GraphArena: Evaluating and Exploring Large Language Models on Graph Computation
作者: Jianheng Tang, Qifan Zhang, Yuhan Li, Nuo Chen, Jia Li
分类: cs.AI, cs.CL
发布日期: 2024-06-29 (更新: 2025-02-15)
备注: ICLR 2025 camera ready version
🔗 代码/项目: GITHUB
💡 一句话要点
GraphArena:用于评估大语言模型在图计算任务上的性能的基准测试工具
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 图计算 基准测试 评估框架 NP完全问题
📋 核心要点
- 现有LLM基准测试在评估其图计算能力方面存在不足,难以反映真实世界图问题的复杂性。
- GraphArena通过提供多项式时间和NP完全图计算任务,以及严格的评估框架,来全面评估LLM的图计算能力。
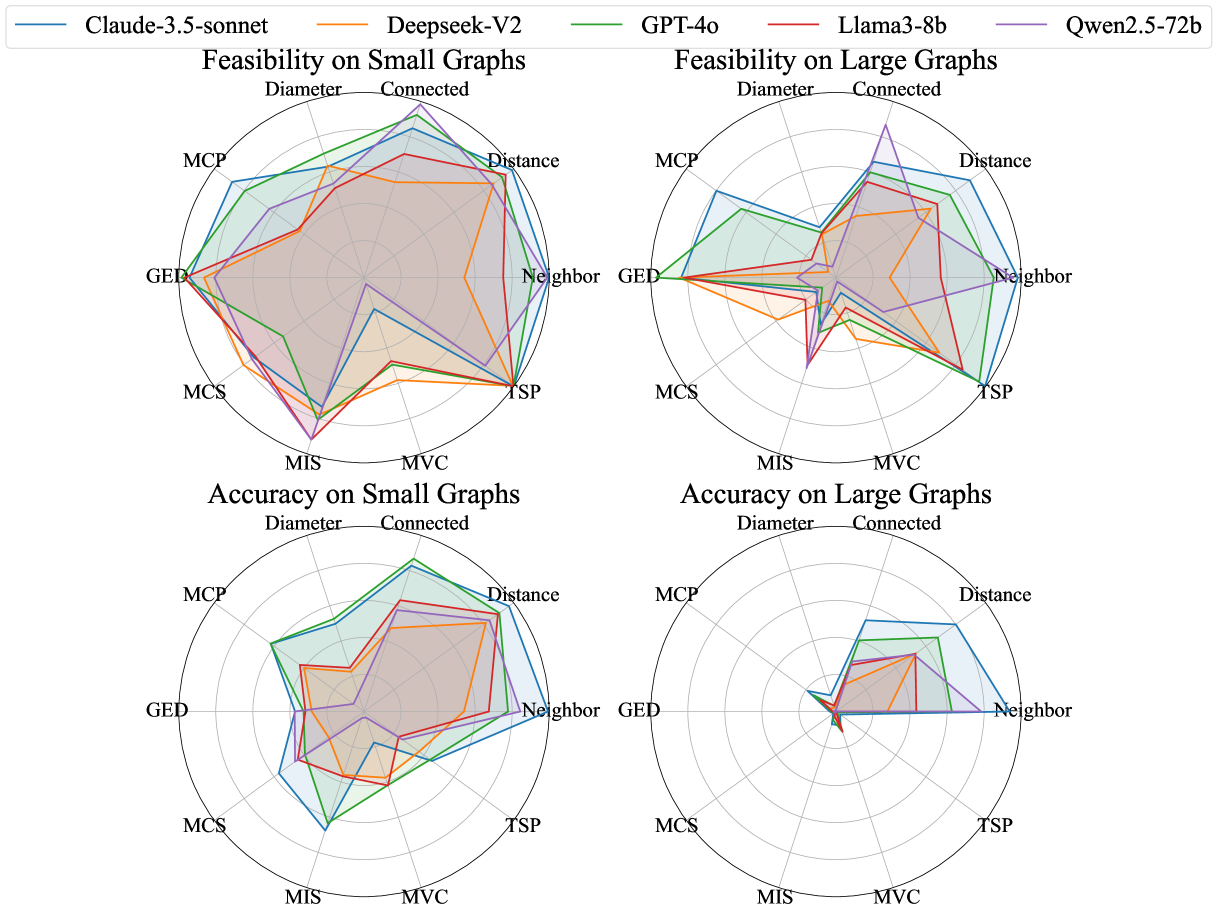
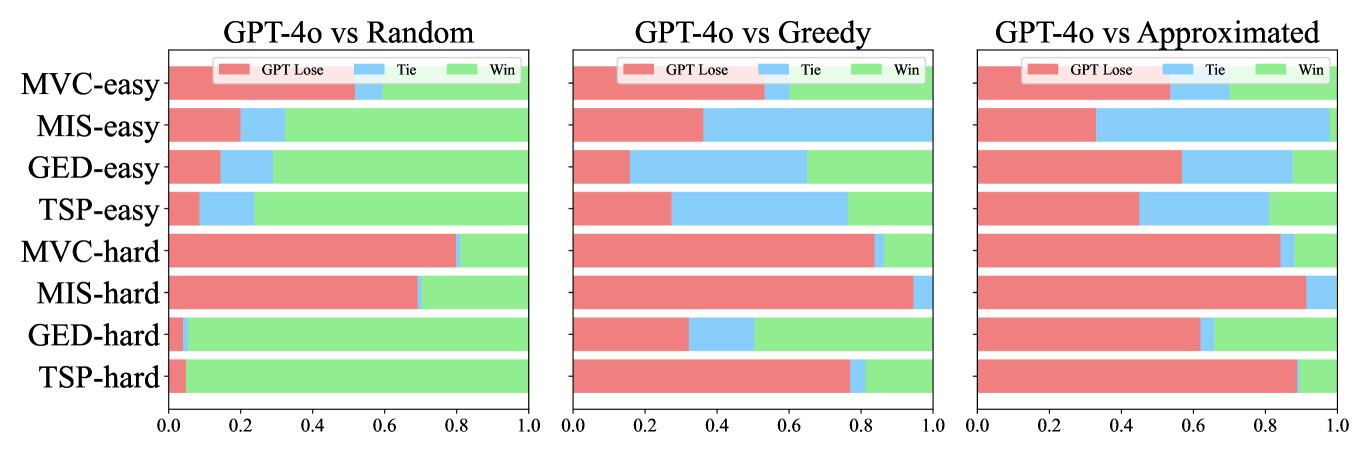
- 实验表明,即使是最先进的LLM在处理复杂图问题时仍存在困难,并容易产生幻觉,需要进一步改进。
📝 摘要(中文)
大语言模型(LLMs)的“军备竞赛”需要新的基准来检验其进展。本文介绍GraphArena,一个旨在评估LLMs在真实世界图计算问题上的基准测试工具。它提供了一套包含四个多项式时间任务(例如,最短距离)和六个NP完全挑战(例如,旅行商问题)的测试集。GraphArena具有严格的评估框架,可将LLM输出分类为正确、次优(可行但非最优)、幻觉(格式正确但不可行)或缺失。对超过10个LLM的评估表明,即使是性能最佳的LLM也难以应对更大、更复杂的图问题,并表现出幻觉问题。我们进一步探索了四种潜在的解决方案来解决这个问题并提高LLM在图计算方面的能力,包括思维链提示、指令调优、代码编写和缩放测试时计算,每种方法都展示了独特的优势和局限性。GraphArena是对现有LLM基准的补充,并在https://github.com/squareRoot3/GraphArena上开源。
🔬 方法详解
问题定义:论文旨在评估和提升大型语言模型(LLMs)在图计算问题上的能力。现有方法缺乏专门针对图计算的基准测试,无法有效评估LLMs在处理复杂图结构和算法时的性能,并且LLMs在图计算中容易出现“幻觉”问题,即生成格式正确但结果错误的答案。
核心思路:论文的核心思路是构建一个全面的图计算基准测试平台GraphArena,包含多种难度级别的图计算任务,并设计严格的评估指标,以准确评估LLMs的图计算能力。同时,探索不同的方法来提升LLMs在图计算任务上的表现,例如思维链提示、指令调优、代码生成等。
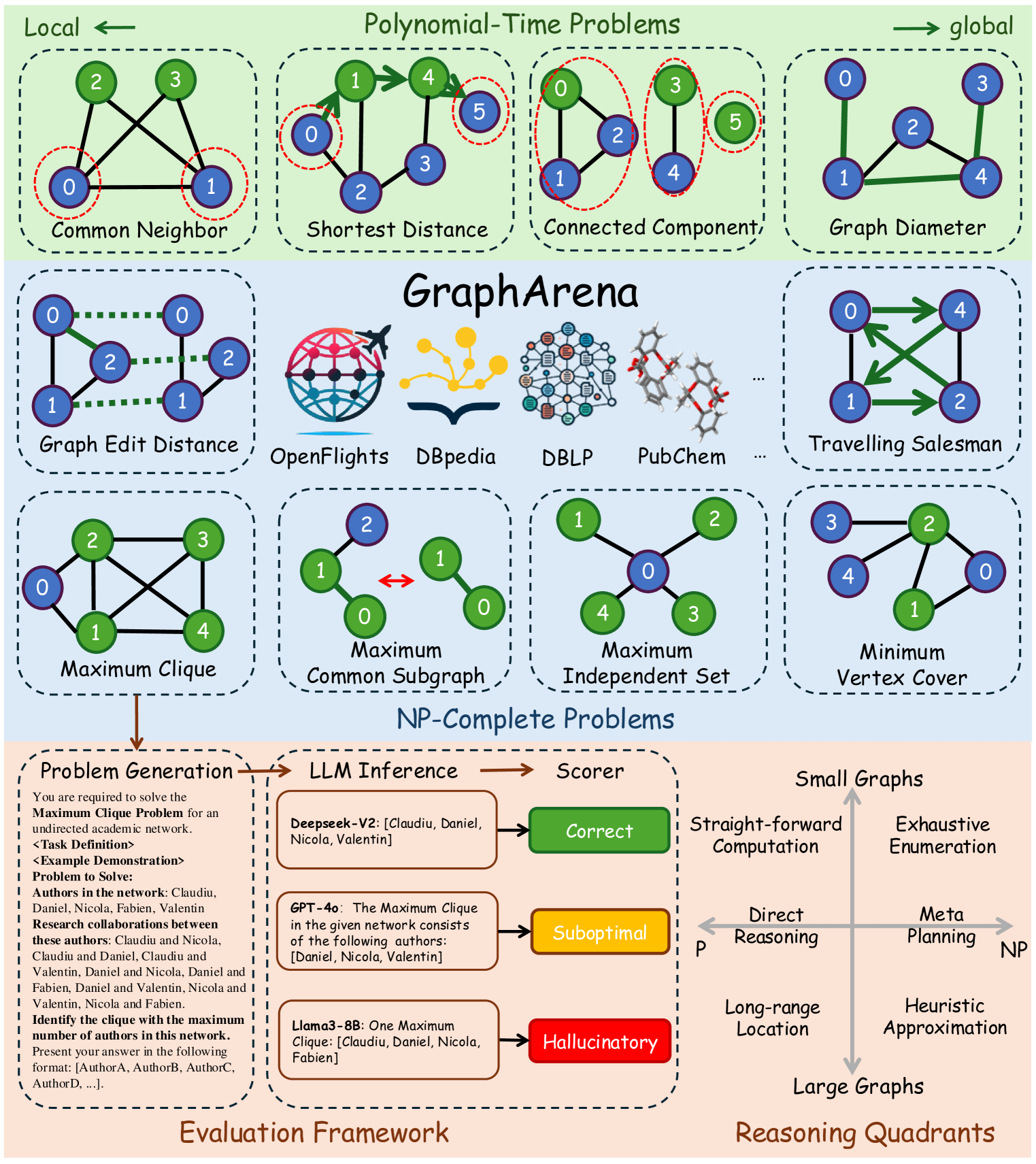
技术框架:GraphArena包含以下主要模块:1) 图计算任务生成器:生成包含多项式时间和NP完全问题的图计算任务。2) LLM接口:与各种LLMs进行交互,输入图计算任务并获取LLM的输出。3) 评估模块:根据预定义的评估指标,对LLM的输出进行评估,包括正确率、次优率、幻觉率等。4) 改进策略:探索不同的方法来提升LLMs在图计算任务上的表现。
关键创新:GraphArena的关键创新在于:1) 提出了一个专门针对图计算任务的基准测试平台,填补了现有LLM基准测试的空白。2) 设计了严格的评估框架,能够准确评估LLMs在图计算任务上的性能。3) 探索了多种提升LLMs图计算能力的方法,并分析了它们的优缺点。
关键设计:GraphArena的关键设计包括:1) 图计算任务的多样性:包含多种难度级别的图计算任务,例如最短路径、旅行商问题等。2) 评估指标的全面性:包括正确率、次优率、幻觉率等,能够全面评估LLMs的性能。3) 改进策略的针对性:针对LLMs在图计算中容易出现的问题,提出了相应的改进策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是最先进的LLM在处理复杂图问题时仍存在困难,并容易产生幻觉。通过思维链提示、指令调优、代码编写和缩放测试时计算等方法,可以一定程度上提升LLMs在图计算任务上的表现,但仍有很大的提升空间。例如,思维链提示在某些任务上可以显著提高正确率,但也会增加计算成本。
🎯 应用场景
该研究成果可应用于评估和改进LLMs在各种需要图计算能力的场景中的表现,例如:知识图谱推理、社交网络分析、推荐系统、交通网络优化等。通过GraphArena,可以更好地了解LLMs的图计算能力,并开发更有效的算法和模型来解决实际问题。
📄 摘要(原文)
The ``arms race'' of Large Language Models (LLMs) demands new benchmarks to examine their progresses. In this paper, we introduce GraphArena, a benchmarking tool designed to evaluate LLMs on real-world graph computational problems. It offers a suite of four polynomial-time tasks (e.g., Shortest Distance) and six NP-complete challenges (e.g., Traveling Salesman Problem). GraphArena features a rigorous evaluation framework that classifies LLM outputs as correct, suboptimal (feasible but not optimal), hallucinatory (properly formatted but infeasible), or missing. Evaluation of over 10 LLMs reveals that even top-performing LLMs struggle with larger, more complex graph problems and exhibit hallucination issues. We further explore four potential solutions to address this issue and improve LLMs on graph computation, including chain-of-thought prompting, instruction tuning, code writing, and scaling test-time compute, each demonstrating unique strengths and limitations. GraphArena complements the existing LLM benchmarks and is open-sourced at https://github.com/squareRoot3/GraphArena.