Knowledge acquisition for dialogue agents using reinforcement learning on graph representations
作者: Selene Baez Santamaria, Shihan Wang, Piek Vossen
分类: cs.AI, cs.CL
发布日期: 2024-06-27
💡 一句话要点
提出基于强化学习和知识图谱的对话Agent知识获取方法,无需人工反馈。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对话Agent 知识获取 强化学习 知识图谱 RDF 图模式 智能客服
📋 核心要点
- 现有对话Agent知识获取依赖人工标注或预定义规则,泛化能力有限。
- 提出基于强化学习的Agent,通过对话主动学习并整合新知识到RDF知识图谱中。
- 实验证明,该Agent能够通过强化学习选择有效图模式,无需人工反馈即可有效获取知识。
📝 摘要(中文)
本文提出了一种人工智能Agent,旨在扩展其初始训练之外的知识库。该Agent主动参与与其他Agent的对话,策略性地获取新信息。Agent将其知识建模为RDF知识图谱,整合通过对话获得的新信念。对话中的回复通过识别围绕这些新整合信念的图模式来生成。研究表明,可以使用强化学习来学习在交互过程中选择有效的图模式的策略,而无需依赖显式的用户反馈。本文的研究是在此背景下,将用户作为有效信息来源的概念验证。
🔬 方法详解
问题定义:现有对话Agent的知识库通常是静态的,难以适应不断变化的世界知识。传统的知识获取方法依赖于人工标注或预定义的规则,成本高昂且难以泛化。因此,如何让Agent能够主动地、高效地从对话中获取新知识是一个重要的挑战。
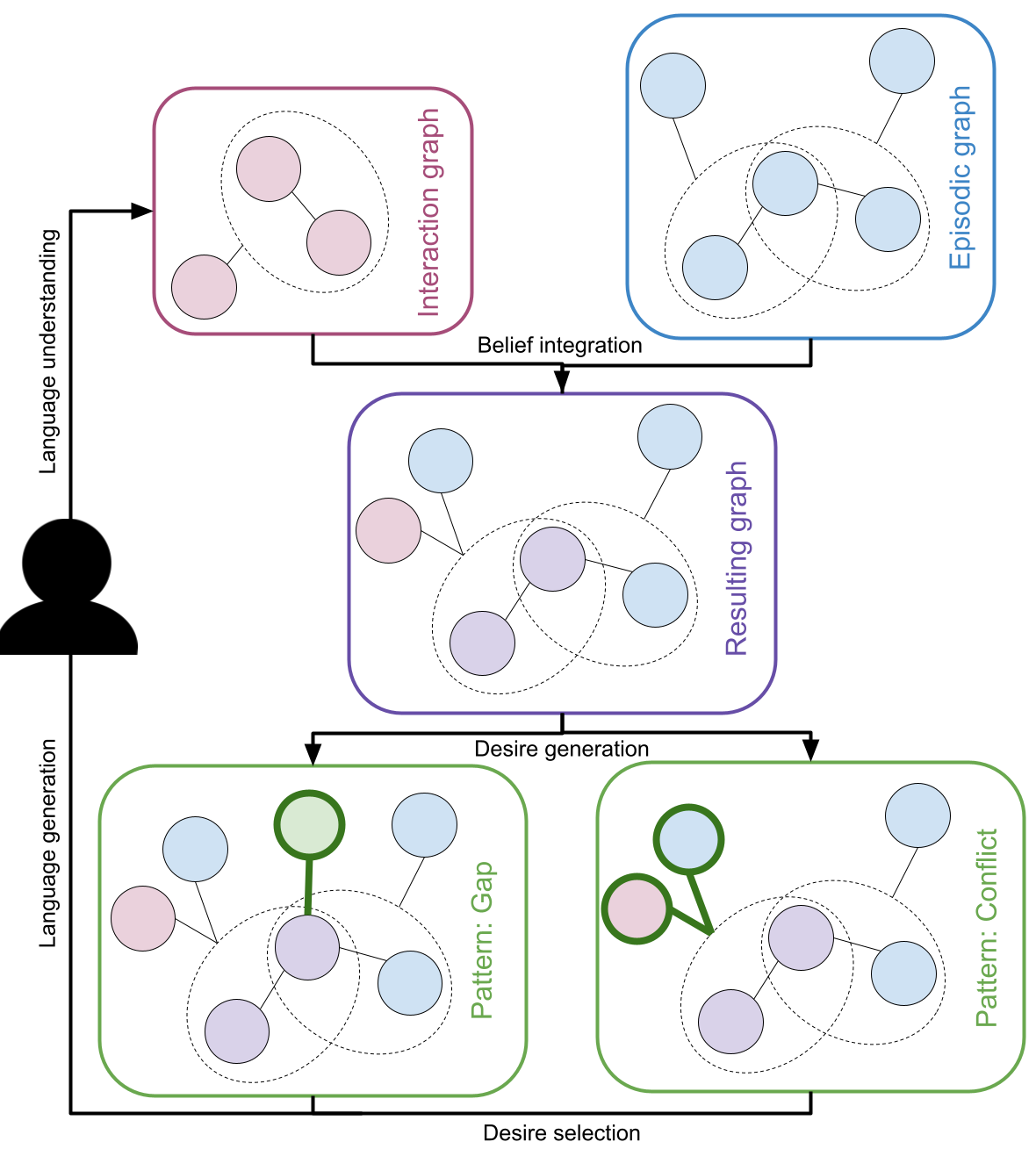
核心思路:本文的核心思路是利用强化学习训练一个Agent,使其能够通过与其他Agent的对话,主动探索和获取新的知识。Agent将知识表示为RDF知识图谱,并将从对话中获取的新信息整合到该图谱中。通过强化学习,Agent学习选择合适的图模式来生成对话回复,从而有效地获取和利用新知识。
技术框架:该Agent的整体框架包括以下几个主要模块:1) 知识图谱构建模块:用于将初始知识表示为RDF知识图谱。2) 对话交互模块:负责与其他Agent进行对话,接收和发送信息。3) 知识整合模块:将从对话中获取的新信息整合到知识图谱中。4) 回复生成模块:基于知识图谱中的图模式生成对话回复。5) 强化学习模块:使用强化学习算法训练Agent,使其能够选择有效的图模式来生成回复。
关键创新:该方法最重要的创新点在于使用强化学习来训练Agent,使其能够自主地从对话中获取知识,而无需依赖人工反馈。此外,使用图模式来表示和生成对话回复,能够更好地利用知识图谱中的结构化信息。
关键设计:Agent使用Q-learning算法进行训练,状态空间定义为当前对话状态和知识图谱中的相关实体,动作空间定义为可选择的图模式。奖励函数的设计旨在鼓励Agent选择能够获取新知识的图模式。具体来说,如果Agent选择的图模式能够导致知识图谱的更新,则给予正向奖励;否则,给予负向奖励。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该Agent能够通过强化学习有效地学习选择图模式的策略,从而在对话中获取新知识。与没有强化学习的基线方法相比,该Agent能够显著提高知识获取的效率和准确性。更重要的是,该方法无需人工反馈,降低了知识获取的成本。
🎯 应用场景
该研究成果可应用于智能客服、聊天机器人等领域,提升Agent的知识获取能力和对话质量。通过主动学习和知识整合,Agent能够更好地理解用户意图,提供更准确、更个性化的服务。未来,该方法有望应用于更复杂的知识密集型任务,例如智能问答、知识推理等。
📄 摘要(原文)
We develop an artificial agent motivated to augment its knowledge base beyond its initial training. The agent actively participates in dialogues with other agents, strategically acquiring new information. The agent models its knowledge as an RDF knowledge graph, integrating new beliefs acquired through conversation. Responses in dialogue are generated by identifying graph patterns around these new integrated beliefs. We show that policies can be learned using reinforcement learning to select effective graph patterns during an interaction, without relying on explicit user feedback. Within this context, our study is a proof of concept for leveraging users as effective sources of information.