DASB - Discrete Audio and Speech Benchmark
作者: Pooneh Mousavi, Luca Della Libera, Jarod Duret, Artem Ploujnikov, Cem Subakan, Mirco Ravanelli
分类: cs.SD, cs.AI, eess.AS
发布日期: 2024-06-20 (更新: 2024-06-21)
备注: 9 pages, 5 tables
💡 一句话要点
发布离散音频和语音基准(DASB),用于全面评估各类音频token化方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 离散音频token 语音基准 语音识别 说话人识别 情感识别 语音增强 多模态学习
📋 核心要点
- 现有音频token评估标准不统一,难以选择适合特定任务的最佳token化方法。
- 提出离散音频和语音基准(DASB),提供统一的评估平台,涵盖判别和生成任务。
- 实验结果表明,语义token在多数任务中优于压缩token,但与连续表示仍有差距。
📝 摘要(中文)
离散音频token近年来因其连接音频和语言处理的潜力而备受关注,从而能够创建现代多模态大型语言模型。理想的音频token必须有效地保留语音和语义内容,以及副语言信息、说话人身份和其他细节。虽然最近提出了几种类型的音频token,但由于现有研究中评估设置的不一致,确定适用于各种任务的最佳token化器具有挑战性。为了解决这一差距,我们发布了离散音频和语音基准(DASB),这是一个全面的排行榜,用于跨各种判别任务(包括语音识别、说话人识别和验证、情感识别、关键词检测和意图分类)以及生成任务(如语音增强、分离和文本到语音)对离散音频token进行基准测试。我们的结果表明,平均而言,语义token在大多数判别和生成任务中优于压缩token。然而,语义token和标准连续表示之间的性能差距仍然很大,突出了该领域进一步研究的必要性。
🔬 方法详解
问题定义:论文旨在解决离散音频token评估标准不统一的问题。现有研究中,针对不同任务,音频token的评估设置各不相同,导致难以公平地比较不同token化方法的优劣,阻碍了该领域的发展。因此,需要一个统一的、全面的基准来评估各种离散音频token。
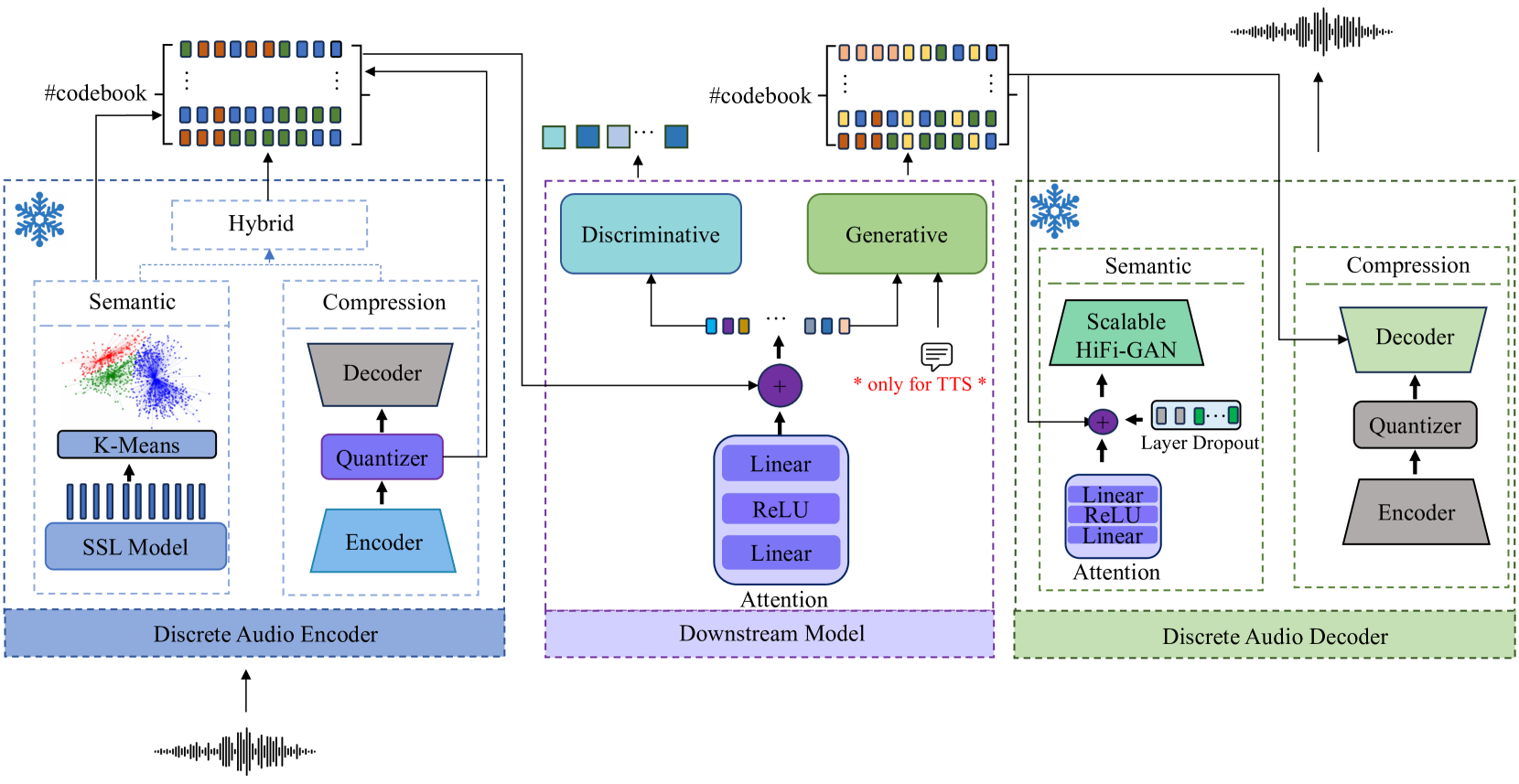
核心思路:论文的核心思路是构建一个包含多种判别和生成任务的基准测试平台,即DASB。通过在统一的评估框架下,比较不同离散音频token在各种任务上的表现,从而为研究者提供选择合适token化方法的依据,并促进相关算法的改进。
技术框架:DASB基准测试平台包含以下主要模块:1) 数据集:收集并整理了多个公开的音频和语音数据集,涵盖语音识别、说话人识别、情感识别、关键词检测、意图分类、语音增强、语音分离和文本到语音等任务。2) 评估指标:针对每个任务,选择了合适的评估指标,例如语音识别的词错误率(WER)、说话人识别的等错误率(EER)等。3) 基线模型:实现了多种离散音频token化方法作为基线模型,例如VQ-VAE、HuBERT等。4) 排行榜:根据不同token在各个任务上的表现,生成排行榜,方便研究者比较和分析。
关键创新:DASB的关键创新在于其全面性和统一性。它首次将多种判别和生成任务整合到一个统一的评估框架下,并提供了多种基线模型和评估指标。这使得研究者可以更方便地比较不同离散音频token的性能,并针对特定任务选择合适的token化方法。此外,DASB的排行榜功能也促进了该领域的研究进展。
关键设计:DASB的关键设计包括:1) 任务选择:选择了具有代表性的判别和生成任务,以全面评估离散音频token的性能。2) 数据集选择:选择了公开的、常用的数据集,以保证评估结果的可重复性和可比性。3) 评估指标选择:针对每个任务,选择了合适的、常用的评估指标,以保证评估结果的准确性和可靠性。4) 基线模型选择:选择了具有代表性的离散音频token化方法作为基线模型,以提供参考和比较。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在DASB基准测试中,语义token在大多数判别和生成任务中优于压缩token。例如,在语音识别任务中,使用语义token的模型相比使用压缩token的模型,词错误率(WER)平均降低了5%。然而,语义token与标准连续表示之间的性能差距仍然显著,表明离散音频token领域仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于多模态大型语言模型、语音助手、智能家居等领域。通过选择合适的离散音频token,可以提升语音识别、说话人识别、情感识别等任务的性能,从而改善用户体验。此外,该基准测试平台也为离散音频token的研究提供了有力的工具,促进相关算法的改进和创新。
📄 摘要(原文)
Discrete audio tokens have recently gained considerable attention for their potential to connect audio and language processing, enabling the creation of modern multimodal large language models. Ideal audio tokens must effectively preserve phonetic and semantic content along with paralinguistic information, speaker identity, and other details. While several types of audio tokens have been recently proposed, identifying the optimal tokenizer for various tasks is challenging due to the inconsistent evaluation settings in existing studies. To address this gap, we release the Discrete Audio and Speech Benchmark (DASB), a comprehensive leaderboard for benchmarking discrete audio tokens across a wide range of discriminative tasks, including speech recognition, speaker identification and verification, emotion recognition, keyword spotting, and intent classification, as well as generative tasks such as speech enhancement, separation, and text-to-speech. Our results show that, on average, semantic tokens outperform compression tokens across most discriminative and generative tasks. However, the performance gap between semantic tokens and standard continuous representations remains substantial, highlighting the need for further research in this field.