KnobTree: Intelligent Database Parameter Configuration via Explainable Reinforcement Learning
作者: Jiahan Chen, Shuhan Qi, Yifan Li, Zeyu Dong, Mingfeng Ding, Yulin Wu, Xuan Wang
分类: cs.AI, cs.DB
发布日期: 2024-06-21
💡 一句话要点
KnobTree:基于可解释强化学习的智能数据库参数配置
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据库参数调优 强化学习 可解释性 Shapley值 差分树
📋 核心要点
- 现有数据库参数配置方法难以应对实际应用中大量可调参数带来的复杂性,且基于强化学习的调优策略缺乏可解释性。
- KnobTree框架通过构建基于差分树的透明模型,生成可解释的数据库调优策略,并利用Shapley值评估参数重要性。
- 实验表明,KnobTree模型具有卓越的透明性和可解释性,且在吞吐量、延迟和处理时间等方面优于现有基于RL的调优算法。
📝 摘要(中文)
数据库是现代信息系统的基础,但传统的基于规则的配置方法难以管理具有数百个可调参数的实际应用的复杂性。深度强化学习(DRL)结合了感知和决策能力,为智能数据库配置调优提供了一种潜在的解决方案。然而,由于基于RL的方法的黑盒特性,生成的数据库调优策略仍然面临缺乏可解释性的紧迫问题。此外,大规模数据库中的冗余参数总是使策略学习变得不稳定。本文提出了KnobTree,一个为优化数据库参数配置而设计的可解释框架。在该框架中,提出了一种基于RL的差分树的可解释数据库调优算法,该算法构建了一个透明的基于树的模型来生成可解释的数据库调优策略。为了解决大规模参数的问题,我们还引入了一种可解释的参数重要性评估方法,通过利用Shapley值来识别对数据库性能有显著影响的参数。在MySQL和Gbase8s数据库上进行的实验验证了KnobTree模型的卓越透明性和可解释性。良好的特性使得生成的策略能够为算法设计者和数据库管理员提供实际指导。此外,我们的方法在吞吐量、延迟和处理时间等方面也略优于现有的基于RL的调优算法。
🔬 方法详解
问题定义:论文旨在解决数据库参数配置的自动化和可解释性问题。现有基于规则的方法难以应对复杂应用,而基于强化学习的方法虽然有效,但其黑盒特性使得调优策略难以理解和信任。此外,大规模参数空间也增加了学习的难度和不稳定性。
核心思路:论文的核心思路是利用可解释的强化学习方法,构建一个透明的树模型来生成数据库调优策略。通过引入差分树结构,使得策略的生成过程更加清晰可控。同时,利用Shapley值评估参数的重要性,从而降低参数空间的维度,提高学习效率。
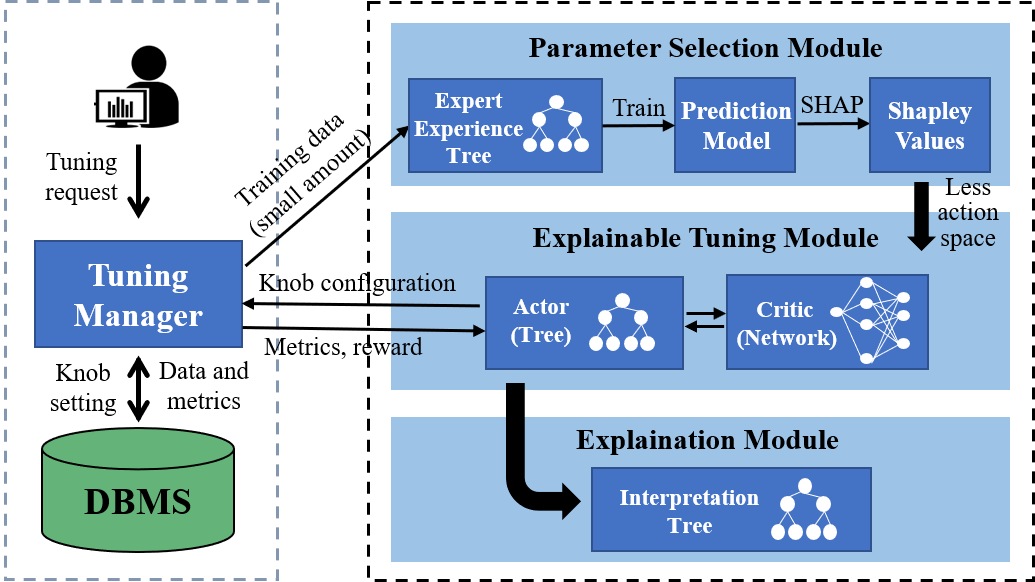
技术框架:KnobTree框架主要包含两个阶段:参数重要性评估和策略学习。首先,利用Shapley值评估每个参数对数据库性能的影响,筛选出重要参数。然后,基于这些重要参数,构建一个基于差分树的强化学习模型,用于生成数据库调优策略。该模型通过与数据库环境交互,不断优化策略,最终达到提升数据库性能的目的。
关键创新:最重要的技术创新点在于将可解释的差分树结构引入到强化学习中,从而使得生成的数据库调优策略具有良好的可解释性。与传统的黑盒强化学习方法相比,KnobTree能够提供策略背后的决策依据,增强了用户对策略的信任感。此外,利用Shapley值进行参数重要性评估,有效地降低了参数空间的维度,提高了学习效率。
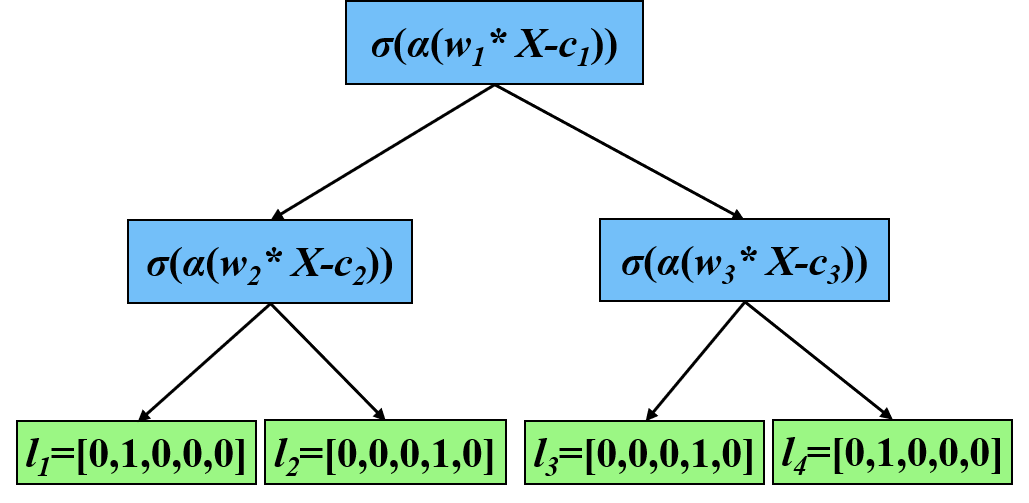
关键设计:差分树的结构设计是关键。每个节点代表一个参数,每个分支代表一个参数的取值范围。通过遍历树的路径,可以得到一个完整的参数配置。强化学习算法用于学习每个节点的最优分支选择策略。Shapley值的计算方法也需要仔细设计,以保证评估结果的准确性和可靠性。损失函数的设计需要综合考虑数据库的性能指标,如吞吐量、延迟等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,KnobTree在MySQL和Gbase8s数据库上都取得了良好的性能。与现有的基于RL的调优算法相比,KnobTree在吞吐量、延迟和处理时间等方面均有小幅提升。更重要的是,KnobTree生成了可解释的调优策略,为用户提供了决策依据,增强了用户对策略的信任感。例如,实验表明,某些参数对数据库性能的影响远大于其他参数,这为数据库管理员提供了优化方向。
🎯 应用场景
KnobTree可应用于各种类型的数据库系统,例如关系型数据库(MySQL、PostgreSQL)和NoSQL数据库。它可以帮助数据库管理员自动优化数据库参数配置,提高数据库性能,降低运维成本。此外,KnobTree生成的可解释策略可以为数据库设计者提供有价值的反馈,帮助他们更好地理解数据库的运行机制。
📄 摘要(原文)
Databases are fundamental to contemporary information systems, yet traditional rule-based configuration methods struggle to manage the complexity of real-world applications with hundreds of tunable parameters. Deep reinforcement learning (DRL), which combines perception and decision-making, presents a potential solution for intelligent database configuration tuning. However, due to black-box property of RL-based method, the generated database tuning strategies still face the urgent problem of lack explainability. Besides, the redundant parameters in large scale database always make the strategy learning become unstable. This paper proposes KnobTree, an interpertable framework designed for the optimization of database parameter configuration. In this framework, an interpertable database tuning algorithm based on RL-based differentatial tree is proposed, which building a transparent tree-based model to generate explainable database tuning strategies. To address the problem of large-scale parameters, We also introduce a explainable method for parameter importance assessment, by utilizing Shapley Values to identify parameters that have significant impacts on database performance. Experiments conducted on MySQL and Gbase8s databases have verified exceptional transparency and interpretability of the KnobTree model. The good property makes generated strategies can offer practical guidance to algorithm designers and database administrators. Moreover, our approach also slightly outperforms the existing RL-based tuning algorithms in aspects such as throughput, latency, and processing time.