StackRAG Agent: Improving Developer Answers with Retrieval-Augmented Generation
作者: Davit Abrahamyan, Fatemeh H. Fard
分类: cs.AI, cs.CL
发布日期: 2024-06-19
💡 一句话要点
提出StackRAG Agent,利用检索增强生成提升开发者问答质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大型语言模型 Stack Overflow 多Agent系统 开发者问答
📋 核心要点
- 开发者在解决问题时面临信息检索的挑战,现有方法要么耗时,要么依赖不可靠的LLM。
- StackRAG的核心思想是结合Stack Overflow的知识和LLM的生成能力,通过检索增强来提高答案的可靠性。
- 初步评估表明,StackRAG生成的答案在正确性、准确性、相关性和实用性方面均表现良好。
📝 摘要(中文)
开发者花费大量时间寻找与其问题相关的信息。Stack Overflow一直是主要资源,随着大型语言模型(LLM)的出现,ChatGPT等生成模型也被频繁使用。然而,单独使用它们各有缺点。搜索答案既耗时又繁琐,研究人员开发了许多工具来解决这个问题。另一方面,使用LLM并不可靠,因为它们可能会产生不相关或不可靠的答案(即幻觉)。在这项工作中,我们提出了一种基于LLM的检索增强多Agent生成工具StackRAG,它结合了这两个世界的优点:聚合来自SO的知识,以提高生成答案的可靠性。初步评估表明,生成的答案是正确的、准确的、相关的和有用的。
🔬 方法详解
问题定义:开发者在解决编程问题时,需要花费大量时间在Stack Overflow等社区搜索答案。直接使用大型语言模型(LLM)虽然方便,但存在产生幻觉、提供不准确或不相关答案的风险。现有方法难以兼顾效率和准确性,无法有效解决开发者面临的信息检索难题。
核心思路:StackRAG的核心思路是利用检索增强生成(RAG)技术,将Stack Overflow的知识融入到LLM的生成过程中。通过首先检索与问题相关的Stack Overflow帖子,然后将检索到的信息作为上下文提供给LLM,从而引导LLM生成更准确、更可靠的答案。这种方法旨在结合信息检索的准确性和LLM的生成能力,克服各自的局限性。
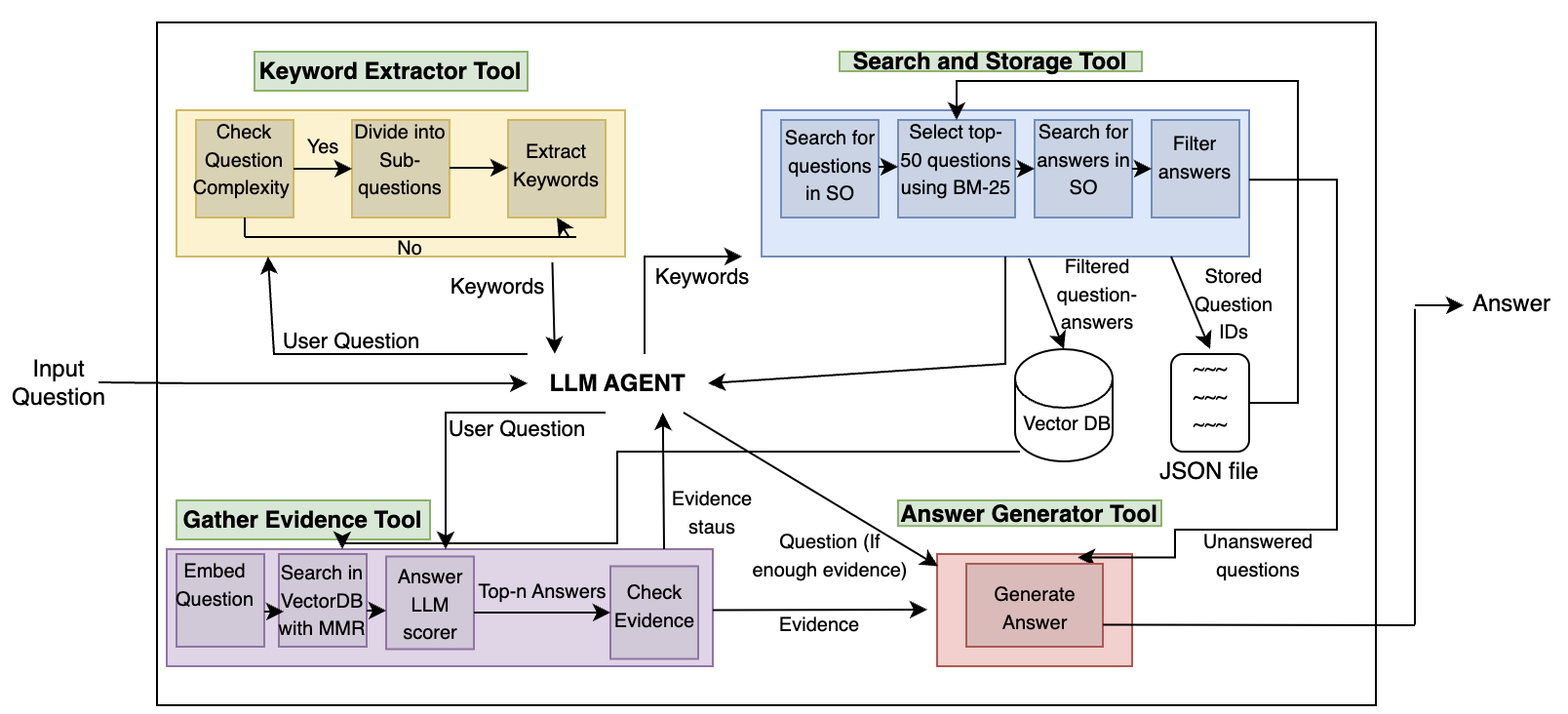
技术框架:StackRAG采用多Agent架构,包含以下主要模块:1) 问题理解模块:分析开发者的问题,提取关键信息。2) 信息检索模块:使用问题理解模块提取的信息,在Stack Overflow上检索相关帖子。3) 上下文构建模块:将检索到的帖子进行整理和过滤,构建LLM的上下文。4) 答案生成模块:利用LLM,基于构建的上下文生成答案。5) 答案评估模块:评估生成答案的质量,并进行必要的修正。
关键创新:StackRAG的关键创新在于其多Agent架构和检索增强策略。与传统的LLM直接生成答案的方法相比,StackRAG通过检索Stack Overflow的知识,显著提高了答案的准确性和可靠性。此外,多Agent架构使得系统能够更有效地处理复杂的问题,并提供更全面的解决方案。
关键设计:StackRAG的具体技术细节包括:1) 使用预训练的Transformer模型进行问题理解和信息检索。2) 采用余弦相似度等方法衡量问题与Stack Overflow帖子之间的相关性。3) 使用LLM(具体模型未知)进行答案生成,并采用适当的提示工程(Prompt Engineering)来引导LLM生成高质量的答案。4) 答案评估模块的具体实现细节未知。
🖼️ 关键图片
📊 实验亮点
论文的初步评估表明,StackRAG生成的答案在正确性、准确性、相关性和实用性方面均表现良好。虽然论文中没有提供具体的性能数据和对比基线,但作者强调StackRAG能够有效提高生成答案的可靠性,克服LLM的幻觉问题。更详细的实验结果(例如与ChatGPT等基线的对比)将有助于进一步验证StackRAG的有效性。
🎯 应用场景
StackRAG可应用于各种软件开发场景,例如代码调试、API使用、技术选型等。它可以作为IDE插件、在线问答平台或开发助手,帮助开发者快速找到准确、可靠的答案,提高开发效率。未来,StackRAG可以扩展到其他技术社区和知识库,为更广泛的开发者群体提供支持。
📄 摘要(原文)
Developers spend much time finding information that is relevant to their questions. Stack Overflow has been the leading resource, and with the advent of Large Language Models (LLMs), generative models such as ChatGPT are used frequently. However, there is a catch in using each one separately. Searching for answers is time-consuming and tedious, as shown by the many tools developed by researchers to address this issue. On the other, using LLMs is not reliable, as they might produce irrelevant or unreliable answers (i.e., hallucination). In this work, we present StackRAG, a retrieval-augmented Multiagent generation tool based on LLMs that combines the two worlds: aggregating the knowledge from SO to enhance the reliability of the generated answers. Initial evaluations show that the generated answers are correct, accurate, relevant, and useful.