ShortcutsBench: A Large-Scale Real-world Benchmark for API-based Agents
作者: Haiyang Shen, Yue Li, Desong Meng, Dongqi Cai, Sheng Qi, Li Zhang, Mengwei Xu, Yun Ma
分类: cs.SE, cs.AI
发布日期: 2024-06-28 (更新: 2025-01-23)
备注: ICLR'25: https://openreview.net/forum?id=kKILfPkhSz
🔗 代码/项目: GITHUB
💡 一句话要点
提出ShortcutsBench以评估API代理在复杂任务中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: API代理 大型语言模型 基准评估 复杂任务 真实世界应用
📋 核心要点
- 现有的API代理在处理复杂查询时面临显著的局限性,尤其是在API选择、参数填充和用户输入请求方面。
- 本文提出了ShortcutsBench,一个大规模基准,旨在全面评估API代理在解决复杂任务中的能力,涵盖真实API和高质量标注数据。
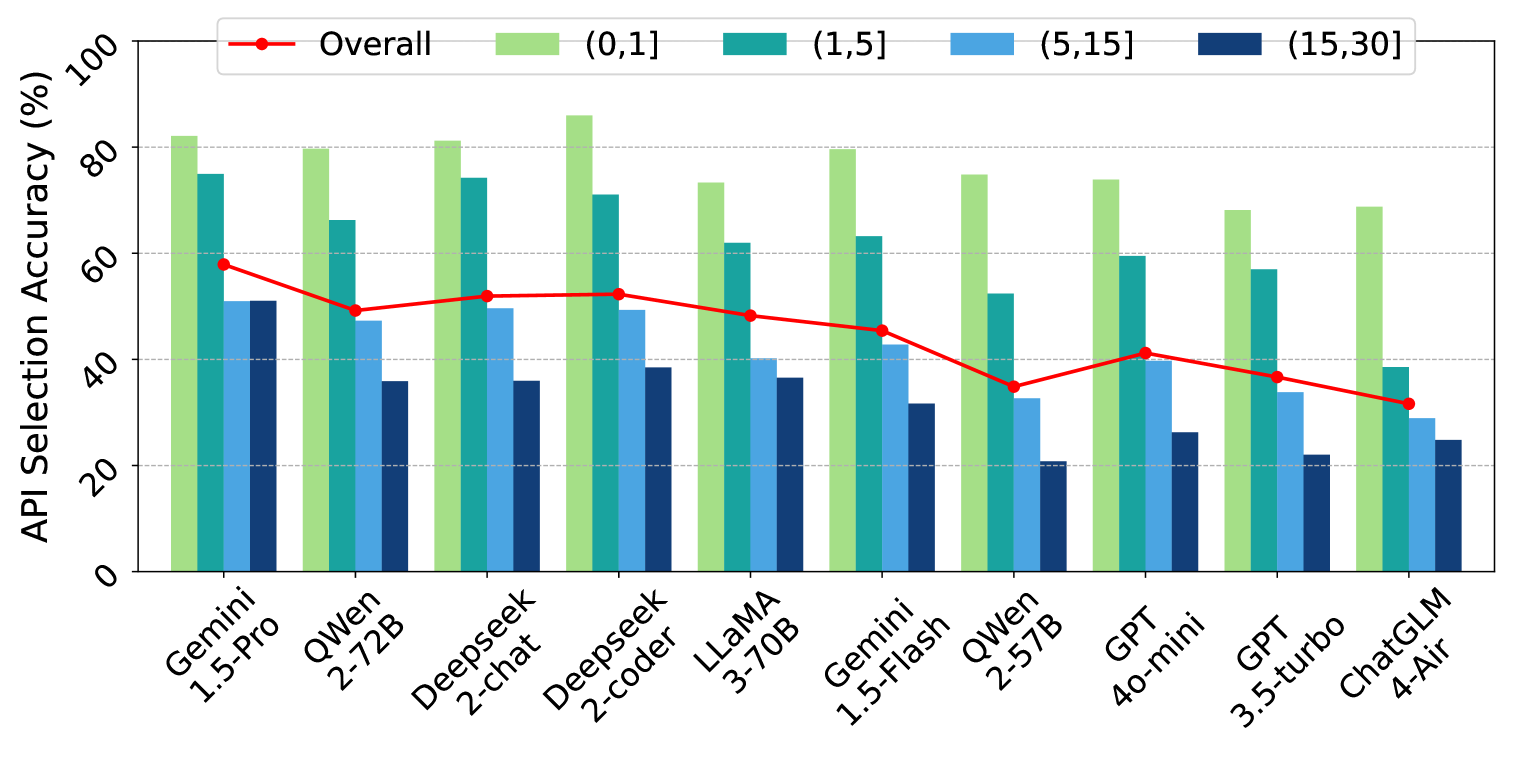
- 通过对5个开源和5个闭源LLMs的广泛评估,揭示了现有API代理在处理复杂用户查询时的挑战和不足。
📝 摘要(中文)
近年来,将大型语言模型(LLMs)与应用程序编程接口(APIs)结合的进展引起了学术界和工业界的广泛关注。尽管已有研究表明这些API代理在自主性和规划能力方面表现良好,但它们在处理多维难度、任务类型和现实需求方面的能力仍不明确。本文介绍了ShortcutsBench,这是一个大规模基准,用于全面评估API代理在解决现实复杂任务中的表现。ShortcutsBench包含来自苹果公司的真实API、精炼的用户查询、高质量的人工标注动作序列、详细的参数填充值以及请求系统或用户必要输入的参数。我们的评估显示,现有基准在适应更智能的LLMs的高级推理能力方面存在困难,并揭示了现有API代理在处理复杂查询时的显著局限性。
🔬 方法详解
问题定义:本文旨在解决API代理在处理复杂任务时的局限性,尤其是在多维度难度和多样化任务类型方面的不足。现有方法未能有效评估这些代理的推理能力和实际应用性能。
核心思路:论文提出ShortcutsBench作为一个全面的基准,结合真实API和高质量的用户查询,以评估API代理在复杂任务中的表现。通过提供详细的参数和用户输入请求,增强了评估的真实性和有效性。
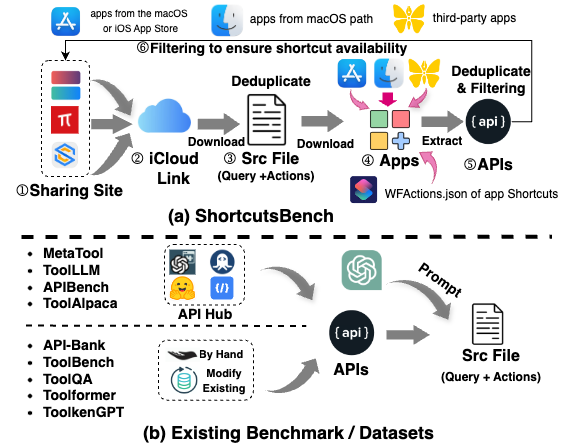
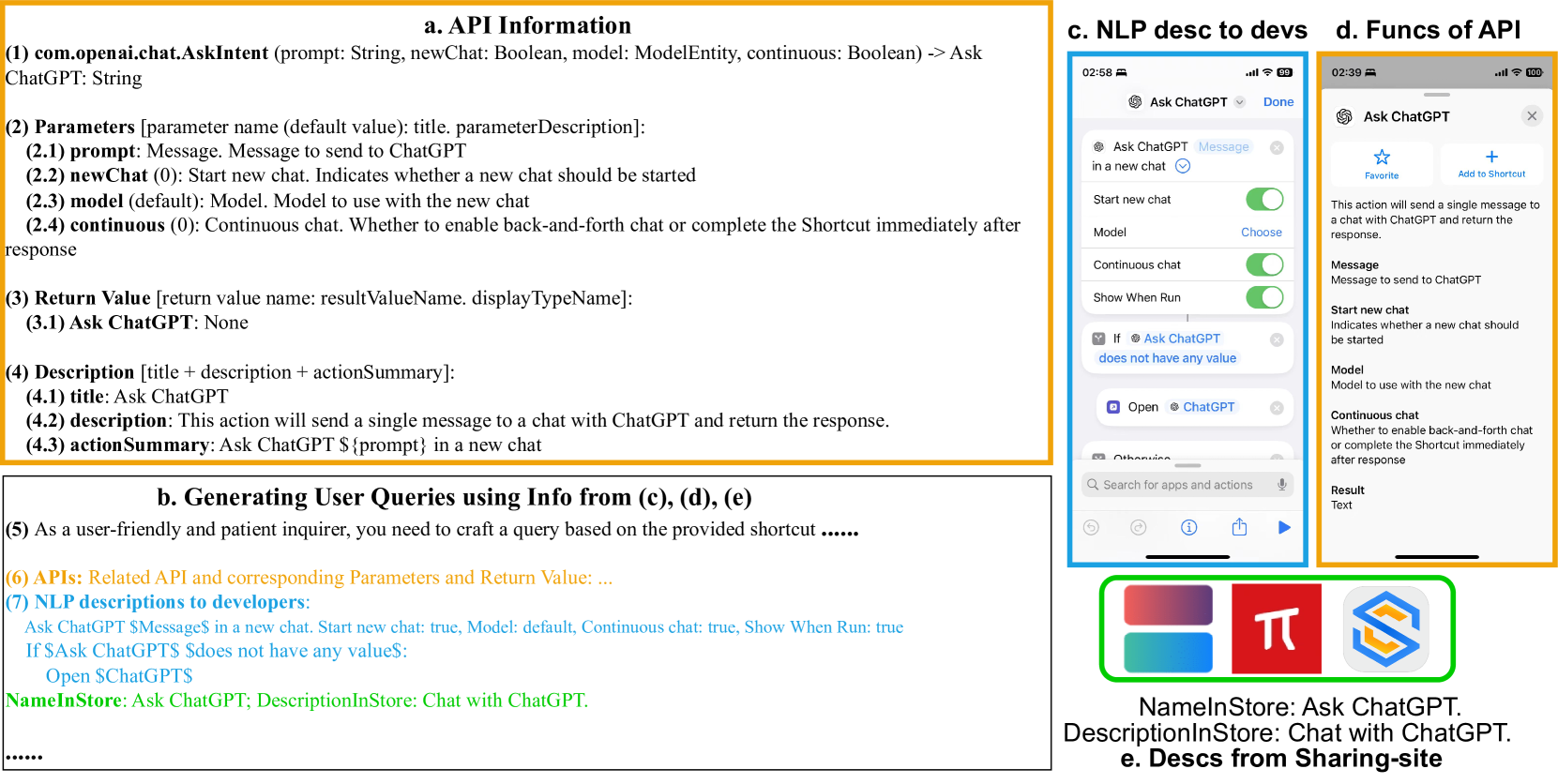
技术框架:ShortcutsBench的整体架构包括真实API的整合、用户查询的精炼、人工标注的动作序列以及详细的参数设置。评估流程涵盖了API选择、参数填充和用户输入请求的各个阶段。
关键创新:最重要的创新在于提供了一个真实世界的基准,能够有效评估API代理在复杂任务中的表现,填补了现有基准在推理能力评估方面的空白。
关键设计:在设计中,重点关注了参数的详细设置和用户输入的请求机制,确保评估的全面性和准确性。通过与5个开源和5个闭源LLMs的比较,揭示了API代理在处理复杂查询时的局限性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,现有API代理在处理复杂查询时存在显著局限性,尤其是在API选择和参数填充方面。与基线模型相比,评估的LLMs在处理复杂任务时的表现提升幅度明显,揭示了API代理在实际应用中的挑战。
🎯 应用场景
ShortcutsBench的研究成果可广泛应用于智能助手、自动化客服和其他需要API交互的智能系统中。通过提升API代理的能力,能够更好地满足用户在复杂任务中的需求,具有重要的实际价值和未来影响。
📄 摘要(原文)
Recent advancements in integrating large language models (LLMs) with application programming interfaces (APIs) have gained significant interest in both academia and industry. Recent work demonstrates that these API-based agents exhibit relatively strong autonomy and planning capabilities. However, their ability to handle multi-dimensional difficulty levels, diverse task types, and real-world demands remains unknown. In this paper, we introduce \textsc{ShortcutsBench}, a large-scale benchmark for the comprehensive evaluation of API-based agents in solving real-world complex tasks. \textsc{ShortcutsBench} includes a wealth of real APIs from Apple Inc., refined user queries, human-annotated high-quality action sequences, detailed parameter filling values, and parameters requesting necessary input from the system or user. We revealed how existing benchmarks~/~datasets struggle to accommodate the advanced reasoning capabilities of existing more intelligent LLMs. Moreover, our extensive evaluation of agents built with $5$ leading open-source (size $\geq$ 57B) and $5$ closed-source LLMs (e.g. Gemini-1.5-Pro and GPT-4o-mini) with varying intelligence level reveals significant limitations of existing API-based agents in the whole process of handling complex queries related to API selection, parameter filling, and requesting necessary input from the system and the user. These findings highlight the great challenges that API-based agents face in effectively fulfilling real and complex user queries. All datasets, code, experimental logs, and results are available at \url{https://github.com/EachSheep/ShortcutsBench}.