Human-Object Interaction from Human-Level Instructions
作者: Zhen Wu, Jiaman Li, Pei Xu, C. Karen Liu
分类: cs.AI, cs.CV
发布日期: 2024-06-25 (更新: 2025-08-21)
备注: ICCV 2025, project page: https://hoifhli.github.io/
💡 一句话要点
提出一种基于人类指令的物理可信人-物交互生成系统
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人-物交互 大型语言模型 强化学习 物理模拟 运动生成
📋 核心要点
- 现有方法难以根据人类指令生成逼真且物理可信的人-物交互,尤其是在手指级别的精细操作上。
- 该论文利用大型语言模型解析人类指令,生成详细的执行计划,并结合强化学习保证运动的物理合理性。
- 实验表明,该系统能够合成与各种物体进行逼真交互,验证了其在复杂环境中生成人-物交互的有效性。
📝 摘要(中文)
本文提出了一种完整的系统,用于合成物理上合理的、长时程的人-物交互,以在上下文环境中进行物体操作,并由人类指令驱动。该系统利用大型语言模型(LLMs)将输入指令解释为详细的执行计划。与以往工作不同,该系统能够生成详细的手指-物体交互,并与全身运动无缝协调。此外,还训练了一个策略,通过强化学习(RL)在物理模拟中跟踪生成的运动,以确保运动的物理合理性。实验结果表明,该系统在复杂环境中合成与各种物体进行逼真交互方面非常有效,突出了其在实际应用中的潜力。
🔬 方法详解
问题定义:现有方法在根据人类指令生成人-物交互时,难以兼顾运动的物理合理性和手指级别的精细操作。尤其是在长时程的交互中,误差会逐渐累积,导致生成的动作不自然甚至违反物理定律。此外,如何将高级指令转化为具体的动作序列也是一个挑战。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的强大语义理解能力,将人类指令转化为详细的执行计划。然后,通过强化学习(RL)训练一个策略,使其能够跟踪这些计划,并在物理模拟环境中生成物理可信的动作。通过结合LLM的规划能力和RL的控制能力,实现高质量的人-物交互生成。
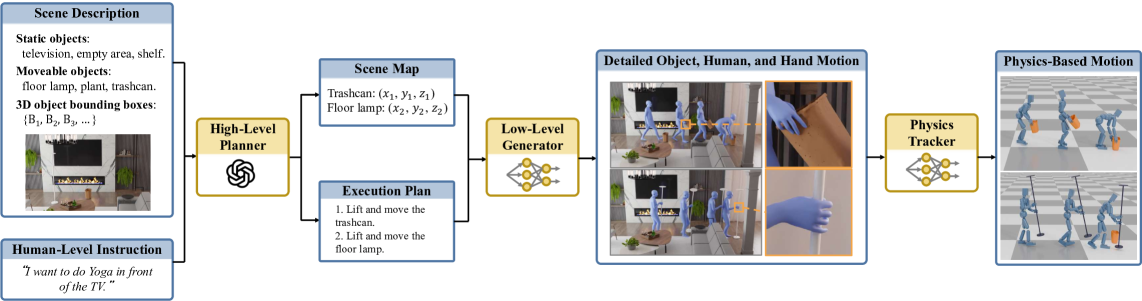
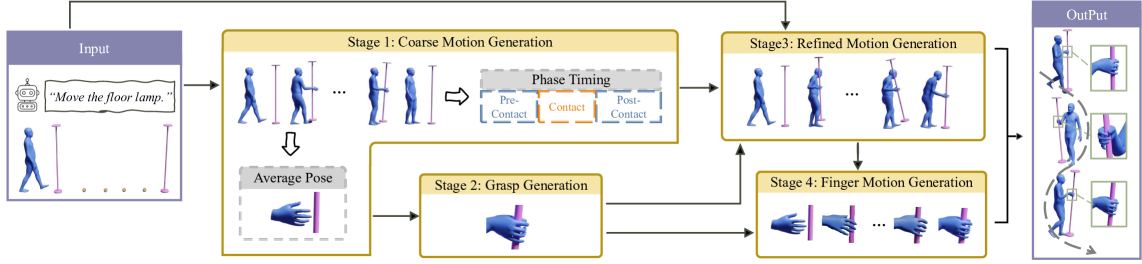
技术框架:该系统主要包含两个阶段:指令解析和运动生成。首先,利用LLM将人类指令解析为一系列的中间步骤,例如“拿起杯子”、“倒水”等。然后,使用一个基于强化学习的控制器,根据这些中间步骤生成具体的动作序列,包括全身运动和手指操作。该控制器在物理模拟环境中进行训练,以确保生成的动作具有物理合理性。
关键创新:该论文的关键创新在于将LLM和RL相结合,实现从人类指令到物理可信的人-物交互的端到端生成。与以往工作相比,该系统能够生成更长时程、更精细的交互,并且能够更好地处理复杂环境中的物体操作。此外,该系统还能够生成手指级别的交互,这在以往的工作中很少涉及。
关键设计:在指令解析阶段,论文使用了预训练的LLM,并对其进行了微调,以更好地适应人-物交互的任务。在运动生成阶段,论文使用了基于Actor-Critic的强化学习算法,并设计了一个奖励函数,鼓励智能体生成物理合理且符合指令的动作。此外,论文还使用了运动学逆解(IK)技术,将全身运动和手指操作进行协调。
🖼️ 关键图片
📊 实验亮点
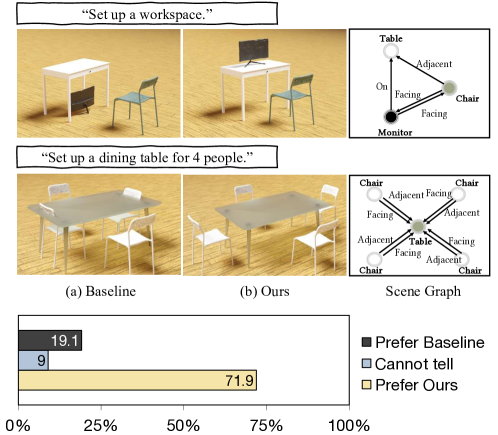
实验结果表明,该系统能够生成逼真且物理可信的人-物交互,包括全身运动和手指操作。与现有的方法相比,该系统能够更好地处理复杂环境中的物体操作,并且能够生成更长时程的交互。通过定性和定量的评估,验证了该系统在人-物交互生成方面的有效性。
🎯 应用场景
该研究成果可应用于机器人控制、虚拟现实、游戏开发等领域。例如,可以利用该系统生成机器人在复杂环境中执行任务的动作,或者生成虚拟角色与物体交互的动画。此外,该系统还可以用于训练机器人,使其能够更好地理解人类指令并执行相应的动作。
📄 摘要(原文)
Intelligent agents must autonomously interact with the environments to perform daily tasks based on human-level instructions. They need a foundational understanding of the world to accurately interpret these instructions, along with precise low-level movement and interaction skills to execute the derived actions. In this work, we propose the first complete system for synthesizing physically plausible, long-horizon human-object interactions for object manipulation in contextual environments, driven by human-level instructions. We leverage large language models (LLMs) to interpret the input instructions into detailed execution plans. Unlike prior work, our system is capable of generating detailed finger-object interactions, in seamless coordination with full-body movements. We also train a policy to track generated motions in physics simulation via reinforcement learning (RL) to ensure physical plausibility of the motion. Our experiments demonstrate the effectiveness of our system in synthesizing realistic interactions with diverse objects in complex environments, highlighting its potential for real-world applications.