Optimizing Cyber Defense in Dynamic Active Directories through Reinforcement Learning
作者: Diksha Goel, Kristen Moore, Mingyu Guo, Derui Wang, Minjune Kim, Seyit Camtepe
分类: cs.CR, cs.AI, cs.LG
发布日期: 2024-06-28
备注: The manuscript has been accepted as full paper at European Symposium on Research in Computer Security (ESORICS) 2024
💡 一句话要点
提出基于强化学习的动态Active Directory网络防御优化方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 网络安全 Active Directory 攻防博弈 自主网络防御 Stackelberg博弈 动态网络 边缘阻断
📋 核心要点
- 现有边缘阻断防御研究忽略了Active Directory(AD)系统的动态性,导致防御策略在实际环境中效果不佳。
- 论文提出基于强化学习的攻防博弈模型,利用Stackelberg博弈框架,通过并行博弈迭代优化攻防策略。
- 通过RL训练促进器,修剪不相关的环境和神经网络,显著提升了大规模动态AD图上的训练效率和可扩展性。
📝 摘要(中文)
本文旨在解决自主网络防御(ACO)文献中存在的不足,即在动态、真实网络中缺乏有效的边缘阻断ACO策略。研究聚焦于组织Active Directory(AD)系统的网络安全漏洞。与现有将AD系统视为静态实体的边缘阻断防御文献不同,本研究认识到AD系统的动态性,并通过攻击者和防御者之间的Stackelberg博弈模型开发先进的边缘阻断防御。我们设计了一种基于强化学习(RL)的攻击策略和一种基于RL辅助的进化多样性优化防御策略,攻击者和防御者通过并行博弈来改进彼此的策略。为了解决在大量动态AD图上训练攻防策略的计算挑战,我们提出了一种RL训练促进器,它可以修剪环境和神经网络以消除不相关的元素,从而为大型图实现高效且可扩展的训练。我们广泛地训练了攻击者策略,因为一个复杂的攻击者模型对于强大的防御至关重要。我们的实验结果成功地证明了我们提出的方法提高了防御者在加强动态AD图方面的能力,同时确保了大规模AD的可扩展性。
🔬 方法详解
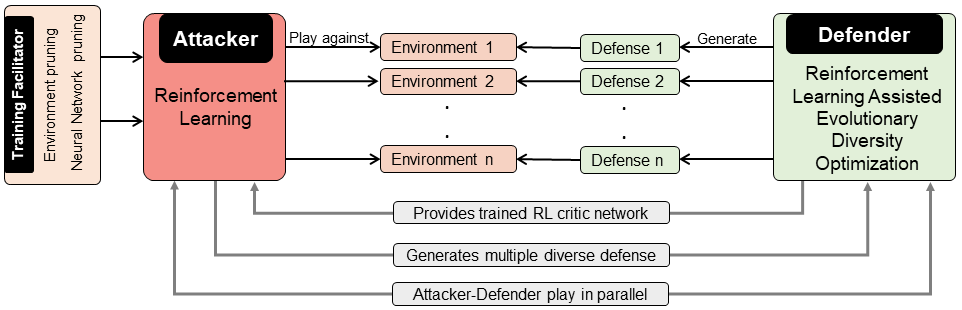
问题定义:现有针对Active Directory (AD) 系统的边缘阻断防御方法通常将AD系统视为静态实体,忽略了其动态性。这导致防御策略在面对真实世界中不断变化的AD环境时,效果大打折扣。此外,在大规模AD图上训练攻防策略面临着巨大的计算挑战。
核心思路:论文的核心思路是将AD系统的攻防过程建模为一个Stackelberg博弈,其中攻击者和防御者通过强化学习不断学习和优化各自的策略。通过并行博弈的方式,攻击者和防御者相互促进,从而提升整体的防御能力。同时,为了解决计算挑战,论文提出了RL训练促进器,用于降低训练的复杂性。
技术框架:整体框架包含三个主要模块:基于强化学习的攻击策略、基于RL辅助的进化多样性优化防御策略和RL训练促进器。攻击策略和防御策略通过Stackelberg博弈进行交互,不断学习和优化。RL训练促进器则负责对训练环境和神经网络进行剪枝,以提高训练效率和可扩展性。
关键创新:论文的关键创新在于:1) 将动态AD系统的攻防过程建模为Stackelberg博弈,更贴近真实场景;2) 提出RL训练促进器,解决了大规模AD图上的训练难题。与现有方法相比,该方法能够更好地适应动态AD环境,并具有更好的可扩展性。
关键设计:在攻击策略和防御策略的设计中,使用了强化学习算法(具体算法类型未知)。RL训练促进器通过剪枝技术,移除对攻防策略影响较小的环境元素和神经网络连接,从而降低计算复杂度。具体的剪枝策略和参数设置未知。损失函数的设计目标是最大化攻击者的收益和最小化防御者的损失。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的方法能够有效提高防御者在动态AD图上的防御能力,并确保大规模AD的可扩展性。具体的性能数据和对比基线未知,但论文强调该方法能够显著提升防御者的防御水平。
🎯 应用场景
该研究成果可应用于企业和组织的网络安全防御体系中,尤其是在Active Directory环境下的安全加固。通过自动化的攻防演练,可以有效提升防御者应对真实攻击的能力,降低安全风险。此外,该方法还可以扩展到其他类型的动态网络安全防御场景中。
📄 摘要(原文)
This paper addresses a significant gap in Autonomous Cyber Operations (ACO) literature: the absence of effective edge-blocking ACO strategies in dynamic, real-world networks. It specifically targets the cybersecurity vulnerabilities of organizational Active Directory (AD) systems. Unlike the existing literature on edge-blocking defenses which considers AD systems as static entities, our study counters this by recognizing their dynamic nature and developing advanced edge-blocking defenses through a Stackelberg game model between attacker and defender. We devise a Reinforcement Learning (RL)-based attack strategy and an RL-assisted Evolutionary Diversity Optimization-based defense strategy, where the attacker and defender improve each other strategy via parallel gameplay. To address the computational challenges of training attacker-defender strategies on numerous dynamic AD graphs, we propose an RL Training Facilitator that prunes environments and neural networks to eliminate irrelevant elements, enabling efficient and scalable training for large graphs. We extensively train the attacker strategy, as a sophisticated attacker model is essential for a robust defense. Our empirical results successfully demonstrate that our proposed approach enhances defender's proficiency in hardening dynamic AD graphs while ensuring scalability for large-scale AD.