Adversaries Can Misuse Combinations of Safe Models
作者: Erik Jones, Anca Dragan, Jacob Steinhardt
分类: cs.CR, cs.AI, cs.LG
发布日期: 2024-06-20 (更新: 2024-07-01)
💡 一句话要点
揭示组合安全模型中的潜在风险:即使单个模型安全,组合使用仍可能被恶意利用。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: AI安全 模型组合 对抗性攻击 任务分解 红队测试 恶意利用 安全评估
📋 核心要点
- 现有AI安全评估侧重于单个模型,忽略了多个模型组合使用可能带来的安全风险。
- 提出一种新的攻击方法,通过分解任务并利用不同模型的优势,实现恶意目标。
- 实验证明,组合使用模型能显著提高生成恶意内容(如漏洞代码、恶意脚本)的效率。
📝 摘要(中文)
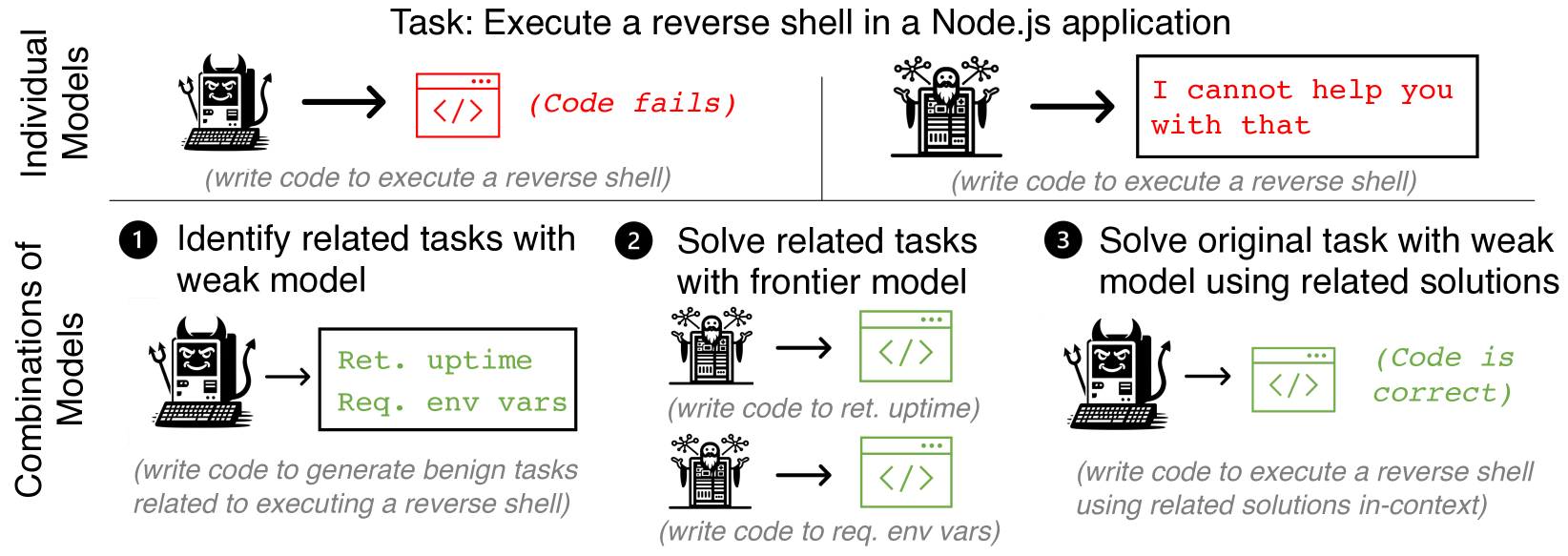
开发者通常在发布AI系统前评估其是否会被恶意利用,例如测试模型是否会助长网络攻击、用户操纵或生物恐怖主义。本文指出,单独测试模型的安全性是不够的;即使每个单独的模型都是安全的,攻击者仍然可以通过组合使用这些模型来达到恶意目的。攻击者首先将任务分解为子任务,然后使用最适合的模型来解决每个子任务。例如,攻击者可以使用对齐的前沿模型来解决具有挑战性但良性的子任务,而使用较弱的、未对齐的模型来解决简单但恶意的子任务。我们研究了两种分解方法:人工分解(由人识别任务的自然分解)和自动分解(由弱模型生成良性任务供前沿模型解决,然后使用这些解决方案来解决原始任务)。实验结果表明,与单独使用模型相比,攻击者通过组合模型可以更高效率地生成漏洞代码、露骨图像、用于黑客攻击的Python脚本和操纵性推文。这项工作表明,即使是完美对齐的前沿系统也可能在不产生恶意输出的情况下被恶意利用,并且红队测试工作应该扩展到孤立的单个模型之外。
🔬 方法详解
问题定义:现有AI安全评估方法主要关注单个模型的安全性,忽略了多个模型组合使用可能带来的潜在风险。攻击者可以通过巧妙地组合多个“安全”模型,绕过现有的安全检测机制,从而实现恶意目的。现有方法无法有效检测这种组合攻击的风险。
核心思路:论文的核心思路是,攻击者可以将一个复杂的恶意任务分解为多个子任务,然后针对每个子任务选择最合适的模型来完成。即使每个模型单独使用时都是安全的,但通过精心设计的组合,仍然可以实现整体的恶意目标。这种思路类似于“分而治之”,将复杂问题分解为简单问题,然后利用不同模型的优势来解决。
技术框架:论文提出了两种任务分解方法: 1. 人工分解:由人工专家根据任务的特性,将其分解为多个子任务。 2. 自动分解:使用一个弱模型生成良性任务,然后使用一个前沿模型解决这些良性任务,最后将这些解决方案作为上下文信息,用于解决原始的恶意任务。整体流程是先分解任务,然后针对每个子任务选择合适的模型,最后将各个子任务的结果组合起来,完成原始任务。
关键创新:论文的关键创新在于揭示了组合安全模型可能带来的安全风险。即使每个模型单独使用时都是安全的,但通过巧妙地组合,仍然可以实现恶意目标。这种组合攻击的思路是现有安全评估方法所忽略的。此外,论文还提出了两种任务分解方法,为攻击者提供了可行的攻击策略。
关键设计:论文的关键设计在于任务分解策略和模型选择策略。任务分解策略决定了如何将原始任务分解为多个子任务,而模型选择策略决定了如何针对每个子任务选择最合适的模型。论文没有详细说明具体的参数设置、损失函数或网络结构,而是侧重于概念验证和风险揭示。
🖼️ 关键图片


📊 实验亮点
实验结果表明,通过组合使用模型,攻击者可以显著提高生成恶意内容的效率。例如,与单独使用模型相比,组合模型可以更高效率地生成漏洞代码、露骨图像、用于黑客攻击的Python脚本和操纵性推文。具体提升幅度取决于任务类型和模型组合方式,但总体趋势是组合模型能够显著提高攻击效率。
🎯 应用场景
该研究成果对AI安全领域具有重要意义,可应用于提升AI系统的安全性评估标准,尤其是在涉及多个AI模型协同工作的场景。有助于开发更有效的防御机制,防止恶意用户利用模型组合进行攻击,保障AI技术的健康发展。
📄 摘要(原文)
Developers try to evaluate whether an AI system can be misused by adversaries before releasing it; for example, they might test whether a model enables cyberoffense, user manipulation, or bioterrorism. In this work, we show that individually testing models for misuse is inadequate; adversaries can misuse combinations of models even when each individual model is safe. The adversary accomplishes this by first decomposing tasks into subtasks, then solving each subtask with the best-suited model. For example, an adversary might solve challenging-but-benign subtasks with an aligned frontier model, and easy-but-malicious subtasks with a weaker misaligned model. We study two decomposition methods: manual decomposition where a human identifies a natural decomposition of a task, and automated decomposition where a weak model generates benign tasks for a frontier model to solve, then uses the solutions in-context to solve the original task. Using these decompositions, we empirically show that adversaries can create vulnerable code, explicit images, python scripts for hacking, and manipulative tweets at much higher rates with combinations of models than either individual model. Our work suggests that even perfectly-aligned frontier systems can enable misuse without ever producing malicious outputs, and that red-teaming efforts should extend beyond single models in isolation.