Converging Dimensions: Information Extraction and Summarization through Multisource, Multimodal, and Multilingual Fusion
作者: Pranav Janjani, Mayank Palan, Sarvesh Shirude, Ninad Shegokar, Sunny Kumar, Faruk Kazi
分类: cs.AI, cs.IR
发布日期: 2024-06-19
备注: 11 pages, 3 figures
💡 一句话要点
提出一种多源、多模态、多语言融合的信息抽取与摘要方法,克服现有方法依赖单一数据源的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多源信息融合 多模态学习 多语言处理 信息抽取 文本摘要
📋 核心要点
- 现有摘要方法依赖单一数据源,导致信息量受限、主题覆盖范围窄,并可能引入虚假内容,对多语言和多模态数据支持不足。
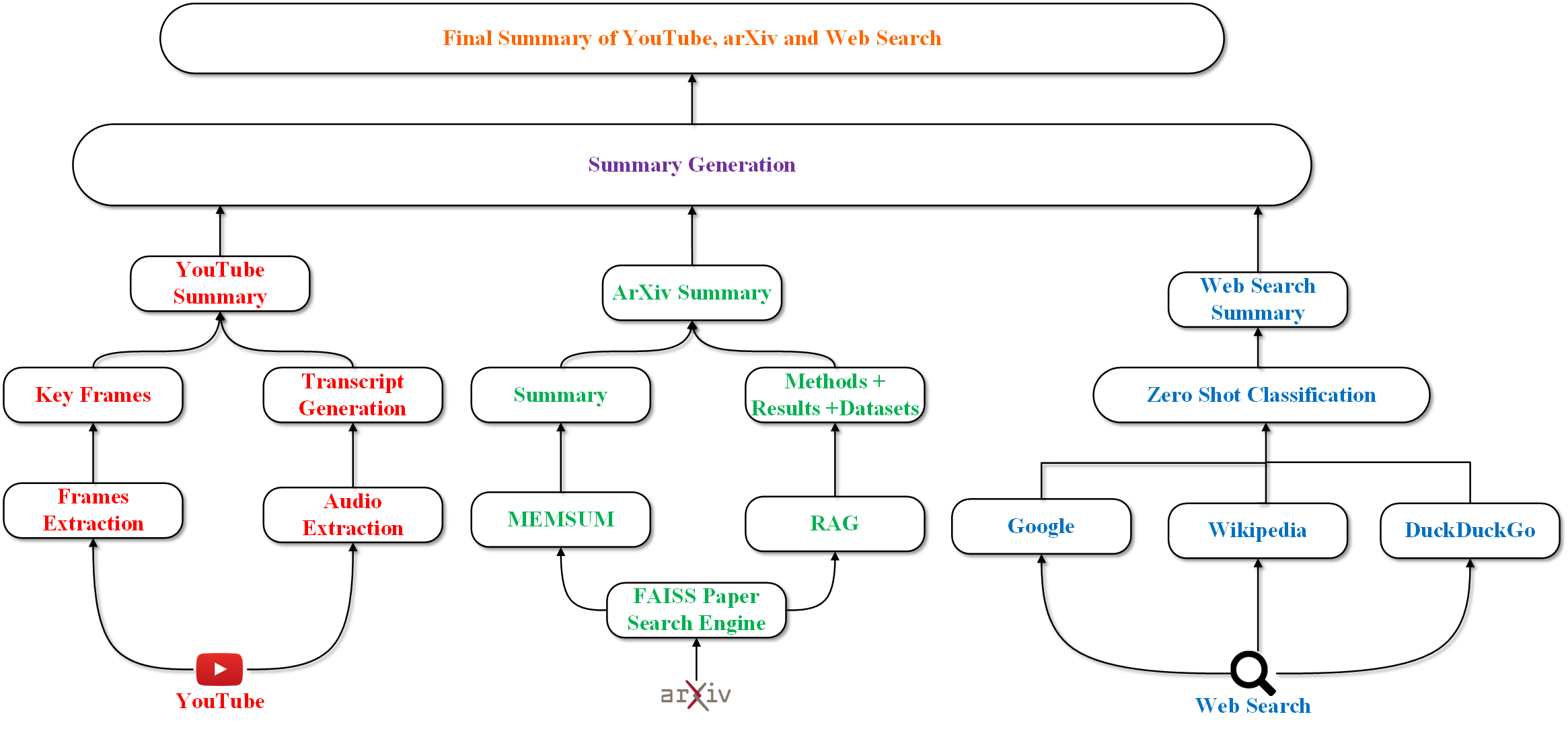
- 该方法的核心在于融合多源(如YouTube、预印本、维基百科)异构数据,将其转化为统一的文本表示,实现更全面的信息分析。
- 该方法旨在最大化信息增益,最小化信息重叠,并保持摘要的高信息量和连贯性,从而生成更优质的摘要。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展催生了新的摘要策略,为提取重要信息提供了广泛的工具包。然而,这些方法经常受到其对孤立数据源依赖的限制。可收集的信息量受到限制,并且涵盖的主题范围较小,这引入了伪造内容的可能性,并且对多语言和多模态数据的支持有限。本文提出了一种新颖的摘要方法,通过利用多个来源的优势来提供对复杂主题更详尽和信息丰富的理解,从而应对这些挑战。该研究超越了传统的单模态来源(如文本文档),并整合了更多样化的数据,包括YouTube播放列表、预印本和维基百科页面。然后,将上述各种来源转换为统一的文本表示,从而实现更全面的分析。这种多方面的摘要生成方法使我们能够从更广泛的来源中提取相关信息。该方法的主要原则是最大化信息增益,同时最小化信息重叠,并保持高水平的信息量,从而鼓励生成高度连贯的摘要。
🔬 方法详解
问题定义:现有摘要方法主要依赖于单一文本数据源,例如新闻文章或研究论文。这种局限性导致信息覆盖面窄,无法充分理解复杂主题。此外,对多语言和多模态数据的支持不足,限制了摘要系统的应用范围。现有方法容易受到数据偏见和虚假信息的影响,难以保证摘要的客观性和准确性。
核心思路:本文的核心思路是利用多源、多模态、多语言数据融合,构建更全面、更准确的摘要。通过整合来自不同来源的信息,可以减少信息偏差,提高摘要的可靠性。将视频、文本等多种模态的数据进行统一表示,可以更深入地理解主题。支持多语言数据,可以扩大摘要系统的应用范围。
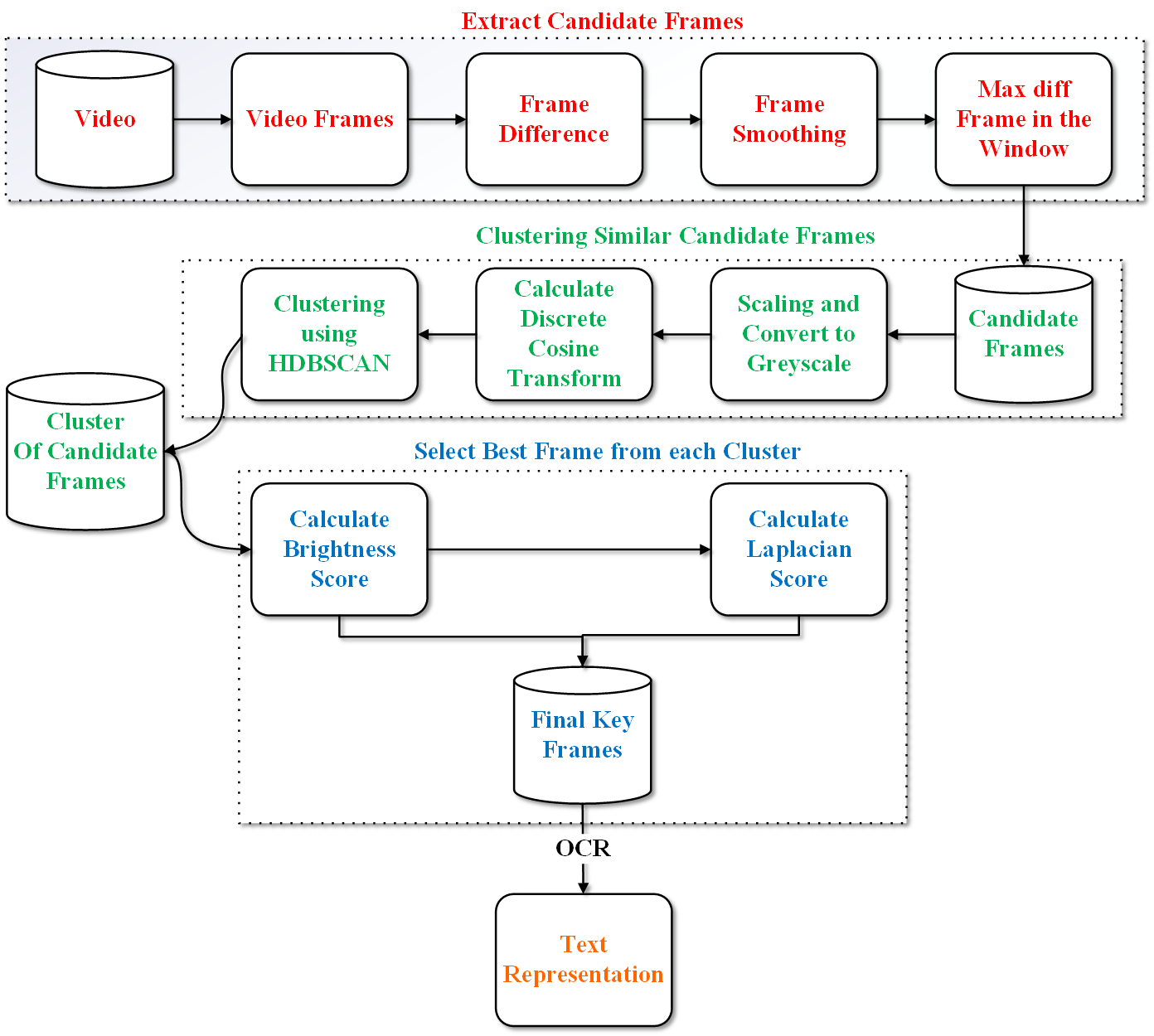
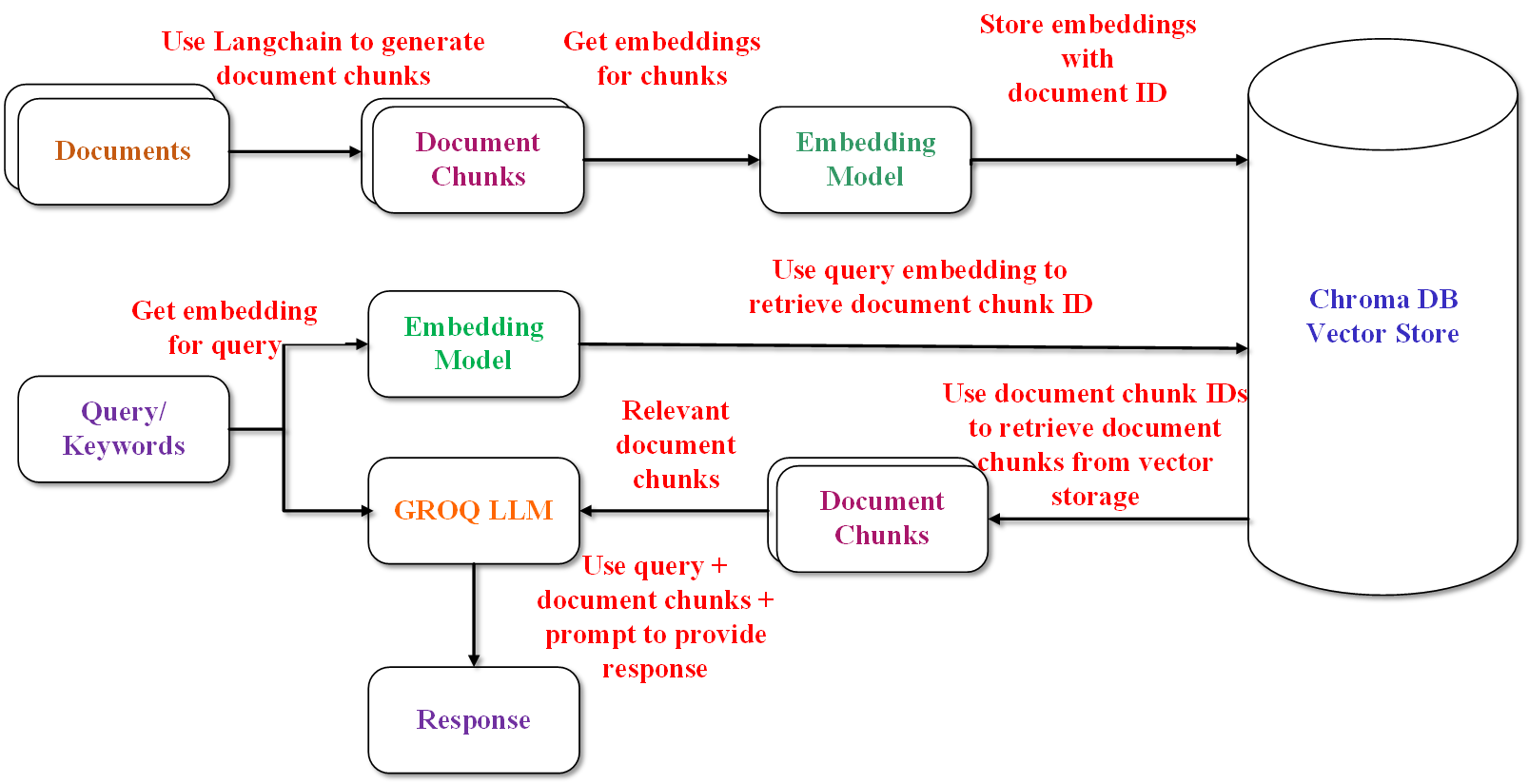
技术框架:该方法的技术框架主要包括以下几个阶段:1) 数据采集:从多个来源(如YouTube播放列表、预印本、维基百科页面)采集数据。2) 数据预处理:对采集到的数据进行清洗、转换和标准化处理。3) 多模态融合:将不同模态的数据(如文本、视频)转换为统一的文本表示。4) 信息抽取:从统一的文本表示中提取关键信息。5) 摘要生成:利用大型语言模型生成摘要。
关键创新:该方法最重要的技术创新点在于多源、多模态、多语言数据的融合。通过将来自不同来源、不同模态、不同语言的数据进行整合,可以构建更全面、更准确的摘要。此外,该方法还提出了一种新的信息抽取和摘要生成策略,旨在最大化信息增益,最小化信息重叠。
关键设计:论文中没有详细描述关键参数设置、损失函数、网络结构等技术细节。这些细节可能取决于具体的数据集和任务。但是,可以推断,在多模态融合阶段,可能需要设计特定的网络结构或损失函数,以有效地将不同模态的数据进行整合。在摘要生成阶段,可能需要使用强化学习等技术,以优化摘要的质量和连贯性。
🖼️ 关键图片
📊 实验亮点
由于摘要中没有提供具体的实验结果,因此无法总结实验亮点。但是,可以推断,该研究可能通过与现有的单源摘要方法进行对比,证明其在信息覆盖面、摘要质量和客观性方面的优势。未来的研究可以关注如何量化多源信息融合带来的性能提升。
🎯 应用场景
该研究成果可应用于多个领域,如新闻摘要、科研综述、产品评论分析等。通过整合多源信息,可以为用户提供更全面、客观的摘要,帮助用户快速了解复杂主题。该方法还可用于构建多语言摘要系统,促进跨语言的信息交流。未来,该方法有望应用于智能客服、舆情分析等领域,提升信息处理效率和质量。
📄 摘要(原文)
Recent advances in large language models (LLMs) have led to new summarization strategies, offering an extensive toolkit for extracting important information. However, these approaches are frequently limited by their reliance on isolated sources of data. The amount of information that can be gathered is limited and covers a smaller range of themes, which introduces the possibility of falsified content and limited support for multilingual and multimodal data. The paper proposes a novel approach to summarization that tackles such challenges by utilizing the strength of multiple sources to deliver a more exhaustive and informative understanding of intricate topics. The research progresses beyond conventional, unimodal sources such as text documents and integrates a more diverse range of data, including YouTube playlists, pre-prints, and Wikipedia pages. The aforementioned varied sources are then converted into a unified textual representation, enabling a more holistic analysis. This multifaceted approach to summary generation empowers us to extract pertinent information from a wider array of sources. The primary tenet of this approach is to maximize information gain while minimizing information overlap and maintaining a high level of informativeness, which encourages the generation of highly coherent summaries.