Rewarding What Matters: Step-by-Step Reinforcement Learning for Task-Oriented Dialogue
作者: Huifang Du, Shuqin Li, Minghao Wu, Xuejing Feng, Yuan-Fang Li, Haofen Wang
分类: cs.AI
发布日期: 2024-06-20
💡 一句话要点
提出基于步进式奖励的强化学习方法,提升面向任务型对话系统的理解与生成能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 面向任务对话 对话状态跟踪 奖励机制 自然语言生成
📋 核心要点
- 现有强化学习方法在面向任务型对话系统中,侧重于对话生成而忽略了对话状态跟踪,限制了系统整体性能。
- 论文提出步进式奖励机制,在token生成过程中,同时对理解(DST)和生成(RG)任务进行奖励,实现平衡优化。
- 实验表明,该方法在MultiWOZ等数据集上取得了新的state-of-the-art结果,并在低资源场景下表现出更强的few-shot能力。
📝 摘要(中文)
强化学习(RL)是增强面向任务型对话(TOD)系统的有效方法。然而,现有的RL方法倾向于主要关注生成任务,如对话策略学习(DPL)或响应生成(RG),而忽略了用于理解的对话状态跟踪(DST)。这种狭隘的关注限制了系统通过忽视理解和生成之间的相互依赖性来实现全局最优性能。此外,RL方法面临着稀疏和延迟奖励的挑战,这使得训练和优化变得复杂。为了解决这些问题,我们通过在token生成过程中引入步进式奖励,将RL扩展到理解和生成任务。理解奖励随着DST中正确填充的槽位数量的增加而增加,而生成奖励随着用户请求的准确包含而增加。我们的方法提供了一种与任务完成相一致的平衡优化。实验结果表明,我们的方法有效地提高了TOD系统的性能,并在三个广泛使用的数据集(包括MultiWOZ2.0、MultiWOZ2.1和In-Car)上取得了新的state-of-the-art结果。与当前模型相比,我们的方法在低资源设置中也显示出卓越的few-shot能力。
🔬 方法详解
问题定义:现有面向任务型对话系统的强化学习方法主要关注对话策略学习和响应生成,忽略了对话状态跟踪的重要性。这种片面的优化方式无法充分利用理解和生成之间的相互依赖关系,导致系统难以达到全局最优。此外,强化学习中稀疏和延迟的奖励信号也增加了训练的难度。
核心思路:论文的核心思路是引入步进式奖励机制,将强化学习扩展到对话理解和对话生成两个任务中。通过在token生成过程中逐步给予奖励,鼓励模型在理解用户意图(DST)和生成合适回复(RG)两方面都做出正确的决策。这种细粒度的奖励方式能够更有效地指导模型的学习,克服稀疏奖励带来的挑战。
技术框架:整体框架包含对话状态跟踪(DST)模块和响应生成(RG)模块。在每个token生成步骤,DST模块预测当前对话状态,RG模块生成下一个token。关键在于,在每个步骤都会根据DST和RG的表现给予奖励。理解奖励与DST模块正确填充的槽位数量成正比,生成奖励与生成回复准确包含用户请求的程度相关。
关键创新:最关键的创新在于步进式奖励机制。与传统的只在对话结束时给予奖励的方式不同,该方法在每个token生成步骤都给予奖励,从而提供了更密集的反馈信号,加速了模型的学习过程。这种细粒度的奖励方式能够更好地捕捉理解和生成之间的相互依赖关系,实现更有效的优化。
关键设计:理解奖励的设计基于DST模块的槽位填充准确率,生成奖励的设计则需要考虑生成回复与用户请求之间的匹配程度。具体实现上,可以使用预训练语言模型作为DST和RG模块的基础,并根据任务需求进行微调。损失函数可以结合交叉熵损失和强化学习奖励,以平衡生成质量和任务完成度。奖励函数的具体形式需要根据数据集和任务特点进行调整。
🖼️ 关键图片


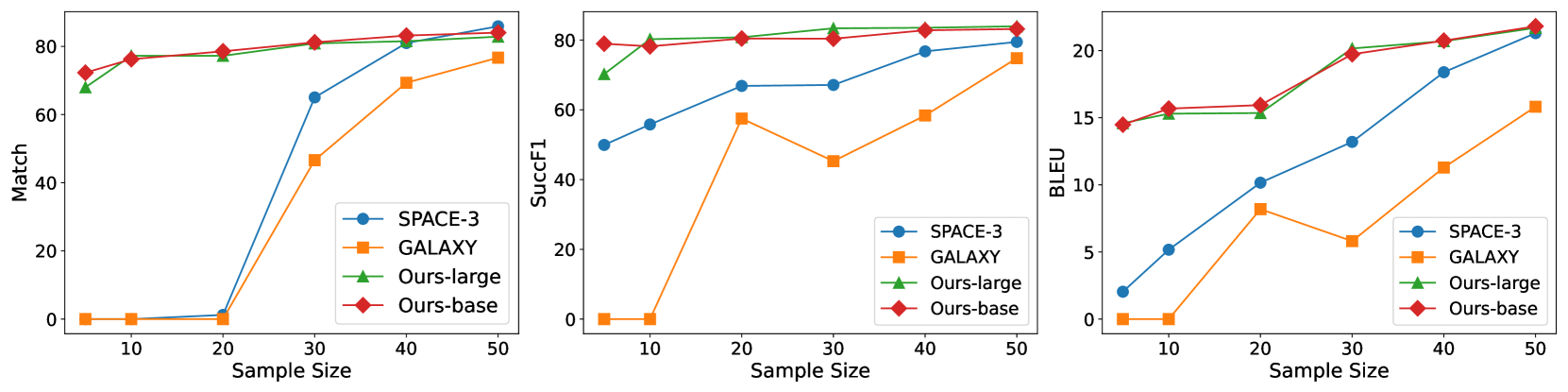
📊 实验亮点
实验结果表明,该方法在MultiWOZ2.0、MultiWOZ2.1和In-Car等多个数据集上取得了state-of-the-art的性能。与现有方法相比,该方法在任务完成率、对话轮数等方面均有显著提升。尤其值得一提的是,该方法在低资源场景下表现出更强的few-shot能力,表明其具有更好的泛化性能。
🎯 应用场景
该研究成果可应用于各种面向任务的对话系统,例如智能客服、语音助手等。通过提升对话系统的理解和生成能力,可以提高用户满意度,降低人工客服成本。该方法在低资源场景下的优势,使其在数据匮乏的领域也具有应用潜力。未来,可以进一步探索如何将该方法与其他技术(如知识图谱、迁移学习)相结合,以构建更智能、更可靠的对话系统。
📄 摘要(原文)
Reinforcement learning (RL) is a powerful approach to enhance task-oriented dialogue (TOD) systems. However, existing RL methods tend to mainly focus on generation tasks, such as dialogue policy learning (DPL) or response generation (RG), while neglecting dialogue state tracking (DST) for understanding. This narrow focus limits the systems to achieve globally optimal performance by overlooking the interdependence between understanding and generation. Additionally, RL methods face challenges with sparse and delayed rewards, which complicates training and optimization. To address these issues, we extend RL into both understanding and generation tasks by introducing step-by-step rewards throughout the token generation. The understanding reward increases as more slots are correctly filled in DST, while the generation reward grows with the accurate inclusion of user requests. Our approach provides a balanced optimization aligned with task completion. Experimental results demonstrate that our approach effectively enhances the performance of TOD systems and achieves new state-of-the-art results on three widely used datasets, including MultiWOZ2.0, MultiWOZ2.1, and In-Car. Our approach also shows superior few-shot ability in low-resource settings compared to current models.