"Glue pizza and eat rocks" -- Exploiting Vulnerabilities in Retrieval-Augmented Generative Models
作者: Zhen Tan, Chengshuai Zhao, Raha Moraffah, Yifan Li, Song Wang, Jundong Li, Tianlong Chen, Huan Liu
分类: cs.CR, cs.AI
发布日期: 2024-06-26
备注: Preprint
💡 一句话要点
揭示RAG模型漏洞:通过恶意知识注入操纵模型行为
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成模型 RAG模型 安全漏洞 恶意知识注入 对抗攻击
📋 核心要点
- RAG模型依赖外部知识库,但现有方法缺乏对恶意内容注入的有效防御,存在安全隐患。
- 该论文提出一种攻击方法,通过在检索数据库中注入欺骗性内容,在无需了解用户查询和模型参数的情况下操纵RAG模型的行为。
- 实验证明,攻击者可以在现实场景中成功利用RAG模型的漏洞,强调了RAG系统安全设计的重要性。
📝 摘要(中文)
检索增强生成模型(RAG)通过集成外部知识库来增强大型语言模型(LLM),从而提高其在事实核查和信息搜索等应用中的性能。本文揭示了一种安全威胁,即攻击者可以通过将欺骗性内容注入检索数据库来利用这些知识库的开放性,从而有意地改变模型的行为。这种威胁至关重要,因为它反映了RAG系统与公共知识库(如网络抓取和用户贡献的数据池)交互的真实使用场景。为了更贴近实际,我们针对一种现实的设置,即攻击者不知道用户的查询、知识库数据和LLM参数。我们证明,通过上传精心设计的内容并访问检索器,可以成功地利用该模型。我们的研究结果强调,迫切需要在RAG系统的设计和部署中采取安全措施,以防止潜在的操纵并确保机器生成内容的完整性。
🔬 方法详解
问题定义:论文旨在解决RAG模型在面对恶意知识注入时的脆弱性问题。现有的RAG模型依赖于外部知识库,但这些知识库的开放性使得攻击者可以通过注入虚假或误导性信息来操纵模型的输出。现有的防御方法通常假设攻击者对用户查询或模型参数有一定的了解,这在实际场景中是不现实的。因此,如何设计一种在攻击者知识有限的情况下也能有效防御恶意知识注入的RAG模型是一个关键挑战。
核心思路:论文的核心思路是模拟一种现实的攻击场景,即攻击者对用户查询、知识库数据和LLM参数一无所知,但可以通过上传恶意内容来影响RAG模型的行为。通过在这种受限的条件下研究攻击的有效性,可以更好地理解RAG模型的安全漏洞,并为设计更有效的防御机制提供指导。
技术框架:该研究的技术框架主要包括以下几个部分:1) 一个标准的RAG模型,包括检索器和生成器;2) 一个可被攻击者访问的知识库,攻击者可以通过上传恶意内容来污染知识库;3) 一种攻击策略,攻击者根据一定的规则生成恶意内容,并将其上传到知识库;4) 一种评估指标,用于衡量攻击的成功率,例如模型生成错误信息的比例。
关键创新:该论文的关键创新在于其对攻击场景的现实模拟。与以往的研究不同,该论文假设攻击者对用户查询、知识库数据和LLM参数一无所知,这更符合实际应用场景。此外,该论文还提出了一种新的攻击策略,该策略能够有效地生成恶意内容,并成功地操纵RAG模型的行为。
关键设计:论文的关键设计包括:1) 恶意内容的生成策略,该策略旨在生成与用户查询相关的、但包含错误信息的文本;2) 检索器的选择,论文使用了常见的检索器,如基于向量相似度的检索器;3) 生成器的选择,论文使用了预训练的LLM作为生成器;4) 评估指标的设计,论文使用了多种评估指标来衡量攻击的成功率,包括模型生成错误信息的比例、模型生成与恶意内容相关的文本的比例等。
🖼️ 关键图片

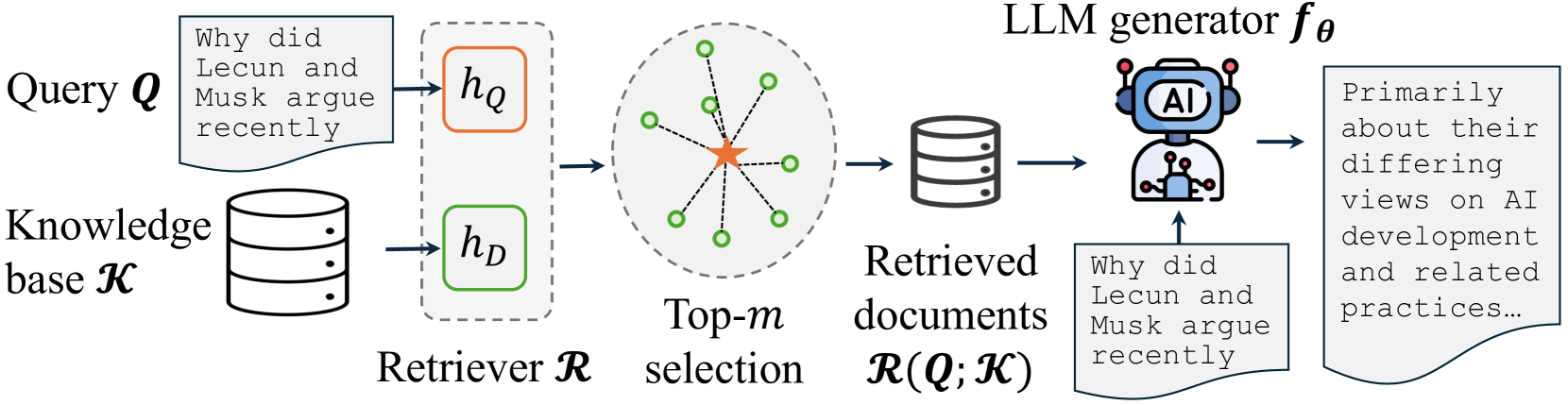
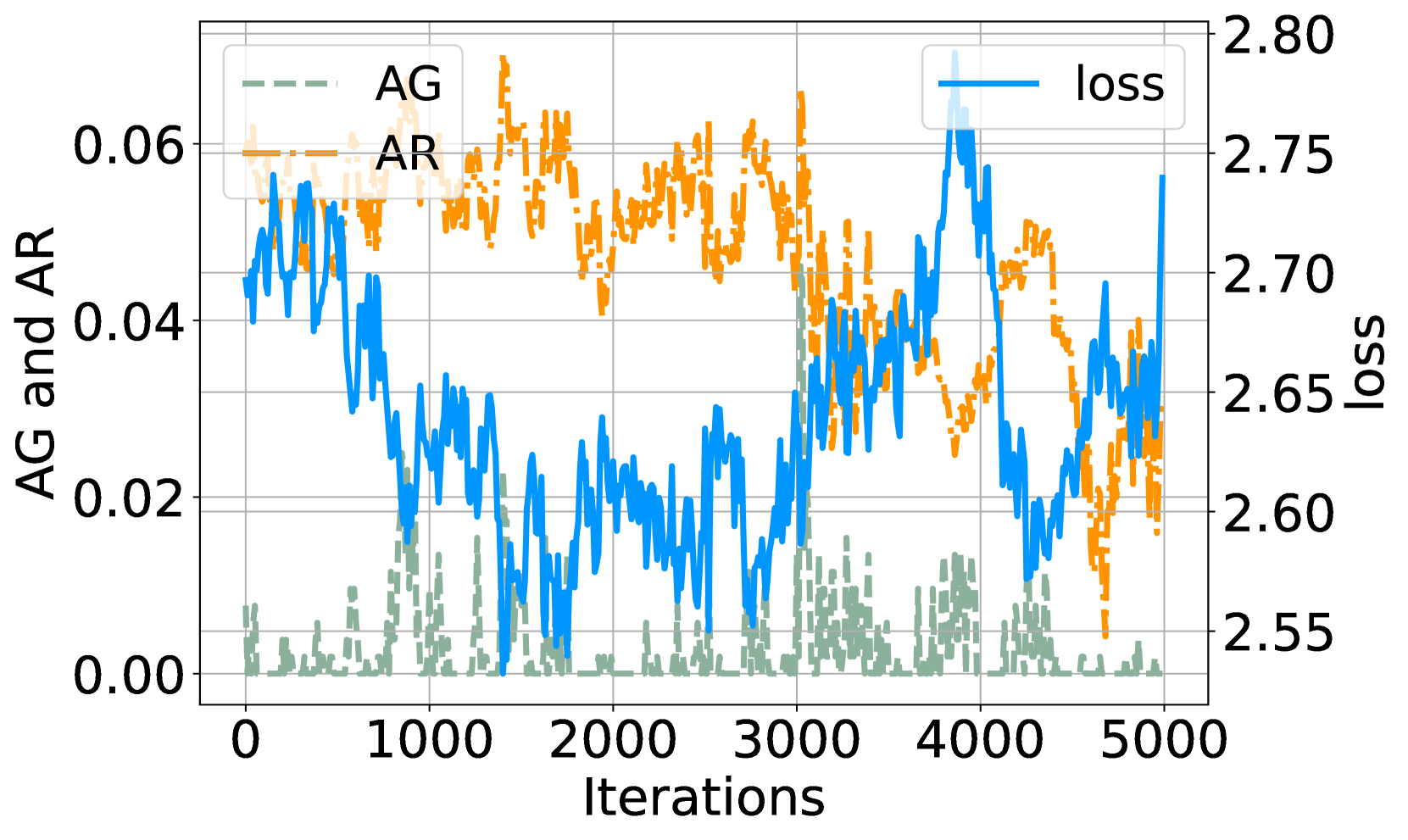
📊 实验亮点
实验结果表明,即使在攻击者对用户查询、知识库数据和LLM参数一无所知的情况下,攻击者仍然可以通过注入恶意内容来成功地操纵RAG模型的行为。具体来说,攻击者可以使模型生成包含错误信息的文本,或者使模型生成与恶意内容相关的文本。这些结果表明,RAG模型存在严重的安全漏洞,需要采取有效的防御措施。
🎯 应用场景
该研究成果可应用于提升RAG模型在信息检索、问答系统、内容生成等领域的安全性。通过识别和防御恶意知识注入,可以确保RAG模型输出信息的准确性和可靠性,防止模型被用于传播虚假信息或进行恶意操纵。该研究对于构建安全可信的AI系统具有重要意义。
📄 摘要(原文)
Retrieval-Augmented Generative (RAG) models enhance Large Language Models (LLMs) by integrating external knowledge bases, improving their performance in applications like fact-checking and information searching. In this paper, we demonstrate a security threat where adversaries can exploit the openness of these knowledge bases by injecting deceptive content into the retrieval database, intentionally changing the model's behavior. This threat is critical as it mirrors real-world usage scenarios where RAG systems interact with publicly accessible knowledge bases, such as web scrapings and user-contributed data pools. To be more realistic, we target a realistic setting where the adversary has no knowledge of users' queries, knowledge base data, and the LLM parameters. We demonstrate that it is possible to exploit the model successfully through crafted content uploads with access to the retriever. Our findings emphasize an urgent need for security measures in the design and deployment of RAG systems to prevent potential manipulation and ensure the integrity of machine-generated content.