PIN: A Knowledge-Intensive Dataset for Paired and Interleaved Multimodal Documents
作者: Junjie Wang, Yuxiang Zhang, Minghao Liu, Yin Zhang, Yatai Ji, Weihao Xuan, Nie Lin, Kang Zhu, Zhiqiang Lin, Yiming Ren, Chunyang Jiang, Yiyao Yu, Zekun Wang, Tiezhen Wang, Wenhao Huang, Jie Fu, Qunshu Lin, Yujiu Yang, Ge Zhang, Ruibin Yuan, Bei Chen, Wenhu Chen
分类: cs.AI, cs.CL, cs.CV, cs.MM
发布日期: 2024-06-20 (更新: 2025-09-09)
备注: Technical report v1.0
💡 一句话要点
PIN:面向配对与交错多模态文档的知识密集型数据集,促进LMMs发展
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 文档理解 知识密集型任务 大型数据集 预训练 Markdown 视觉文本融合
📋 核心要点
- 现有大型多模态模型在处理复杂视觉数据和推理多模态关系时,存在感知和推理错误,限制了其性能。
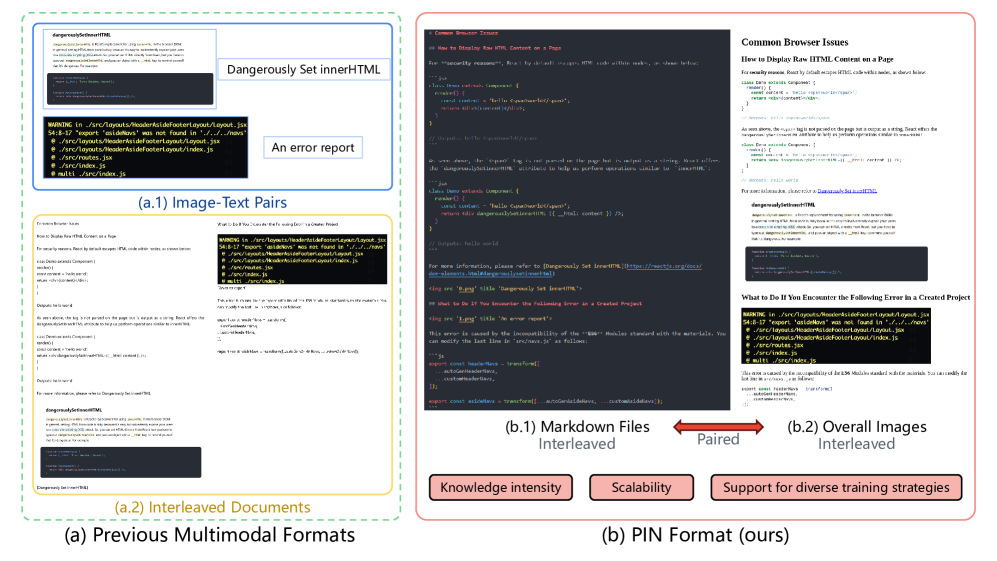
- 论文提出PIN数据格式,结合语义丰富的Markdown文件和整体文档图像,以促进视觉和文本知识的深度集成。
- 构建并发布了PIN-200M和PIN-14M两个大规模开源数据集,包含英语和中文,并提供质量信号方便数据选择。
📝 摘要(中文)
大型多模态模型(LMMs)的最新进展利用了广泛的多模态数据集来增强其在复杂知识驱动任务中的能力。然而,感知和推理错误仍然是挑战,限制了它们的效果,尤其是在解释复杂的视觉数据和推断多模态关系方面。为了解决这些问题,我们引入了PIN(配对和交错多模态文档),这是一种新颖的数据格式,旨在促进视觉和文本知识的更深层次的集成。PIN格式独特地结合了语义丰富的Markdown文件(保留了细粒度的文本结构)和整体图像(捕获了完整的文档布局)。遵循这种格式,我们构建并发布了两个大规模的开源数据集:PIN-200M(约2亿个文档)和PIN-14M(约1400万个文档),它们来自各种Web和科学来源,包含英语和中文。为了最大限度地提高可用性,我们提供了详细的统计分析,并为数据集配备了质量信号,使研究人员能够轻松地过滤和选择用于特定任务的数据。我们的工作为社区提供了一种通用的数据格式和大量的资源,为预训练策略的新研究和更强大的知识密集型LMM的开发奠定了基础。
🔬 方法详解
问题定义:现有的大型多模态模型在知识密集型任务中表现出潜力,但其感知和推理能力仍有不足,尤其是在处理复杂文档时,难以有效利用文档的视觉布局和细粒度文本结构。现有数据集往往缺乏对文档结构和语义的细致表示,限制了模型学习文档内在知识的能力。
核心思路:论文的核心思路是设计一种新的数据格式PIN,将文档的整体视觉信息(图像)和细粒度的文本信息(Markdown)相结合。Markdown格式能够保留文档的结构化信息,如标题、列表、表格等,而图像则提供了文档的整体布局信息。通过这种方式,模型可以同时学习文档的视觉和文本特征,从而更好地理解文档的内容。
技术框架:PIN数据格式包含两个主要组成部分:文档的整体图像和对应的Markdown文件。数据集构建流程包括从网络和科学文献中收集文档,将文档转换为Markdown格式,并生成文档的整体图像。此外,论文还提供了数据集的统计分析和质量信号,方便用户根据特定任务选择合适的数据。数据集包含PIN-200M和PIN-14M两个版本,分别包含约2亿和1400万个文档。
关键创新:PIN数据格式的关键创新在于其将文档的视觉信息和结构化文本信息相结合。与传统的纯文本或纯图像数据集相比,PIN格式能够提供更丰富的文档信息,从而促进模型学习文档的内在知识。此外,PIN数据集的规模也远大于现有的同类数据集,为训练大型多模态模型提供了充足的数据。
关键设计:PIN数据集的关键设计包括:1) 使用Markdown格式来表示文档的结构化文本信息;2) 提供文档的整体图像,以便模型学习文档的视觉布局;3) 提供数据集的统计分析和质量信号,方便用户选择数据;4) 构建大规模数据集,以支持训练大型多模态模型。具体参数设置和损失函数等技术细节未在摘要中提及,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文构建了PIN-200M和PIN-14M两个大规模开源数据集,包含约2亿和1400万个文档,涵盖英语和中文。数据集提供了详细的统计分析和质量信号,方便研究人员选择数据。具体实验结果和性能提升未在摘要中提及,属于未知信息。
🎯 应用场景
PIN数据集可用于预训练大型多模态模型,提升其在文档理解、信息抽取、问答等任务中的性能。该数据集的应用前景广阔,可应用于智能文档处理、知识图谱构建、智能搜索等领域,有望推动人工智能在信息管理和知识服务方面的进步。
📄 摘要(原文)
Recent advancements in large multimodal models (LMMs) have leveraged extensive multimodal datasets to enhance capabilities in complex knowledge-driven tasks. However, persistent challenges in perceptual and reasoning errors limit their efficacy, particularly in interpreting intricate visual data and deducing multimodal relationships. To address these issues, we introduce PIN (Paired and INterleaved multimodal documents), a novel data format designed to foster a deeper integration of visual and textual knowledge. The PIN format uniquely combines semantically rich Markdown files, which preserve fine-grained textual structures, with holistic overall images that capture the complete document layout. Following this format, we construct and release two large-scale, open-source datasets: PIN-200M (~200 million documents) and PIN-14M (~14 million), compiled from diverse web and scientific sources in both English and Chinese. To maximize usability, we provide detailed statistical analyses and equip the datasets with quality signals, enabling researchers to easily filter and select data for specific tasks. Our work provides the community with a versatile data format and substantial resources, offering a foundation for new research in pre-training strategies and the development of more powerful knowledge-intensive LMMs.