SeCoKD: Aligning Large Language Models for In-Context Learning with Fewer Shots
作者: Weixing Wang, Haojin Yang, Christoph Meinel
分类: cs.AI
发布日期: 2024-06-20 (更新: 2024-09-26)
备注: preprint
💡 一句话要点
提出SeCoKD框架,通过自知识蒸馏提升大语言模型少样本上下文学习能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文学习 知识蒸馏 少样本学习 自监督学习
📋 核心要点
- 大语言模型的上下文学习能力对演示示例非常敏感,通常需要大量示例。
- SeCoKD通过自知识蒸馏,利用大量提示变体对齐模型,提升单一样例利用率。
- 实验表明,SeCoKD在少样本学习中显著优于基线模型和监督微调,且泛化性更强。
📝 摘要(中文)
本文研究如何减少大语言模型(LLMs)上下文学习(ICL)所需的演示数量,同时保持竞争力的性能。为此,我们提出了SeCoKD,一个自知识蒸馏(KD)训练框架,它通过大量提示的变体来对齐学生模型,从而提高单个演示的利用率。我们在三个LLM和六个基准测试上对SeCoKD进行了实验,主要关注推理任务。结果表明,我们的方法优于基础模型和监督微调(SFT),尤其是在零样本和单样本设置中,分别提高了30%和10%。此外,SeCoKD在新任务上评估时几乎没有带来负面影响,比监督微调更稳健。
🔬 方法详解
问题定义:现有大语言模型的上下文学习能力依赖于大量的演示示例,这在实际应用中成本较高。如何减少所需的演示数量,同时保持甚至提升模型性能,是一个重要的研究问题。监督微调虽然可以提升性能,但容易过拟合到特定任务,泛化能力较差。
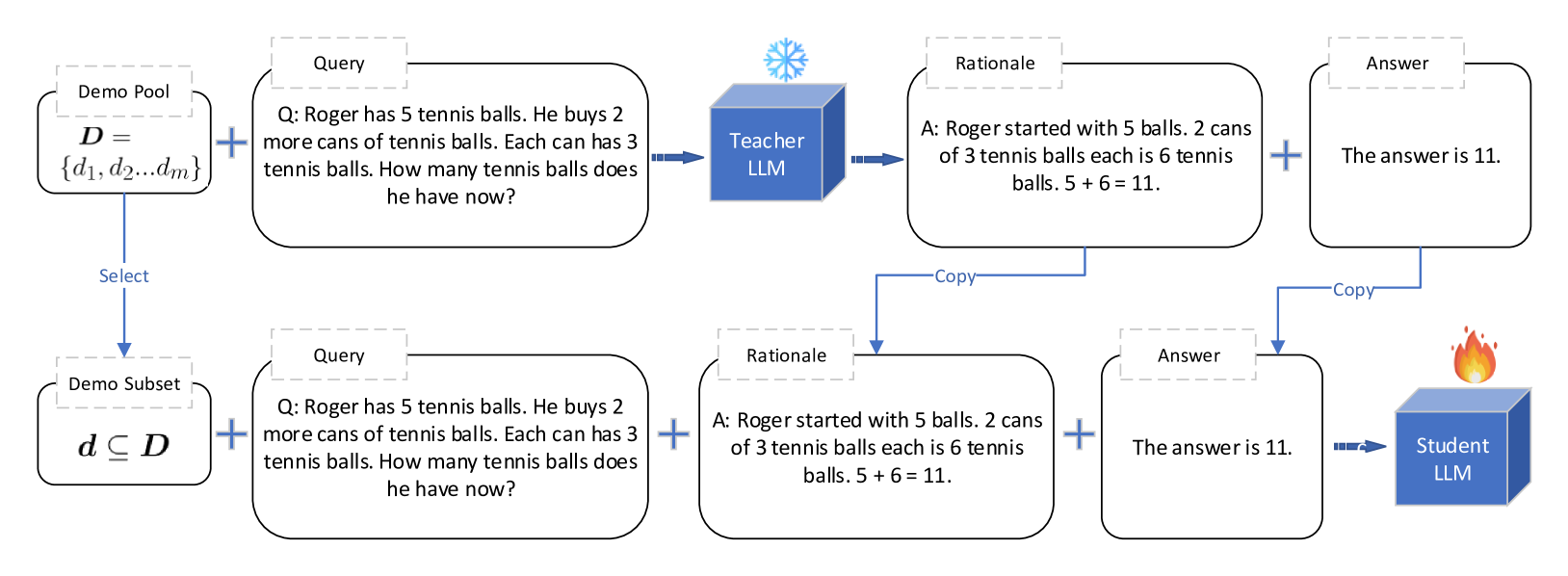
核心思路:SeCoKD的核心思路是利用知识蒸馏,将一个经过大量提示的“教师”模型的知识迁移到“学生”模型。通过这种方式,学生模型可以学习到更鲁棒的上下文学习能力,从而在少量演示示例下也能取得良好的性能。
技术框架:SeCoKD框架包含两个主要部分:教师模型和学生模型。教师模型是一个经过大量提示的预训练大语言模型,用于生成“软标签”。学生模型是需要训练的模型,通过最小化与教师模型输出的差异来学习知识。训练过程采用自知识蒸馏的方式,即学生模型同时作为教师模型的一部分,从而实现知识的循环利用。
关键创新:SeCoKD的关键创新在于利用自知识蒸馏来提升少样本上下文学习能力。与传统的监督微调相比,SeCoKD通过知识蒸馏的方式,避免了对特定任务的过拟合,从而提高了模型的泛化能力。此外,通过大量提示的教师模型,SeCoKD可以学习到更鲁棒的上下文学习模式。
关键设计:SeCoKD的关键设计包括:1) 使用多种提示策略生成教师模型的输出,以增加数据的多样性;2) 使用KL散度作为损失函数,衡量学生模型和教师模型输出之间的差异;3) 采用自知识蒸馏的方式,使得学生模型可以从自身的预测中学习,从而提高模型的稳定性和性能。
🖼️ 关键图片

📊 实验亮点
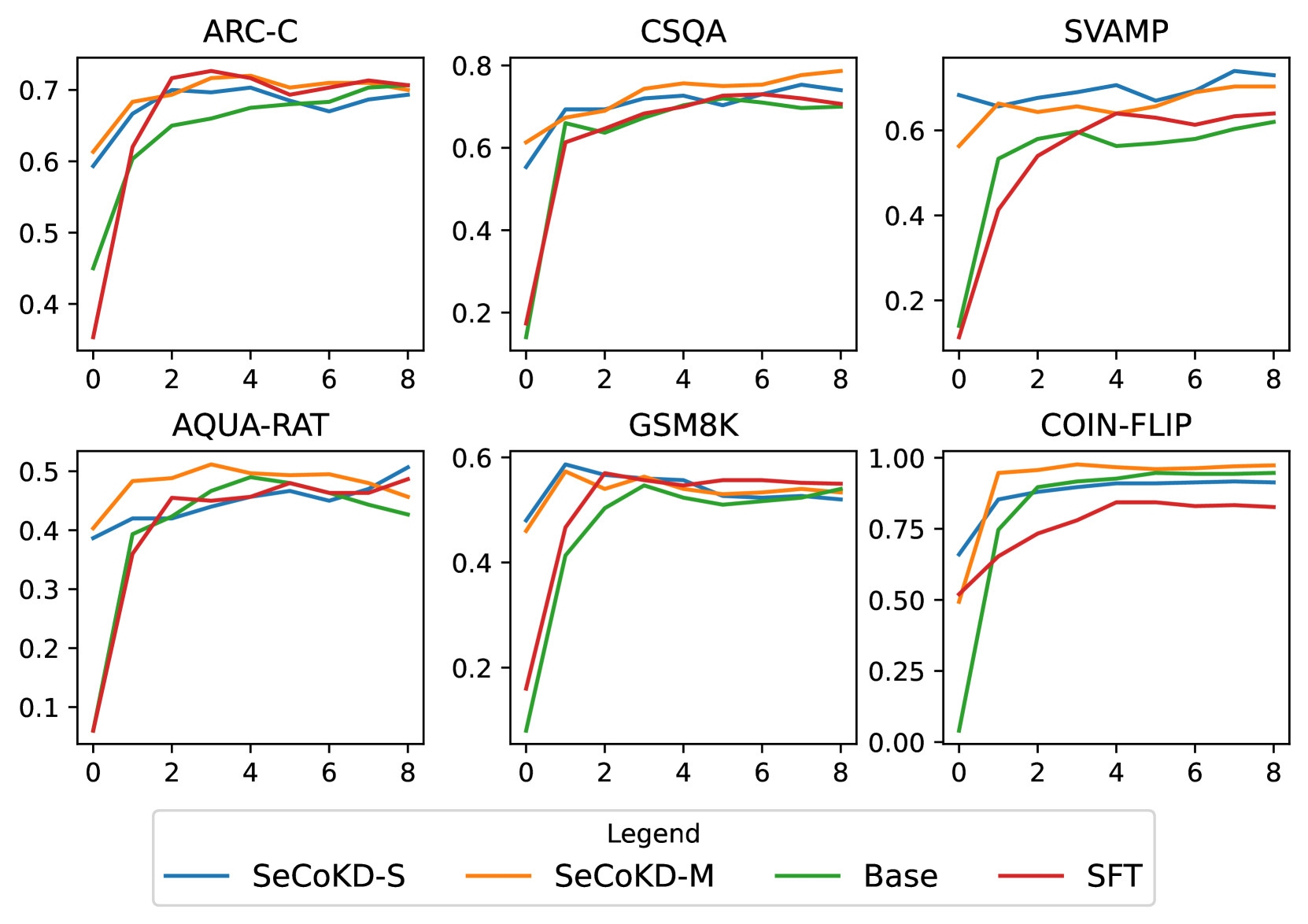
实验结果表明,SeCoKD在零样本和单样本设置下,分别比基线模型和监督微调提升了30%和10%。此外,SeCoKD在新任务上的泛化能力更强,几乎没有带来负面影响,表明其具有更好的鲁棒性。这些结果验证了SeCoKD在提升少样本上下文学习能力方面的有效性。
🎯 应用场景
SeCoKD框架可应用于各种需要利用大语言模型进行推理和决策的场景,尤其是在数据稀缺或标注成本高的领域。例如,在医疗诊断、金融风控等领域,可以利用少量专家知识构建演示示例,然后通过SeCoKD训练模型,实现高效的知识迁移和推理。
📄 摘要(原文)
Previous studies have shown that demonstrations can significantly help Large Language Models (LLMs ) perform better on the given tasks. However, this so-called In-Context Learning ( ICL ) ability is very sensitive to the presenting context, and often dozens of demonstrations are needed. In this work, we investigate if we can reduce the shot number while still maintaining a competitive performance. We present SeCoKD, a self-Knowledge Distillation ( KD ) training framework that aligns the student model with a heavily prompted variation, thereby increasing the utilization of a single demonstration. We experiment with the SeCoKD across three LLMs and six benchmarks focusing mainly on reasoning tasks. Results show that our method outperforms the base model and Supervised Fine-tuning ( SFT ), especially in zero-shot and one-shot settings by 30% and 10%, respectively. Moreover, SeCoKD brings little negative artifacts when evaluated on new tasks, which is more robust than Supervised Fine-tuning.