One Prompt is not Enough: Automated Construction of a Mixture-of-Expert Prompts
作者: Ruochen Wang, Sohyun An, Minhao Cheng, Tianyi Zhou, Sung Ju Hwang, Cho-Jui Hsieh
分类: cs.AI, cs.CL, cs.LG, stat.ML
发布日期: 2024-06-28
备注: ICML 2024. code available at https://github.com/ruocwang/mixture-of-prompts
期刊: Proceedings of the 41st International Conference on Machine Learning (ICML), Vienna, Austria, 2024
💡 一句话要点
提出混合专家提示(MoP)方法,通过自动化构建专家提示组合来提升LLM在复杂任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 提示工程 混合专家 上下文学习 自动化提示设计
📋 核心要点
- 现有自动化提示设计方法通常只搜索单个指令,限制了LLM在复杂问题空间中的表现。
- MoP方法采用混合专家范式,将问题空间划分为多个子区域,每个区域由一个专门的专家(指令+示例)管理。
- MoP在多个基准测试中取得了显著的性能提升,平均胜率达到81%,优于现有技术。
📝 摘要(中文)
大型语言模型(LLM)在接受语言指令和上下文示例提示时,展现出对新任务强大的泛化能力。由于这种能力对提示的质量非常敏感,因此人们探索了各种自动化指令设计方法。虽然这些方法展示了有希望的结果,但它们也将搜索到的提示限制为单个指令。这种简化显著限制了它们的能力,因为单个无示例指令可能无法覆盖目标任务的整个复杂问题空间。为了缓解这个问题,我们采用了混合专家(Mixture-of-Expert)范式,并将问题空间划分为一组子区域;每个子区域由一个专门的专家管理,该专家配备了指令和一组示例。我们开发了一个两阶段过程来为每个区域构建专门的专家:(1)示例分配:受到上下文学习和核回归之间理论联系的启发,我们根据示例的语义相似性将它们分组到专家;(2)指令分配:每个专家的区域联合搜索指令补充了分配给它的示例,从而产生协同效应。由此产生的方法,代号为混合提示(MoP),在几个主要基准测试中实现了平均81%的胜率,超过了现有技术。
🔬 方法详解
问题定义:现有的大语言模型(LLM)提示方法通常依赖于单个提示指令,这在处理复杂任务时存在局限性。单个提示难以覆盖整个问题空间,导致模型性能受限。因此,如何设计更有效的提示策略,以充分利用LLM的潜力,是本文要解决的核心问题。现有方法的痛点在于其单一性,无法适应复杂任务的多样性。
核心思路:本文的核心思路是借鉴混合专家(Mixture-of-Experts, MoE)的思想,将问题空间划分为多个子区域,并为每个子区域分配一个专门的“专家”。每个专家由一个指令和一组示例组成,共同指导LLM在该子区域内的推理。通过这种方式,可以针对不同的问题子集定制提示,从而提高整体性能。
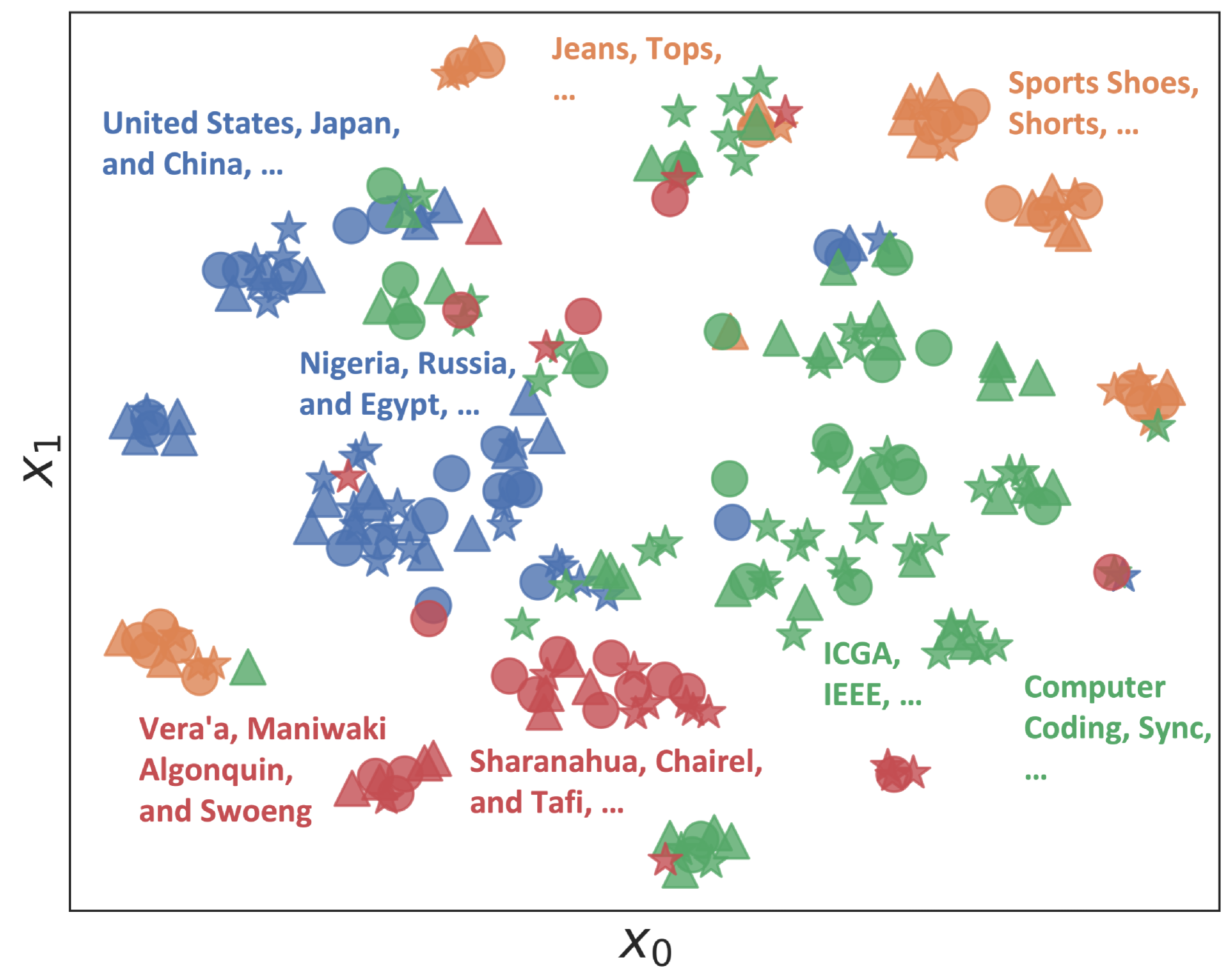
技术框架:MoP方法包含两个主要阶段:(1)示例分配:利用上下文学习与核回归之间的理论联系,基于示例的语义相似性将示例分组到不同的专家。具体而言,计算示例之间的语义相似度,并使用聚类算法将相似的示例分配给同一个专家。(2)指令分配:针对每个专家,联合搜索一个最适合该专家所分配示例的指令。这一过程旨在找到与示例集形成协同效应的指令,从而最大化该专家在对应子区域内的性能。
关键创新:MoP方法的关键创新在于其混合专家提示的架构。与传统的单一提示方法不同,MoP能够根据问题的不同子集,动态地选择最合适的专家进行推理。这种方法能够更好地适应复杂任务的多样性,并充分利用LLM的上下文学习能力。此外,MoP方法还创新性地利用了上下文学习与核回归之间的理论联系,指导示例的分配。
关键设计:在示例分配阶段,可以使用不同的语义相似度度量方法(例如,基于预训练语言模型的嵌入向量的余弦相似度)和聚类算法(例如,K-means)。在指令分配阶段,可以使用强化学习或进化算法等搜索策略,寻找最优的指令。此外,还可以设计特定的损失函数,以鼓励指令与示例之间的协同效应。具体的参数设置和网络结构需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
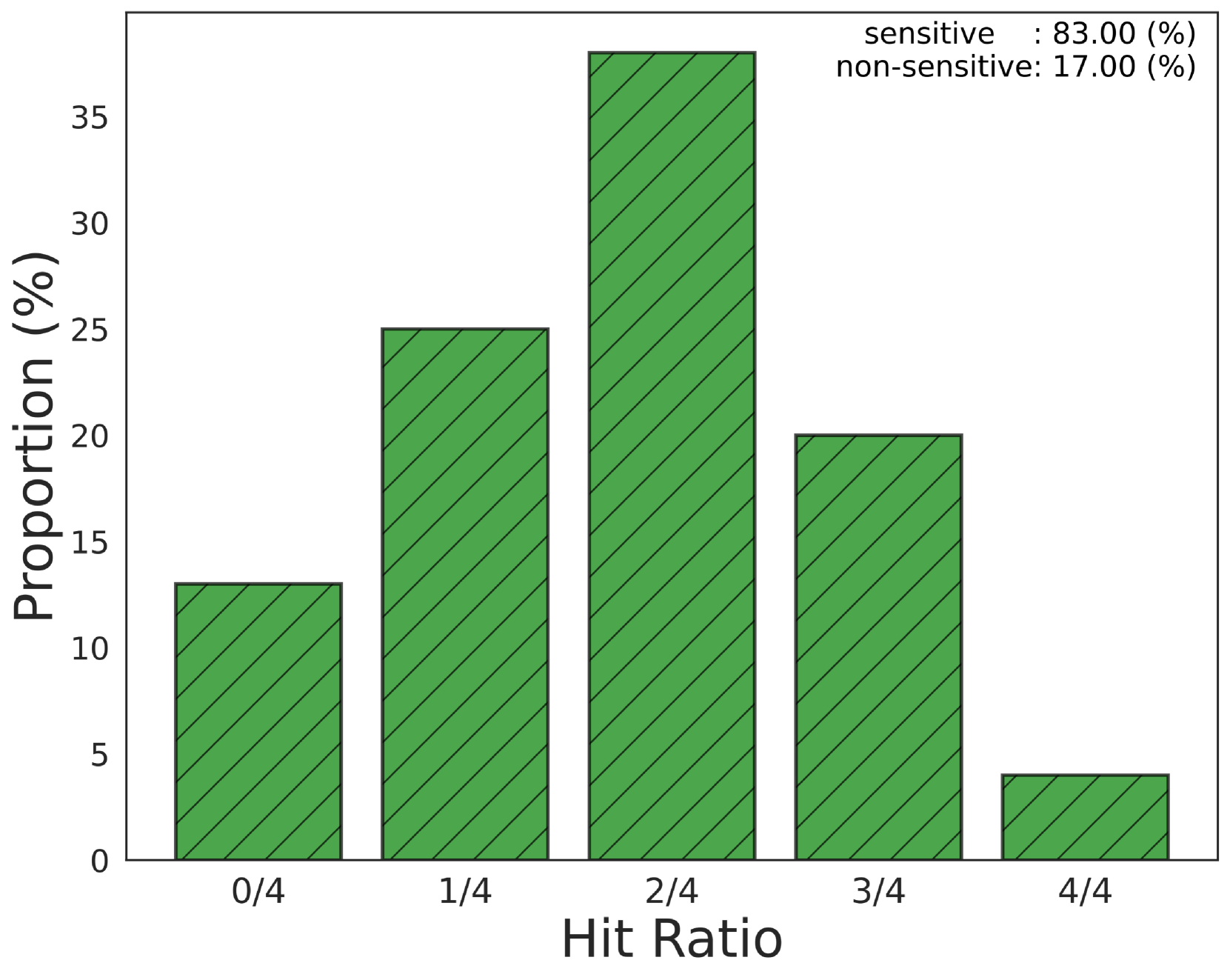
MoP方法在多个基准测试中取得了显著的性能提升。实验结果表明,MoP在平均胜率上达到了81%,显著优于现有的单一提示方法。这一结果表明,混合专家提示是一种有效的提升LLM性能的策略,尤其是在处理复杂任务时。
🎯 应用场景
MoP方法具有广泛的应用前景,可以应用于各种需要利用LLM进行推理和决策的任务,例如自然语言理解、文本生成、问答系统、代码生成等。该方法尤其适用于复杂、多样的任务,例如需要处理不同领域知识的问答系统或需要生成不同风格文本的文本生成任务。MoP的未来影响在于其能够提升LLM在复杂任务上的性能,使其更具实用价值。
📄 摘要(原文)
Large Language Models (LLMs) exhibit strong generalization capabilities to novel tasks when prompted with language instructions and in-context demos. Since this ability sensitively depends on the quality of prompts, various methods have been explored to automate the instruction design. While these methods demonstrated promising results, they also restricted the searched prompt to one instruction. Such simplification significantly limits their capacity, as a single demo-free instruction might not be able to cover the entire complex problem space of the targeted task. To alleviate this issue, we adopt the Mixture-of-Expert paradigm and divide the problem space into a set of sub-regions; Each sub-region is governed by a specialized expert, equipped with both an instruction and a set of demos. A two-phase process is developed to construct the specialized expert for each region: (1) demo assignment: Inspired by the theoretical connection between in-context learning and kernel regression, we group demos into experts based on their semantic similarity; (2) instruction assignment: A region-based joint search of an instruction per expert complements the demos assigned to it, yielding a synergistic effect. The resulting method, codenamed Mixture-of-Prompts (MoP), achieves an average win rate of 81% against prior arts across several major benchmarks.