理解。
核心思路:论文的核心思路是通过实证分析,对比LLMs生成的代码和人类开发者编写的代码,识别并分类编码风格上的不一致性。通过深入分析这些不一致性,可以更好地理解LLMs的代码生成机制,并为改进LLMs的代码生成能力提供指导。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据收集:收集由主流代码LLMs生成的代码和人类开发者编写的代码。2) 不一致性类型总结:通过人工分析大量生成结果,总结编码风格不一致的类型,例如命名规范、代码结构、注释风格等。3) 对比分析:从可读性、简洁性和鲁棒性等方面比较LLMs生成的代码与人类编写的代码。4) 原因分析:研究导致这些不一致性的可能原因,例如训练数据偏差、模型架构限制等。5) 缓解方案:提出一些缓解这些不一致性的方法,例如微调、prompt工程等。
关键创新:论文的关键创新在于首次系统性地研究了LLMs在代码生成过程中与人类开发者在编码风格上的差异,并提出了一个编码风格不一致性分类体系。该体系为后续研究提供了参考框架,有助于更深入地理解LLMs的代码生成行为。
关键设计:论文的关键设计包括:1) 细致的人工分析,用于总结编码风格不一致的类型。2) 多维度的对比分析,从可读性、简洁性和鲁棒性等方面评估代码质量。3) 深入的原因分析,探讨导致不一致性的潜在因素。具体的参数设置、损失函数、网络结构等技术细节未在摘要中提及,属于未知信息。
🖼️ 关键图片


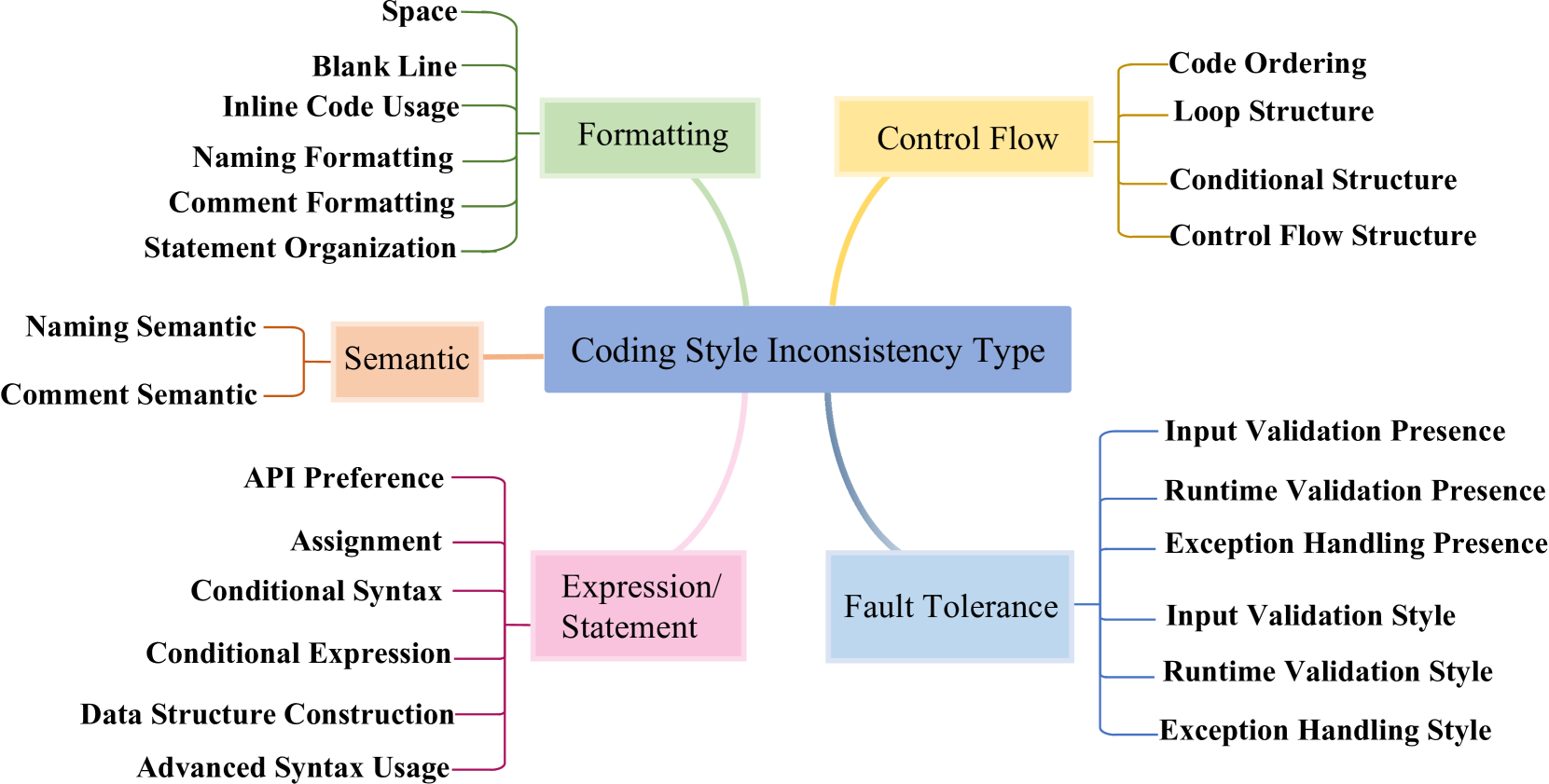
📊 实验亮点
研究结果表明,LLMs在编码风格上与人类开发者存在显著差异,具体体现在可读性、简洁性和鲁棒性等方面。论文总结了编码风格不一致性分类体系,并探讨了这些差异的可能原因,为后续研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于提升代码生成模型的实用性和可维护性,例如,通过调整模型的训练策略或优化prompt设计,使其生成的代码更符合人类开发者的编码习惯。这有助于降低软件开发和维护成本,提高开发效率,并促进人机协作。
📄 摘要(原文)
Large language models (LLMs) have brought a paradigm shift to the field of code generation, offering the potential to enhance the software development process. However, previous research mainly focuses on the accuracy of code generation, while coding style differences between LLMs and human developers remain under-explored. In this paper, we empirically analyze the differences in coding style between the code generated by mainstream Code LLMs and the code written by human developers, and summarize coding style inconsistency taxonomy. Specifically, we first summarize the types of coding style inconsistencies by manually analyzing a large number of generation results. We then compare the code generated by Code LLMs with the code written by human programmers in terms of readability, conciseness, and robustness. The results reveal that LLMs and developers have different coding styles. Additionally, we study the possible causes of these inconsistencies and provide some solutions to alleviate the problem.