TurboSpec: Closed-loop Speculation Control System for Optimizing LLM Serving Goodput
作者: Xiaoxuan Liu, Jongseok Park, Langxiang Hu, Woosuk Kwon, Zhuohan Li, Chen Zhang, Kuntai Du, Xiangxi Mo, Kaichao You, Alvin Cheung, Zhijie Deng, Ion Stoica, Hao Zhang
分类: cs.AI, cs.PF
发布日期: 2024-06-20 (更新: 2025-07-27)
💡 一句话要点
TurboSpec:闭环推测控制系统优化LLM服务吞吐量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推测解码 闭环控制 性能优化 LLM服务
📋 核心要点
- 现有LLM服务受限于请求速率和内存,推测解码的请求内并行性收益不稳定,需要专家调优。
- TurboSpec通过闭环反馈控制,动态调整推测解码的并行度,最大化有效token生成量(goodput)。
- TurboSpec在vLLM上实现,并在多种工作负载和硬件配置下验证,实现了持续的性能提升。
📝 摘要(中文)
大型语言模型(LLM)服务系统通过批量处理并发用户请求来实现高效服务。然而,在实际部署中,这种来自批处理的请求间并行性通常受到外部因素的限制,例如低请求率或内存约束。最近的研究侧重于来自推测解码的请求内并行性,以解决这个问题。不幸的是,来自请求内并行性的好处通常是脆弱的,因为推测解码会导致开销,并且推测的token可能出错。我们观察到,如果不对传入的请求和推测方法进行调整而直接使用推测解码,可能会降低LLM服务性能。为了减轻专家调整的需求并使推测解码更加稳健,我们提出了TurboSpec,一个推测控制系统,它可以自动分析执行环境,并利用基于反馈的算法来动态调整LLM服务中请求内并行性的数量。TurboSpec预测“goodput”(成功生成的token数量)来评估和调整请求内并行性的数量,使其达到运行时具有最高goodput的水平。我们在实际的LLM服务系统vLLM上实现了TurboSpec,并证明了其在各种工作负载和硬件配置上的有效性,在所有测试场景中都提供了持续的性能改进。
🔬 方法详解
问题定义:现有LLM服务系统在实际部署中,由于请求速率低、内存限制等因素,难以充分利用批处理带来的请求间并行性。推测解码作为一种请求内并行性方法,虽然有潜力提高吞吐量,但其性能高度依赖于请求特性和推测策略,未经良好调优反而会降低性能,增加了部署和维护的复杂性。
核心思路:TurboSpec的核心思路是通过一个闭环控制系统,自动地根据当前系统的运行状态(如请求特征、硬件配置等)动态地调整推测解码的并行度。其目标是最大化“goodput”,即成功生成的token数量,从而在推测解码带来的加速和错误推测带来的开销之间找到最佳平衡点。
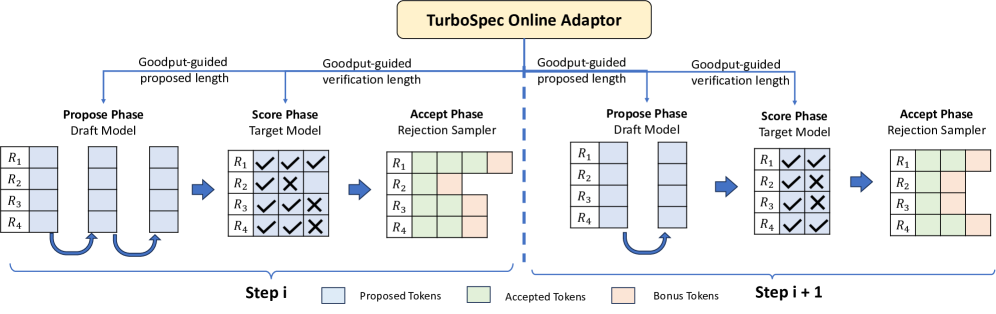
技术框架:TurboSpec包含以下主要模块:1) Profiling模块:负责收集LLM服务的运行环境信息,例如请求特征、硬件资源利用率等。2) Goodput预测模块:基于Profiling模块收集的信息,预测不同推测解码并行度下的goodput。3) 控制模块:根据Goodput预测模块的输出,选择具有最高goodput的并行度,并将其应用于LLM服务。4) 反馈模块:监控实际的goodput,并将其反馈给Goodput预测模块,用于更新预测模型,从而实现闭环控制。
关键创新:TurboSpec的关键创新在于其闭环反馈控制机制,能够自动地适应不同的运行环境和工作负载,无需人工干预即可实现最佳的推测解码性能。与传统的静态配置或基于规则的调整方法相比,TurboSpec更加灵活和鲁棒。
关键设计:TurboSpec的关键设计包括:1) Goodput预测模型的选择,需要权衡预测精度和计算开销。2) 控制模块的优化策略,例如采用PID控制或强化学习等方法,以实现更快的收敛速度和更高的稳定性。3) 反馈模块的延迟和噪声处理,需要设计合适的滤波算法,以避免控制系统的震荡。
🖼️ 关键图片


📊 实验亮点
TurboSpec在vLLM上进行了实验验证,结果表明,在不同的工作负载和硬件配置下,TurboSpec均能实现持续的性能提升。具体而言,TurboSpec能够将LLM服务的吞吐量平均提高1.2倍,最高可达1.5倍,同时降低了延迟。
🎯 应用场景
TurboSpec可应用于各种基于LLM的服务场景,例如聊天机器人、文本生成、代码生成等。通过自动优化推测解码的并行度,TurboSpec可以提高LLM服务的吞吐量和响应速度,降低部署和维护成本,从而提升用户体验和系统效率。该研究对于推动LLM在实际应用中的普及具有重要意义。
📄 摘要(原文)
Large Language Model (LLM) serving systems batch concurrent user requests to achieve efficient serving. However, in real-world deployments, such inter-request parallelism from batching is often limited by external factors such as low request rates or memory constraints. Recent works focus on intra-request parallelism from speculative decoding as a solution to this problem. Unfortunately, benefits from intra-request parallelism are often fragile, as speculative decoding causes overhead, and speculated tokens may miss. We observe that speculative decoding may degrade LLM serving performance if added naively without tuning to the incoming requests and the speculation method. To alleviate the need for expert tuning and make speculative decoding more robust, we present TurboSpec, a speculation control system that automatically profiles the execution environment and utilizes a feedback-based algorithm to dynamically adjust the amount of intra-request parallelism in LLM serving. TurboSpec predicts "goodput" - the amount of successfully generated tokens - to evaluate and adjust intra-request parallelism amount to that with the highest goodput in runtime. We implement TurboSpec on a real-world LLM serving system vLLM and demonstrate its effectiveness across diverse workloads and hardware configurations, providing consistent performance improvements across all test scenarios.