Does GPT Really Get It? A Hierarchical Scale to Quantify Human vs AI's Understanding of Algorithms
作者: Mirabel Reid, Santosh S. Vempala
分类: cs.AI
发布日期: 2024-06-20 (更新: 2025-01-18)
备注: 13 pages, 10 figures. To be published at AAAI 2025
💡 一句话要点
提出算法理解层次结构,量化评估人类与GPT对算法的理解程度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 算法理解 层次结构 认知评估 人工智能
📋 核心要点
- 现有对LLM理解能力的研究不足,缺乏对哲学、心理学和教育领域相关研究的借鉴。
- 论文提出算法理解的层次结构,用于量化评估人类和LLM对算法的理解程度。
- 通过对人类和GPT进行实验,揭示了两者在算法理解方面的相似之处和差异。
📝 摘要(中文)
随着大型语言模型(LLMs)在日益复杂的认知任务中表现出色,一个自然的问题是AI是否真正理解。对LLM理解能力的研究尚处于起步阶段,并且尚未充分借鉴哲学、心理学和教育领域的成熟研究。本文旨在填补这一空白,特别关注对算法的理解,并提出一个理解层次结构。我们利用该层次结构设计并进行了一项研究,研究对象包括人类(本科生和研究生)以及大型语言模型(GPT的多个版本),揭示了有趣的相似之处和差异。我们期望我们严格的标准将有助于跟踪AI在此类认知领域中的进展。
🔬 方法详解
问题定义:论文旨在解决如何量化评估大型语言模型(LLMs)对算法的理解程度的问题。现有方法缺乏一个明确的、分层次的评估框架,无法有效区分不同层次的理解能力。这使得我们难以判断LLM是否真正“理解”算法,还是仅仅在进行模式匹配和表面操作。
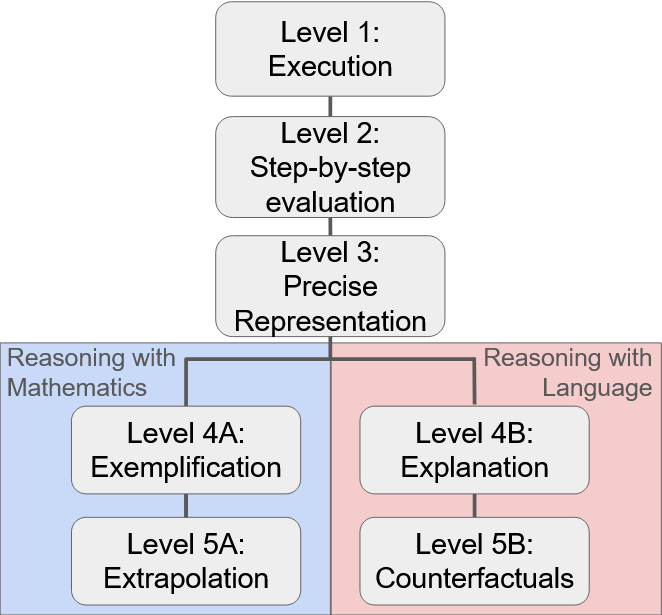
核心思路:论文的核心思路是借鉴认知科学和教育学中的理解理论,构建一个算法理解的层次结构。该层次结构将算法理解分解为多个不同的层次,每个层次代表不同深度的理解。通过评估LLM在每个层次上的表现,可以更全面、细致地了解其算法理解能力。
技术框架:论文的技术框架主要包括以下几个步骤:1) 定义算法理解的层次结构;2) 基于该层次结构设计评估任务;3) 招募人类受试者(本科生和研究生)并使用LLM(GPT的多个版本)完成评估任务;4) 分析人类和LLM在不同层次上的表现,比较它们的理解能力。
关键创新:论文的关键创新在于提出了一个算法理解的层次结构,并将其应用于评估LLM的理解能力。该层次结构提供了一个系统化的框架,可以更准确地量化LLM对算法的理解程度。与现有方法相比,该方法更加细致、全面,能够揭示LLM在算法理解方面的优势和不足。
关键设计:论文的关键设计包括:1) 算法理解层次结构的具体划分(具体层次划分未知);2) 评估任务的设计,需要确保任务能够有效区分不同层次的理解能力;3) 实验数据的分析方法,需要能够准确地量化人类和LLM在不同层次上的表现。
🖼️ 关键图片

📊 实验亮点
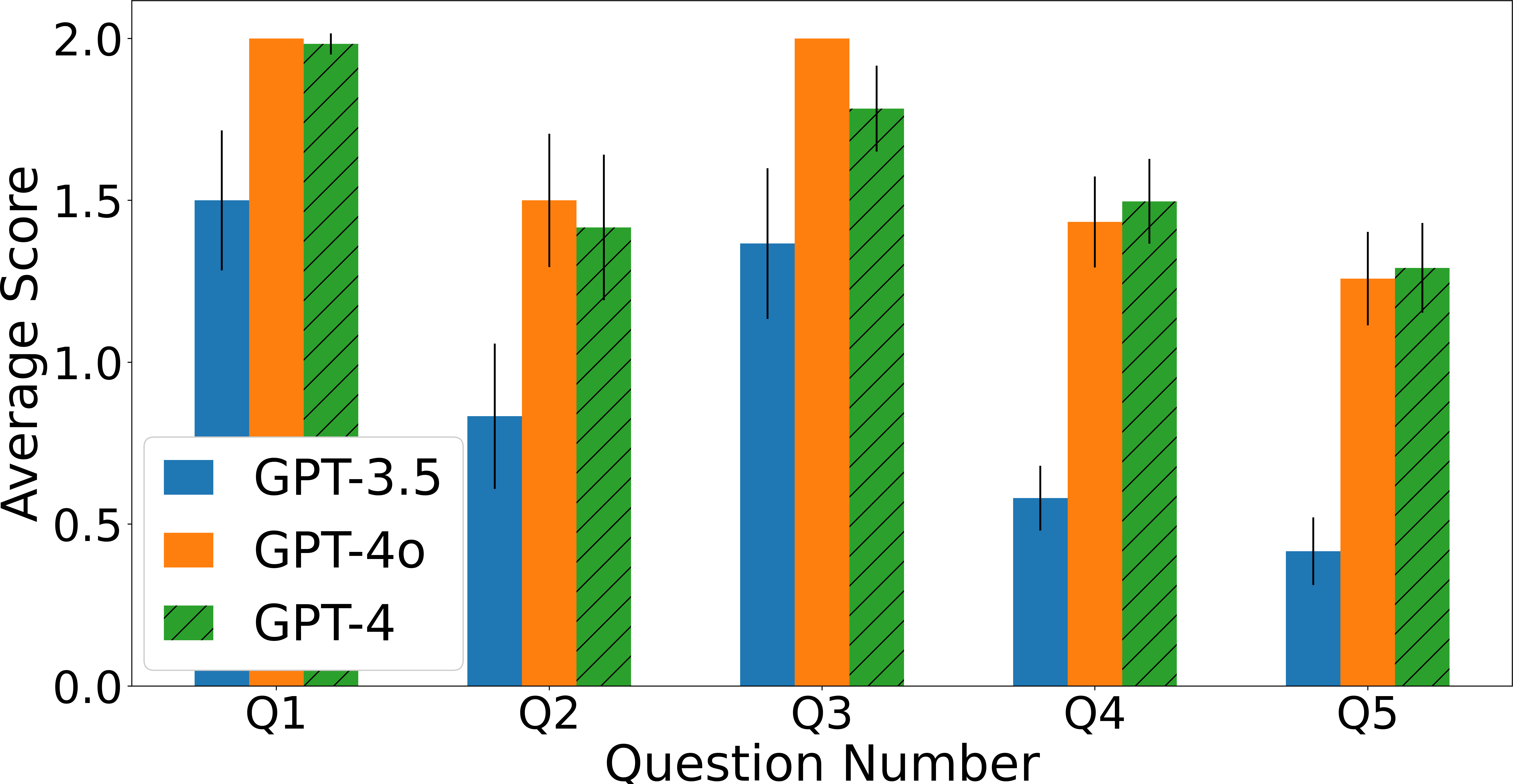
论文通过对人类和GPT进行实验,揭示了两者在算法理解方面的相似之处和差异。具体的性能数据、对比基线和提升幅度未知,但该研究为量化评估LLM的算法理解能力提供了一个新的视角和方法。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的算法理解能力,从而提高其在软件开发、数据分析等领域的应用效果。此外,该研究提出的算法理解层次结构也可用于教育领域,帮助学生更好地理解算法。
📄 摘要(原文)
As Large Language Models (LLMs) perform (and sometimes excel at) more and more complex cognitive tasks, a natural question is whether AI really understands. The study of understanding in LLMs is in its infancy, and the community has yet to incorporate well-trodden research in philosophy, psychology, and education. We initiate this, specifically focusing on understanding algorithms, and propose a hierarchy of levels of understanding. We use the hierarchy to design and conduct a study with human subjects (undergraduate and graduate students) as well as large language models (generations of GPT), revealing interesting similarities and differences. We expect that our rigorous criteria will be useful to keep track of AI's progress in such cognitive domains.